

-
输入单个节点的处理也可以有一个预测输出,通过选定损失函数对预测结果进行评估,并进行反向学习进一步修改线性组合的参数W和b
查看全部 -
逻辑回归是一种最简化的网络结构
查看全部 -
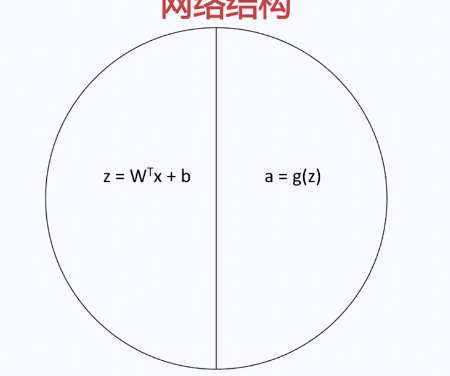
神经网络比普通的函数具有结构性的顺序——网络结构
深层网络比浅层网络的所需结点数要少,而且理解力会更强
线性结构可以解决线性问题,非线性就可以解决非线性问题
神经元结构
 查看全部
查看全部 -
课程安排1
查看全部 -
图像、语音:密集型矩阵,非零值
文本:稀疏型矩阵,零值居多,需要预处理
查看全部 -
神经网络
起源:
20世纪中叶
查看全部 -
神经网络的主要组件
查看全部 -
梯度下降同步更新神经元线性部分的参数W和b,J(W,b)为损失函数
查看全部 -
正向传播-->网络向量化
反向传播-->网络梯度下降
对a^n求导,输出dW^n、db^n、dz^n,得到da^n-1
y-->a^n-->a^n-1-->……-->a(x层不需要调教)
训练过程:正向传播计算损失-->反向传播更新参数-->反复以上步骤
注意:传播按层进行,中间没有交叉,所有层全部算好后再一次性更新参数
查看全部 -
梯度下降是通过一种渐进性的方式来调整函数的形态(W,b),使学习结果与实际结果一致。
通过正向运算得到y^,此时W、b是初始值,y^与真实y值有差异,通过损失函数反向调整参数W、b。用损失函数分别对W、b求导,同步更新W、b,使在损失函数变化方向上渐进减小直到Global Minimum(全局最小值),此时W、b趋向于稳定。如果损失函数趋近于全局最小值,则预测y值与真实y值差异最小。
查看全部 -
损失函数判断学习产生的函数值和训练集给出的函数值之间的差异性。
不使用欧几里得距离(预测值与真实值做差)而使用log函数是因为,通过激励函数学习出的平面并不是凸函数平面,在后期做梯度下降(与是否是凸函数有关)时有多个局部极小值时,学习结果不准确。
-->使用log变成凸函数。
查看全部 -
激励函数的作用是提供规模化的非线性化能力,模拟神经元被激发后非线性状态的变化。
Sigmoid:区间[0,1]
优点:整个区间段可导。
缺点:不是原点中心对称,对称点(0,0.5)-->数据中心化(0,0)
tanh:区间[-1,1]
优点:sigmoid函数平移后得到,中心对称。
缺点:趋向于较大或较小时,导数为0,函数变化平缓,神经网络学习效率受影响,学习周期变长。
ReLU(较为普遍):
缺点:小于0时,导数为0,出现问题-->可改为斜率较小的斜线
查看全部 -
图像、语音:密集型矩阵,非零值
文本:稀疏型矩阵,零值居多,需要预处理
查看全部 -
权重 偏置值查看全部
-
:= 同步更新
查看全部






举报