

-
优化步骤 2:记录上次返回的主键,在下次查询时使用主键过滤
SELECT film id, description FROM sakila.film WHERE film id >55 and film id <= 60 ORDER BY film id LIMIT 1, 5;
*避免了数据量大时扫描过多的记录
查看全部 -
优化步骤 1:使用有索引的列或主键进行 Order by 操作
SELECT film_id, description FROM sakila.film ORDER BY film_id LIMIT 50, 5;
查看全部 -
limit 常用于分页处理,时常会伴随 order by 从句使用,因此大多时候会使用 Filesorts 这样会造成大量的 IO 问题。
SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5;
查看全部 -
优化 group by 查询一优化后
Explain SELECT actor.first_name, actor.kast_name, c.cnt FROM sakila.actor INNER JOIN ( SELECT actor_id, COUNT (*) AS cnt FROM sakila.film_actor GROUP BY actor_id ) AS c USING(actor_id);
在子查询内加过滤条件
查看全部 -
explain SELECT actor.First_name, actor.Last_ name, COUNT (*) FROM sakila.film_actor INNER JOIN sakila.actor USING(actor_id) GROUP BY film_actor.actor_id;
查看全部 -
通常情况下,需要把子查询优化为 join 查询,但在优化时要注意关联建是否有一对多的关系,要注意重复数据。
(查询 sandra 出演的所有影片)
explain SELECT title, release_year, LENGTH FROM film WHERE film_id IN( SELECT film_id FROM film_actor WHERE actor_id IN SELECT actor_id FROM actor WHERE first_name = 'sandra'))
查看全部 -
在一条 SQL 中同时查出 2006 年和 2007 年电影的数量一优化 count0 函数正确的方式:
SELECT COUNT (release_year='2006' OR NULL) AS '2006 年电影数量', COUNT (release_year='2007’ OR NULL) AS '2007 年电影数量' FROM film;
查看全部 -
在一条 SQL 中同时查出 2006 年和 2007 年电影的数量一优化 count() 函数
错误的方式:
SELECT COUNT (release_year='2006' OR release_year='2007') FROM film;
无法分开计算 2006 和 2007 年的电影数量
SELECT COUNT (*) FROM film WHERE release_year='2006' AND release_year ='2007';
Release_year 不可能同时为 2006 和 2007,因此上有逻辑错误
查看全部 -
查询最后支付时间一优化 max() 函数
select max(payment_date) from payment;
 查看全部
查看全部 -
extra 列需要注意的返回值
Using filesort:看到这个的时候,查询就需要优化了。MYSQL 需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
Using temporary 看到这个的时候,查询需要优化了。这里,MYSQL 需要创建一个临时表来存储结果,这通常发生在对不同的列集进行 ORDER BY 上,而不是 GROUP BY 上
查看全部 -
如何分析 SQL 查询
使用 explain 查询 SQL 的执行计划
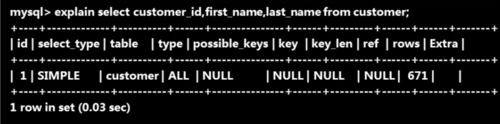
explain 返回各列的含义
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为 const、eq_reg、ref、range、index 和 ALL
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。
key:实际使用的索引。如果为 NULL,则没有使用索引。
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows:MYSQL 认为必须检查的用来返回请求数据的行数
查看全部 -
如何通过慢查日志发现有问题的 SQL?
查询次数多且每次查询占用时间长的 SQL
通常为 pt-query-digest 分析的前几个查询
IO 大的 SQL
注意 pt-query-digest 分析中的 Rows examine 项
未命中索引的 SQL
注意 pt-query-digest 分析中 Rows examine 和 Rows Send 的对比
查看全部 -
慢查日志的分析工具—— pt-query-digest 输出

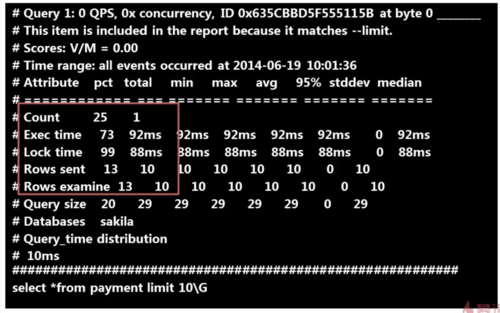 查看全部
查看全部 -
慢查日志的分析工具
输出到文件
pt-query-digest slow-log > slow_log.report
输出到数据库表
pt-query-digest slow.log -review \
h=127.0.0.1, D=test, p=root, P=3306, u=root, t=query_review \
--create-reviewtable \
--review-history t= hostname_slow
查看全部 -
慢查日志的分析工具 —— mysqldumpslow 输出
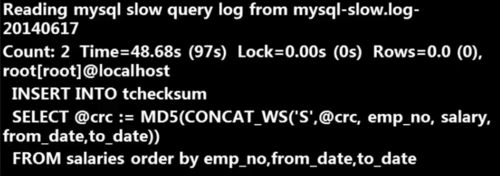
 查看全部
查看全部

举报