

-
hive安装
查看全部 -
分区表(Partition)
Partition 对应于数据库的Partition列的密集索引
在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中
创建分区表
create table partition_table
(sid int,sname string)
partitioned by (gender string)
row format dellimited fields terminated by ',';
explain select * from partition_table
查看全部 -
内部表(Table)
与数据库中的Table 在概念上是类似的
每一个Table在Hive中都有一个相应的目录存储数据
所有的Table数据(不包括External Table)(以稳定的形式)都保存在这个目录中
删除表时,元数据与数据都会被删除
创建内部表
create table t1
(tid int, tname string, age int)
查看全部 -
Hive的数据存储
基于HDFS(Hadoop的数据仓库)
没有专门的数据存储格式
存储结构主要包括:数据库,文件,表,视图
可以直接加载文本文件(.TXT文件等)
创建表时,指定Hive数据的列分割符与行分隔符
表
table 内部表
Partiton 分区表
External Table 外部表
Bucket Table 桶表
视图
查看全部 -
时间类型:
Timestamps:一个与时区无关的,存储的形式是一个UNIX以来偏移量,也就是一个数字(长整型),
Dates:描述了一个特定的日期(年、月、日)以{YYYY-MM-DD} 的格式,不足两位以0补齐
查看全部 -
复杂数据类型的应用:
数组:
create table student
(sid int,
sname string,
grade array<float>--几个成绩)
集合类型:
1、
create table student1
(sid int,
sname string,
grade map<string,float>--一个科目的成绩);
2、
create talbe student3
(sid int,
sname string,
grades array<map<string,float>>--所有科目的成绩);
结构类型:
create table student4
(sid int,
info struct<name:string,age:int,sex:string>
结构有点相似与数组,但是数组中的值必须是相同数据类型的,而结构中的数据类型可以不同。
查看全部 -
HIVE 的数据类型
hive - 数据仓库 - 数据库
基本 数据类型
tinyint/smallint/int/bigint:整数类型
float/double:浮点数类型
boolean:布尔类型
string:字符串类型
复制数据类型:
array:数组类型,有一系列相同数据类型的元素组成
Map:集合类型,包含可以key->value键值对,可以通过key 来访问元素
Struct : 结构类型,可以包含不同数据类型的元素。这些元素可以通过“点语法”的方式来得到所需要的元素
时间类型
Date:从HIVE0.12.0开始支持
Timestamp : 从HIve0.8.0 开始支持
查看全部 -
hive的远程服务
远程服务启动方式:
端口号100000
启动方式:#hive --service HIV额server&
以JDBC 或ODBC的程序登录到hive中操作数据时,必须选用远程服务启动方式
查看全部 -
启动hive网页服务: hive --service hwi
查看全部 -
进入hive命令行:hive -- service cli
进入hive命令行2:hive
退出hive命令:1、exit 2、quit
常用的CLI命令
清屏:Ctrl+L 或者 !clear
查看数据仓库中表:show tables;
查看数据仓库z 内置的函数:show functions
-- : 注释部分
hive函数类似于oracle中的函数
查看表结构:desc 表名
查看HDFS上的文件:dfs -ls 目录
执行操作系统的命令:!命令
pwd : 查看当前目录下文件
-ls: 查看目录下所有文件
执行HQL语句:select *** from ***
静默模式(不打印调试输出信息):hive -S
hive -e : 不进入交互模式,直接执行语句
执行SQL的脚本
查看全部 -
创建一个partition表
create table partition_tabel(sid int,sname string) partitioned by (gender string) row format delimited fields terminated by ',';
向partition表中添加数据
insert into table partition_table partition(gender='M') select sid,sname from sample_data where gender='M';
insert into table partition_table partition(gender='F') select sid,sname from sample_data where gender='F';
explain select * from partition_table where gender='M';用来查看详细的执行步骤的
查看全部 -
Hive的数据类型
查看全部 -
sample_data的创建
http://www.imooc.com/qadetail/253191
查看全部 -
OLTP和OLAP
 查看全部
查看全部 -
数据仓库的结构和建立过程
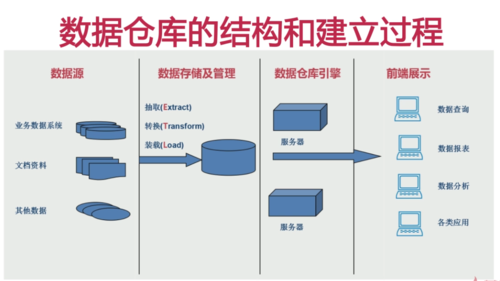 查看全部
查看全部




举报