

-
111111111
查看全部 -
1111111111111111
查看全部 -
111111111111
查看全部 -
爬虫就是自动访问互联网 并且提取数据的程序
查看全部 -
1111111111
查看全部 -
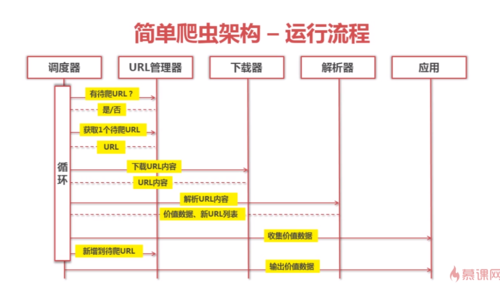
URL管理器
查看全部 -
简单爬虫架构 - 运行流程
查看全部 -
简单的爬虫架构
查看全部 -
做个截图吧!
 查看全部
查看全部 -
调度器:管理器,解析器,下载器,输出器查看全部
-
from baike_spider import html_downloader, html_outputer, url_manager
from lxml.html import html_parser
from astropy.units import countclass SpiderMain(object):
"""爬虫总调度程序,会使用HTML的下载器,解析器,输出器来完成功能"""
def __init__(self):
"""在构造函数中初始化所需要的各个对象"""
self.urls = url_manager.UrlManager() #URL管理器
self.downloader = html_downloader.HtmlDownloader() #URL下载器
self.parser = html_parser.HtmlParser() #URL解析器
self.output = html_outputer.HtmlOutputer() #URL输出器
def craw(self,root_url):
"""爬虫的调度程序,root_url就是入口url,将其添加到URL管理器"""
count = 1
self.urls.add_new_url(root_url) #添加一个新的未爬取的URL
while self.urls.has_new_url():
try:
"""设置一个异常处理,用来处理网页中已经失效的URL和空的URL"""
new_url = self.urls.get_new_url() #获取一个待爬取的URL
print("crow %d: %s"%(count,new_url))
html_cont = self.downloader.download(new_url) #下载URL页面
new_urls, new_data =self.parser.parse(new_url,html_cont)
#调用解析器解析页面数据,得到新的URL列表和新的数据,传入两个参数,传入该URL,和下载的数据
self.urls.add_new_urls(new_urls) #新的URL列表补充到URLS
self.output.collect_data(new_data) #收集数据
if count == 100:
"""设置一个循环控制URL的爬取个数"""
break
count += 1
except:
print("craw failed")
self.outputer.output_html()if __name__ == '__main__':
root_url = "http://baike.baidu.com/view/21087.html" #爬虫入口URL
obj_spider = SpiderMain() #调用主函数
obj_spider.craw(root_url) #启动爬虫查看全部 -
what爬虫是什么? How good学习爬虫有什么好处?查看全部
-
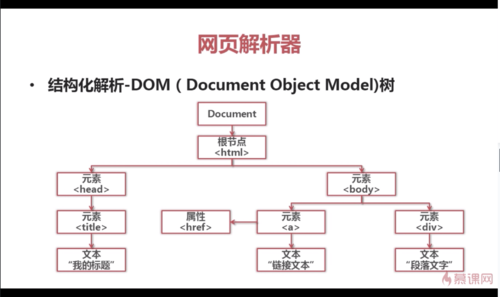
网页解析器:从网页中提取有价值数据的工具
python的网页解析器:正则表达式; html.parser; Beautiful Soup; lxml
 查看全部
查看全部







举报