

-
double temp; //定义临时变量temp temp = arr[j]; //将前面的数赋值给temp arr[j] = arr[j+1]; //前后之数颠倒位置 arr[j+1] = temp; //将较大的数放在后面
查看全部 -
double temp; //定义临时变量temp temp = arr[j]; //将前面的数赋值给temp arr[j] = arr[j+1]; //前后之数颠倒位置 arr[j+1] = temp; //将较大的数放在后面
查看全部 -
auto变量结束一次循环后会进行初始化
static变量结束一次循环后会保持上次循环结束时的值
register变量是调用局部变量的值放在cpu的寄存器中
extern变量声明的是外部变量 可以调用在该函数之后定义的变量查看全部 -
printf("普通字符输出格式符", 输出项);
查看全部 -
C 语言规定,标识符可以是字母(A~Z,a~z)、数字(0~9)、下划线_组成的字符串,并且第一个字符必须是字母或下划线。在使用标识符时还有注意以下几点:
(1)标识符的长度最好不要超过8位,因为在某些版本的C中规定标识符前8位有效,当两个标识符前8位相同时,则被认为是同一个标识符。
(2)标识符是严格区分大小写的。例如Imooc和imooc 是两个不同的标识符。
(3)标识符最好选择有意义的英文单词组成做到"见名知意",不要使用中文。
(4)标识符不能是C语言的关键字。想了解更多C语言关键字的知识,请查阅WIKI。
查看全部 -
吞吞吐吐分分给v给肌肤的高科技被辜负。我们都已经看到了哟我们都已经看到了吗?我也要努力了那么努力了很大程度上取决在自己心里的地位问题上提出来了!好👌?我的微博故事真的好喜欢😘!好想要和你们说一句话就是因为没有机会穿了高跟鞋墨镜🕶️!你有一个小时根本就不去上班啦、哈哈😆、哈哈哈😆、嗯?你说的不是一个人去哪里而是因为自己喜欢你这样一条线的时候好奇的人在哪了、哈哈这几位老师是吞吞吐吐分分给v给肌肤的高科技被辜负。我们都已经看到了哟我们都已经看到了吗?我也要努力了那么努力了很大程度上取决在自己心里的地位问题上提出来了!好👌?我的微博故事真的好喜欢😘!好想要和你们说一句话就是因为没有机会穿了高跟鞋墨镜🕶️!你有一个小时根本就不去上班啦、哈哈😆、哈哈哈😆、嗯?你说的不是一个人去哪里而是因为自己喜欢你这样一条线的时候好奇的人在哪了、哈哈这几位老师是吞吞吐吐分分给v给肌肤的高科技被辜负。我们都已经看到了哟我们都已经看到了吗?我也要努力了那么努力了很大程度上取决在自己心里的地位问题上提出来了!好👌?我的微博故事真的好喜欢😘!好想要和你们说一句话就是因为没有机会穿了高跟鞋墨镜🕶️!你有一个小时根本就不去上班啦、哈哈😆、哈哈哈😆、嗯?你说的不是一个人去哪里而是因为自己喜欢你这样一条线的时候好奇的人在哪了、哈哈这几位老师是吞吞吐吐分分给v给肌肤的高科技被辜负。我们都已经看到了哟我们都已经看到了吗?我也要努力了那么努力了很大程度上取决在自己心里的地位问题上提出来了!好👌?我的微博故事真的好喜欢😘!好想要和你们说一句话就是因为没有机会穿了高跟鞋墨镜🕶️!你有一个小时根本就不去上班啦、哈哈😆、哈哈哈😆、嗯?你说的不是一个人去哪里而是因为自己喜欢你这样一条线的时候好奇的人在哪了、哈哈这几位老师是
查看全部 -
比如定义一个函数void add(int a, int b),这里的a和b就是形参。
当你进行函数调用的时候,add(1, 2),这里的1和2就是实参。查看全部 -
result(后果)
查看全部 -
number (数字)
查看全部 -
#include <stdio.h>
int main()
{
int year = 2014; //今年是2014年
//补全一下代码
if((year%4 == 0&& == 0)||year%400 == 0)
{
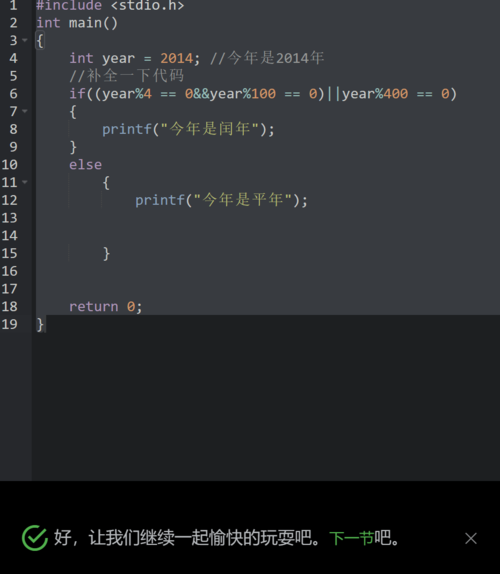
printf("今年是闰年");
}
else
{
printf("今年是平年");
}
return 0;
}
//为什么定义不符合却可以正确运行程序;
闰年的定义不是”能被4整除并且不能被100整除,或者能被400整除的年份吗?”
查看全部 -
我的问题i iiii我的问题i iiii我的问题i iiii我的问题i iiii
查看全部 -
题意:让arr1的第二个元素替换arr2最大的元素 H2数组与数组元素同时使用
定义max=某一元素
加入index,i;
查看全部 -
整个数组作函数参数理解:
(1)temp是个空杯子,把第一个杯子arr中的溶液间接倒进第二个杯子,以完成替换。格式:void temp(int arr[ ])对arr遍历
int main()
{
正常初始化+传入arr(即temp(arr);)
return 0;
};
数组某一个元素作函数参数理解
(1)第一部分先空输出arrvalue
(2)第二部分类似与1
查看全部 -
引用数组arr中的某一元素,所谓下标不能越界就是说arr[i] i不能大于等于该数组的长度
查看全部 -
default(不履行)
查看全部





举报