

-
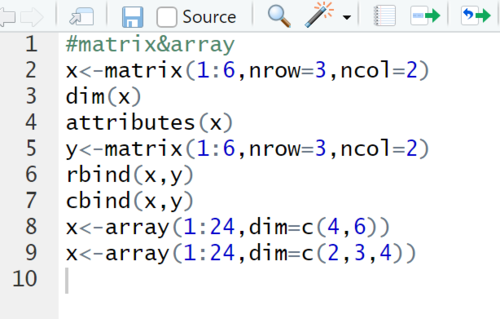
创建矩阵的。。。

元组array(与矩阵相比,可以不止两个维度)
 查看全部
查看全部 -
创建向量的。。。
 查看全部
查看全部 -
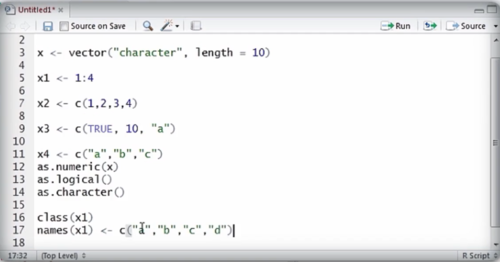
向量 类型转换
查看全部 -

对象属性哈
查看全部 -

数据类型哈
查看全部 -
head(x,n) #输出数据的前n行 tail(x) #输出数据的最后6行
summary(x) #对x的数据总体分析 str(x) #对x的数据进行总结
table(x) #表格输出 table(x,useNA="ifany") #表格输出x,统计缺失值
table(x,y) #生成关系x,y的二维表格
any(is.na(x)) #x中有缺失值返回TRUE,否则返回FALSE
x<-xtabs(Freq~Class + Age,data = titanic) #生成交叉表
print(object.size(airquality),units="kb") #将大小转换为Kb
查看全部 -
排序
sort(x$v2) #将v2这列元素升序排
sort(x$v2,decreasing = TRUE) #将v2这列元素降序排
order()# 返回排序数据对应的标号,并且可以设置多个参数排序
查看全部 -
split
根据因子或因子列表将向量或其他对象分组
通常与lapply一起使用
split(向量/列表/数据框,因子/因子列表)
head(airquality) #调用R库中本身自带的空气质量
s<- split(airquality,airquality$Month) #以月份分割数据
table(airquality$Month) #输出统计表格
sapply(s,function(x),colMeans([,c("Ozone","Wind"))],na.rm=TRUE))
输出指定列的均值,#na.rm = TRUE自动去除缺失值
查看全部 -
tapply(向量,因子/因子列表,函数/函数名)
f <- gl(3,5) #设置因子,水平为3,每个水平有5个数据
tapply(x,f,mean,simplify=FALSE) #函数默认为TRUE—向量,FALSE—列表
查看全部 -
mapply(函数/函数名,数据,函数相关的参数)
mapply(rep,1:4,4:1) #输出4个1、3个2......1个4.
s <- function(n,mean,std){
rnorm(n,mean,std)
} #创建从正态分布中抽取n个元素的函数
s(4,0,1) #在均值为0标准差为1的正态分布中抽取4个数据
查看全部 -
apply:apply(数组,维度,函数/函数名)
x <- matrix(1:16,4,4)
apply(x,2,mean) #求x矩阵列的均值
apply(x,1,mean) #求x矩阵行的均值
rowSums(x) #求矩阵x各行的总和
colSums(x) #求矩阵x各列的总和
x<-matrix(rnorm(100),10,10) #rnorm从正态分布总体里随机抽取100数
apply(x,1,quantile,probs=c(0.25,0.75)) #quntile百分位的点
x<-array(rnorm(2*3*4),c(2,3,4))
apply(x,c(1,2),mean) #返回第一维度和第二维度所构成面的均值
colSums(x)
查看全部 -
R语言函数lapply
可以循环处理列表中的每一个元素
lapply(参数):lapply(列表,函数/函数名,其他参数)
总是返回一个列表
sapply:简化结果
结果列表元素长度均为1,返回向量
结果列表元素长度相同且大于1,返回矩阵
lapply(x,mean) #求列表x的平均值
lapply(x,runif ) #runif 从一个均匀分布的总体中抽取若干个数出来,默
认为(0,1)区间
lapply(x,runif,min=0,max=100 ) #抽取的范围是0-100
x <- list(a=matrix(1:6,2,3),b=matrix(4:7,2,2))
lapply(x,function(m),m[1,])#function代表一个函数,m表示传入的参数是矩阵
查看全部 -
列表的子集
——[[]] / $ /[[]] [] / [[]] [[]]
——嵌套列表/不完全匹配 (partial matching)
视频关闭了完全匹配
查看全部 -
向量化操作
向量可以进行加减乘除等运算
矩阵的运算 x %*% y #表示x矩阵与y矩阵相乘
rep(x,n) #表示将x重复n次
查看全部 -
处理缺失值
x <- c(1,NA,2,NA,3)
x[!is.na(x)] #输出去除缺失值后的x
complete.cases(x,y) #x,y为两个向量,此函数输出结果为逻辑值,只要当对应位置的值都不为缺失值时返回TRUE,否则返回FALSE。
library(datasets) #加载R自带的datasets数据集
head(airquality) #查看数据集前6行
g <- complete.cases(airquality) #去除缺失值
airquality[g,][1:10,] #显示前十条记录
查看全部



举报