

-
起源
时间:20世纪中叶
实际上是一种仿生学产品
兴起
环境:2进制创新
能力:软硬件
需求:人的性价比
查看全部 -
分类:图像、语音(密集型矩阵)
文本(稀疏性矩阵)
查看全部 -
训练学习:
网络结构 激励函数 损失函数 梯度下降
查看全部 -
神经网络:
图像-》自动驾驶
语音-》语音助手
文本-》新闻推送
查看全部 -
激励函数图
 查看全部
查看全部 -
训练学习
网络结构 激励函数
损失函数 梯度下降
查看全部 -
鱼查看全部
-
网络结构
激励函数
损失函数
梯度下降
查看全部 -
:=
同步更新 W 和b
查看全部 -
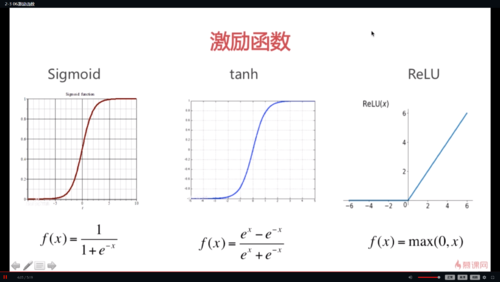
Sigmoid函数:f(x)=1/[1+e^(-x)] //在进行1或0的判断时使用,在整个区间段都是可导的;
tanh函数:f(x)=[e^x-e^(-x)]/[e^x+e^(-x)] // 在标注不好的情况下可尝试使用;
ReLU函数:f(x)=max(0,x) // 默认函数
查看全部 -
Sigmoid函数:f(x)=1/[1+e^(-x)] //在整个区间段都是可导的;
tanh函数:f(x)=[e^x-e^(-x)]/[e^x+e^(-x)]
ReLU函数:f(x)=max(0,x) // 默认函数
查看全部 -
f(x)=1/[1+e^(-x)] //在整个区间段都是可导的
查看全部 -
三种激励函数:
1,Sigmoid函数,当x趋向于负无穷时,函数趋向于0;当x趋向于正无穷时,函数趋向于1.
优点是:在整个区间上是可导的。
缺点是:不是以原点对称的,对称点是(0,0.5)。使用其做完函数计算后,
经常需要再做一步数据中心化。
2,tanh函数
激励函数是对大脑中传递介质的模拟,非线性的变化
Sigmoid tanh ReLU
2.1sigmoid (0-1)优势:整个函数可导,后期反向传播
缺点:对称点:0.50(数据中心化)-》tanh
趋向比较小或比较大时,变化平缓
2.2ReLU
激励函数:
作用:提供规模化的非线性能力
包括:Sigmoid、tanh、ReLU等
Sigmoid函数适用于结果为判断是非的场合,但由于其对称中心在(0, 0.5),还需要进行数据中心化,由此提出了其改进函数tanh
Sigmiod和tanh的缺点是当数值很大或很小时,结果变化比较平缓,由此提出了ReLU函数,
激励函数的作用是提供规模化的非线性化能力,模拟神经元被激发后非线性状态的变化。
Sigmoid:区间[0,1]
优点:整个区间段可导。
缺点:不是原点中心对称,对称点(0,0.5)-->数据中心化(0,0)
tanh:区间[-1,1]
优点:sigmoid函数平移后得到,中心对称。
查看全部 -
激励函数:Sigmoid, tanh, ReLU
查看全部 -
分类识别(图片就是一个像素的矩阵):图像是稀疏型矩阵、语音和文本是密集型矩阵,图像和语音中的点大部分为非零值,而文本可能是零值居多,所以文本还有一些预处理要做。
每一个节点(神经元)的处理包括:
(1)将输入x进行线性组合;
(2)将线性组合的结果通过激活函数g(z)转化为非线性的结果,以处理非线性问题
网络结构
激励函数
损失函数
梯度下降
查看全部








举报