

-
需补充扩展知识
 查看全部
查看全部 -
如果需要处理 PDF,更推荐使用纯 Python 库(跨平台、无需依赖外部软件):
PyPDF2/PyPDF4:合并、拆分、提取文本、添加水印等基础操作。
pdfplumber:更精准的文本提取(支持复杂排版)。
PyMuPDF(fitz):高效的文本提取、页面操作、转换格式等。
reportlab:生成 PDF 文档(从空白页创建内容)。
综上,win32com 可以间接操控 PDF 软件,但并非处理 PDF 的最优选择,纯 Python 库通常更轻便、高效。
编辑分享
给PDF添加水印的具体操作步骤
如何将PDF转换为Word格式?
怎样使用win32com提取PDF中的图片?
查看全部 -

基础层 采集层 数据处理层 应用层
基础层:基础信息采集;采集层:数据结构搭建,数据模型搭建;处理层:数据清洗,标准化数据格式;应用层:数据分析结论输出,深度挖掘;
查看全部 -
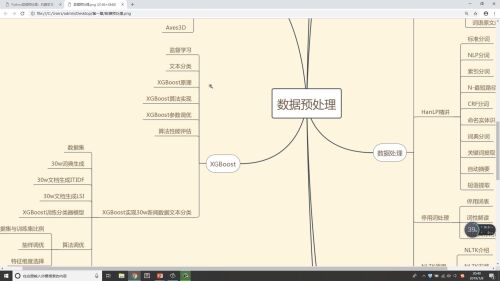
数据预处理:
数据集成
数据清洗
数据处理
数据变换
数据归纳
可视化技术
XGBoost--实现30W数据文本分析
查看全部 -

文件操作方法
查看全部 -
网络爬虫,有时间学习下查看全部 -

课程思维导图
查看全部 -

开发环境说明
查看全部 -
30万条数据分析
训练分类器
算法调优
查看全部 -


数据预处理流程
数据清理
数据集成
数据变换
数据归约
查看全部 -

数据处理往往比算法模型和调参带来的效果更好
文本信息处理,稍作改动也支持图片和语音
查看全部 -


什么是数据预处理
查看全部 -
遍历读取文件
算法思路:
·遍历文件的类TraversalFun:TraversalDir、AllFiles
·遍历目录文件TRaversalDir:AllFiles(self.rootDir)
·递归遍历文件AllFiles(self,rootDir)
·判断是否为文件isfile:打印出文件名
·判断是否是目录isdir:递归遍历
查看全部 -
算法思路:
·定义文件路径和转存路径:split
·修改新的文件名:TranType(filename,typename)、fnmatch
·设置完整的保存路径:join
·启动应用程序格式转换:Dispatch
·保存文本:SaveAs
查看全部 -
PDF转TXT的算法实现
算法思路:
·定义文件路径和转存路径:split
·修改新的文件名:fnmatch
·设置完整的保存路径:join
·启动应用程序格式转换:Dispatch
·保存文本:SaveAs
查看全部






举报