

-
HTML下载器 html_downloader
查看全部 -
# class
```py
class UrlManage(object):
def __init__(self):
self.new_urls = set();
self.old_urls = set();
def add_new_url(self, url):
# todo
def has_new_url(self,):
return len(self.new_urls) != 0
def add_new_url(self):
new_url = self.new_urls.pop()
seft.old_urls.add(new_url)
return new_url
```
查看全部 -
# 初始化 class
```py
class UrlManage(object):
def __init__(self):
self.new_urls = set();
self.old_urls = set();
def add_new_url(self, url):
# todo
```
查看全部 -
URL 管理器
查看全部 -
# Python 2.x
```py
count =1
new_url = 'https://cdn.xgqfrms.xyz/'
print 'craw %d : %s' % (count, new_url)
```
# Python 3.x
```py
count =1
new_url = 'https://cdn.xgqfrms.xyz/'
print('craw', count, new_url)
```
查看全部 -
Ctrl + 1 快速创建 class下对应的方法
查看全部 -
class 构造函数 __init__ 初始化
import module
查看全部 -
查看全部
-
Python 爬虫实战
查看全部 -
python网页解析器
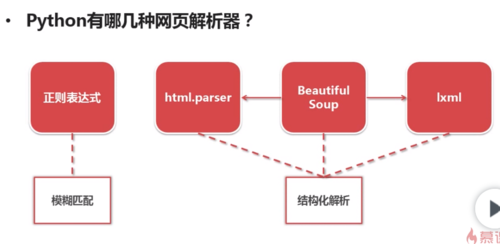 查看全部
查看全部 -
需要登录的网页 java script 异步加载的网页 静态网页查看全部
-
urllib2下载网页方法
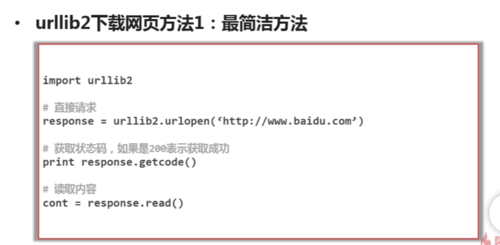
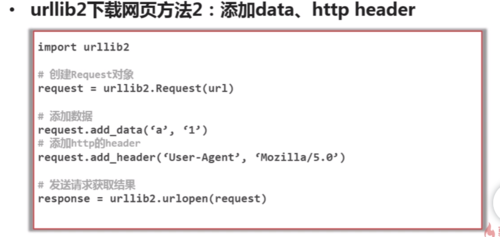
 查看全部
查看全部 -
做一个模拟浏览器访问,再拿header,id,size值,cookie等数据查看全部
-
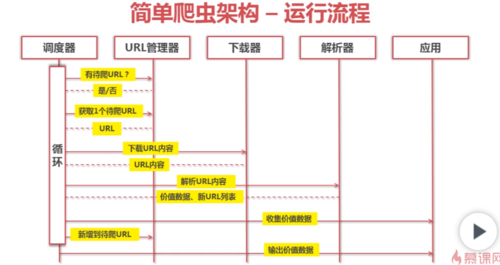 运行流程aaa查看全部
运行流程aaa查看全部 -
add_header 想服务器提供一个http头,可将爬虫伪装成某一浏览器去访问服务器查看全部






举报