

-
字符(character)
数值(numeric:real numbers)
整数(interger:2L)
复数(complex):1+2i
逻辑(logical:True/False)
查看全部 -
构建子集subsetting:
原始数据(raw dataset) ->预处理后的数据(clean dataset) 。
原始数据通过预处理得到想要操作的数据,过程中需要构建子集。
向量的子集
基本方法:
[]:提取一个或多个类型相同的元素。类似于索引操作,但下标从1开始。[1:5]提取第1个到第5个元素。可在[]加上判定条件,如x[x>5],通过x>5返回每个元素与5比较大小后的真值,然后提取出x中为TRUE的元素。&并且,|或者。也可在[]输入元素对应的名字,名字要加""。
[[]]:从列表或数据框中提取元素
$:按名字从列表或数据框中提取元素 对于向量,直接用向量名加上判定条件,是对向量中的每个元素都进行判断,并返回每个元素对应的真值。
查看全部 -
向量
——只能包含同一类型的对象
——创建向量:
vector()
c()
as.logical()/as.nnumeric()/as.character()
注释:#
赋值:<-
查看全部 -
本章小结:
 查看全部
查看全部 -
日期与时间:
-日期:Date,是距离19700101的天数
获取当前系统的时间:date() #是字符型
获得日期类型的数据:Sys.Date() #是Date类型
将字符串转变为Date类型:as.Date("yyyy-mm-dd")
获取星期:weekdays(Date类型变量名字)
获取月份:months(Date类型变量名字)
获取季度:quarters(Date类型变量名字)
获取距离1970-01-01的天数:julian(Date类型变量名字)
Date类型之间可以进行运算,相减就是相差的天数,通过as.numeric()来转变为数值类型
-时间:POSIXct/POSIXlt,是距离19700101的秒数
POSIXct:整数,常用于存入数据框
POSIXlt:列表,还包含星期、年、月、日等信息
获取当前系统时间:Sys.time() #是POSIXct类型
通过names(unclass(POSIXlt类型变量名))获取存储的信息。
通过"POSIXlt类型变量名$信息"获得,比如p$sec
时间的模式存储strptime ()
通过as.来进行变量类型转换
注:strptime()运行是NA,是因为安装了中文版本,所以把Jan改成一月就完美解决了。
查看全部 -
数据框:
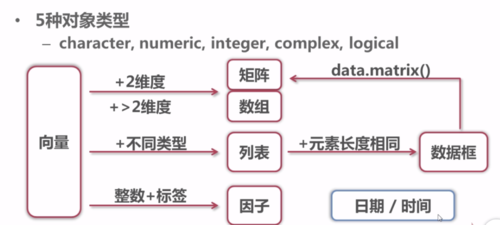
存储表格数据。视为各种元素长度相同的列表,每个元素代表一列数据,每个元素的长度代表行数,元素类型可以不同。相当于list。
创建数据框:数据框名字 <- data.frame(第一列内容id=c(1,2,3,4),第二列内容name=c(1,2,3,4),...,第n列内容) #列名和列的值
查看数据框行数:nrow(数据框名字)
查看数据框列数:ncol(数据框名字)
将数据框转换成矩阵:矩阵名字 <- data.matrix(数据框名字)
查看全部 -
缺失值:
NA和NaN NaN一般表示数字的缺失值,NA可以表示的缺失值类型更广,所以NaN属于NA,NA不属于NaN。
NA有类型属性:integer NA,character NA等
判断向量中是否有缺失值:is.na(向量名),is.nan(向量名),如果是缺失值返回TRUE,如果不是返回FALSE
查看全部 -
2.5 factor(因子)
--分类数据/有序(e.g. 低中高) vs 无序(e.g. 男女)
--整数向量+标签(label)
male/female vs 1/2
创建因子
x<-factor(c("female","female","male","male","female"))
y<-factor(c("female","female","male","male","female"),levels =c("male","female")) levels代表基线水平,谁在前,谁就是那个基线水平。统计分析中基线水平很重要。
table(x) 了解整体
unclass(x) 去掉属性看内容
因为可以把因子当成整型变量加上一个属性
class(unclass(x))
整型
因子factor:可以理解为整数向量+标签(label)(优于整数向量,每个数字有自己具体的含义)。
查看全部 -
注释:# ,跟python一样
控制台的命令是一次的,如果想重复使用,就要在上面的脚本新建文件并保存,而且文件里的执行需要选择run才可以执行,不像命令里的语句,直接按回车键。
向量(vector)的表示方法:
x<- vector("characrer",length=10) #长度为10的字符向量,元素为空
x1 <- 1:4 # x=(1,2,3,4)
x2 <- c(1,2,3,4)
如果用第三种方法去创建向量时,传入三种不同类型的值,R会自动强制转换成可用类型。
x3 <- c (TRUE, 10, "a")
注意元素“a”要加双引号,否则会显示找不到元素a。
强制类型转换:
as.numeric(参数)
as.logical(参数)
as.character(参数)
强制转换可能会引入缺失值,比如"a"强转numeric类型会变为NA
names()可以给向量的元素添加名称 ,注意name有s。
查看全部 -
1. 5种数据结构:字符 character, 数值 numeric, 整数 integer, 复数complex :1+2i, 逻辑: logical :TRUE/FALSE
2. 查看数据结构类型用class (), 括号里写要查看的变量
3. 赋值类型有两种:<- 还有=(有可能出现错误),标准用法是<- 。
4.强调数据是整数 则在数字后加L
5.逻辑类型True/False需要大写,R语言 区分大小写!
6.字符型的参数要用双引号" "引用
查看全部 -
R对象的属性(attribute):
名称 (name)
维度 (dimension: matrix, array)
类型 (class)
长度 (length)
查看全部 -
1. 5种数据结构:字符 character, 数值 numeric, 整数 integer, 复数complex :1+2i, 逻辑: logical :TRUE/FALSE
2. 查看数据结构类型用class (), 括号里写要查看的变量
3. 赋值类型有两种:<-还有=(有可能出现错误),标准用法是<- 。
4.强调数据是整数则在数字后加L
5.逻辑类型True/False需要大写,R语言 区分大小写!
6.字符型的参数要用双引号""引用
查看全部 -
赋值
数字:numeric
整数:数字后面加上大写的L integer
查看全部 -
数据结构
对象的五种基本类型:
字符
数值
整数
复数
逻辑
查看全部 -
数据结构
数据操作
构建子集
重要函数的使用
查看全部





举报