

-
url管理器:添加新的待爬取URL
判断待添加是否已经存在容器中
获取待爬取URL
爬取完放入已爬取URL集合中
判断有无待爬取
查看全部 -
架构:在爬虫调度端启动爬虫、监视爬虫运行情况。
URL管理器:对已经爬虫的URL和将要爬虫的URL进行管理。将待爬取url传送给网页下载器进行下载,变成数组给网页解析器,,解析出价值数据,其他网页URL补充进URL管理器
查看全部 -
架构
URL管理器
网页下载器
网页解析器
查看全部 -
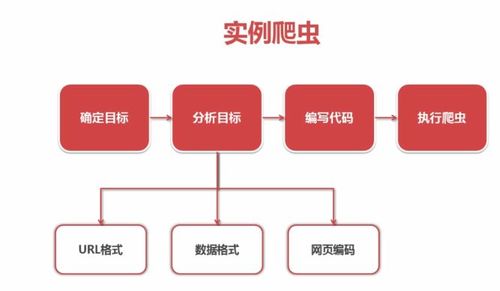
抓取百度百科的内容:
1、确定目标;
2、分析目标;①分析URL格式,限定抓取的范围
②分析数据格式:每一个词条页面中,标题和简介这两数据所代表的标签格式
③分析网页编码
3、编写代码
4、执行爬虫
查看全部 -
使用BeautifulSoup来解析网页文档字符串然后来进行各种搜索以及节点访问的各种方法
查看全部 -
第三步,在得到节点后:可以使用
node.name获取节点标签名称
node['href']获取节点a的href属性
node.get_text() 获取节点a的链接文字
查看全部 -
第二部用find_all方法来搜索节点,可以在参数中传入正则表达式
查看全部 -
如何创建BeautifulSoup对象:需要传入3个属性:(字符串,解析器,文档编码)
查看全部 -
搜索节点可以根据节点的:名称、节点的属性、节点的内容来搜索。
查看全部 -
安装,,,,,
查看全部 -
开发爬虫的步骤:
 查看全部
查看全部 -
#urllib2下载网页的方法1 # -*- coding: utf-8 -*- import urllib2 #请求网页 response = urllib2.urlopen("http://www.baidu.com") print response.getcode() print response.read() #urllib2下载网页的方法2 import urllib2 #创建Request对象 request=urllib2.Request(url) #添加数据 request.add_data('a','1') #添加http的header request.add_header('User-Agent','Mozilla/5.0') #发送请求获取结果 response = urllib2.urlopen(request) #urllib2下载网页的方法3 import urllib2, cookielib #创建cookie容器 cj = cookielib.CookieJar() #创建1个opener opener = urllib2.build_opener(urllib2.HttpCookieProcessor(cj)) #给urllib2安装opener urllib2.install_opener(opener) #使用带有cookie的urllib2访问网页 response = urllib2.urlopen("http://www.baidu.com/")查看全部 -
# coding:utf8 import urllib.request from http import cookiejar url = "http://www.baidu.com" print("第一种方法") response1 = urllib.request.urlopen(url) print(response1.getcode()) print(len(response1.read())) print("第二种方法:伪装成浏览器") request=urllib.request.Request(url) request.add_header("user-agent","Mozilla/5.0") response2=urllib.request.urlopen(request) print(response2.getcode()) print (len(response2.read())) print("第三种方法:cookie") cj=cookiejar.CookieJar() opener=urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) urllib.request.install_opener(opener) response3=urllib.request.urlopen(url) print(response3.getcode()) print(cj) print() print(response3.read())查看全部 -
urllib2下载网页方法3:添加特殊场景的处理器
HTTPCookerProcessor:需要用户登录才能访问,需要添加cooker处理
ProxyHandler:需要代理才能访问
HTTPSHandler:使用协议加密访问
HTTPRedirectHandler:url自动的跳转
查看全部 -
urllib2下载网页方法2:添加data,http header
import urllib2 #创建Request对象 request = urllib2.Request(url) #添加数据 request.add_dsata('a','1') #添加http的header request.add_header('User-Agent','Mozilla/5.0') #发送请求获取结果 response = urllib2.urlopen(request)查看全部





举报