

-
因子可以理解为整数向量加标签 , 例如男性用1 表示,女性用2表示。
查看全部 -
因子是用来处理分类数据的, 分类数据分为:
有序数据和无序数据
查看全部 -
数组与矩阵类似,矩阵维度只能等于2 ,数组的维度可以大于2
声明数组:
x1 <- array(1:24,dim=c(2,3,4))
表明这个数组包含4 个2行3列的矩阵,数据值为1至24
查看全部 -
矩阵拼接:
按照行拼接 rbind(x1 ,x2)
按照列拼接 cbind(x1,x2)
查看全部 -
dim()查看矩阵的维度 例如: x1<- matrix(1:6,nrow=3,ncol=2)
表示这个矩阵有三行两列
1 4
2 5
3 6
dim(x1)
3 2
查看全部 -
矩阵填充是按照列的方式填充的
查看全部 -
向量的每一个元素都是可以有名称
声明 x1向量 : x1<c(1,2,3,4)
给向量的每一个元素命名:
names(x1) <-c("a","b","c","d")
查看全部 -
x4<-c("1","2","3")
as.numeric(x4) 向量类型转换为数值类型
查看全部 -
注释符号: #
查看全部 -
class() 查看对象类型
例如:
x<- 1
class(x) 将输出:“numeric”
表明x是数值型变量(可以是整数也可以是小数)
查看全部 -
c函数
This is a generic function which combines its arguments. The default method combines its arguments to form a vector. All arguments are coerced to a common type which is the type of the returned value, and all attributes except names are removed.
c(1,7:9) c(1:5, 10.5, "next") ## uses with a single argument to drop attributes x <- 1:4 names(x) <- letters[1:4] x c(x) # has names as.vector(x) # no names dim(x) <- c(2,2) x c(x) as.vector(x) ## append to a list: ll <- list(A = 1, c = "C") ## do *not* use c(ll, d = 1:3) # which is == c(ll, as.list(c(d = 1:3))) ## but rather c(ll, d = list(1:3)) # c() combining two lists c(list(A = c(B = 1)), recursive = TRUE) c(options(), recursive = TRUE) c(list(A = c(B = 1, C = 2), B = c(E = 7)), recursive = TRUE)
查看全部 -
数据框子集
> x <- data.frame(v1=1:5, v2=6:10, v3=11:15) > x v1 v2 v3 1 1 6 11 2 2 7 12 3 3 8 13 4 4 9 14 5 5 10 15 > x$v3[c(2,4)] <-NA #把v3列第2行和第4行元素设置成缺失值 > x v1 v2 v3 1 1 6 11 2 2 7 NA 3 3 8 13 4 4 9 NA 5 5 10 15 > x[,2] #按列号提取元素 [1] 6 7 8 9 10 > x[,"v2"] #按名称提取元素 [1] 6 7 8 9 10 > x[(x$v1<4 & x$v2>=8),] #提取满足第1列小于4,第2列大于等于8的所有行的元素 v1 v2 v3 3 3 8 13 > x[x$v1>2,] v1 v2 v3 3 3 8 13 4 4 9 NA 5 5 10 15 > x[which(x$v1>2),] v1 v2 v3 3 3 8 13 4 4 9 NA 5 5 10 15 > which(x$v1>2) [1] 3 4 5 > x$v1>2 [1] FALSE FALSE TRUE TRUE TRUE
which函数:Give the TRUE indices of a logical object, allowing for array indices.
> subset(x, x$v1>2) #构建子集 v1 v2 v3 3 3 8 13 4 4 9 NA 5 5 10 15
查看全部 -
矩阵子集
> x <- matrix(1:6, nrow=2, ncol=3) > x [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 > x[1,2] [1] 3 > x[2,3] [1] 6 > x[1,] #提取第1行元素 [1] 1 3 5 > x[,1] #提取第1列元素 [1] 1 2 > x[2, c(1,3)] #提取第2行第1列和第3列的元素 [1] 2 6 > class(x[1,2]) [1] "integer" > x[1, 2, drop=FALSE] #drop参数设置返回矩阵(FALSE)还是向量(TRUE) [,1] [1,] 3
查看全部 -
提取元素基本方法:
[]:提取一个或多个类型相同的元素(向量元素下标从1开始,不是0)
[[]]:从列表或数据框中提取元素
$:按名字从列表或数据框中提取元素
> x <- 1:10 > x[1] [1] 1 > x[5] [1] 5 > x[1:5] #类似Python切片 [1] 1 2 3 4 5 > x[6:10] [1] 6 7 8 9 10 > x[x>5] [1] 6 7 8 9 10 > x>5 [1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE > x[x>5 & x<7] #按条件提取元素 [1] 6 > x[x<3 | x>7] [1] 1 2 8 9 10 > y <- 1:4 > y [1] 1 2 3 4 > names(y) <- c("a", "b", "c", "d") #给每个元素命名 > y a b c d 1 2 3 4 > y[2] b 2 > y["b"] #用名字提取元素 b 2查看全部 -
R数据结构:
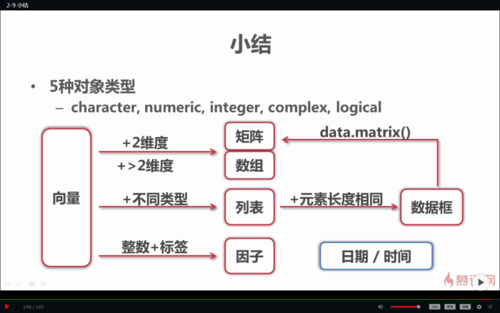 查看全部
查看全部


举报