

-
数据的修改和删除
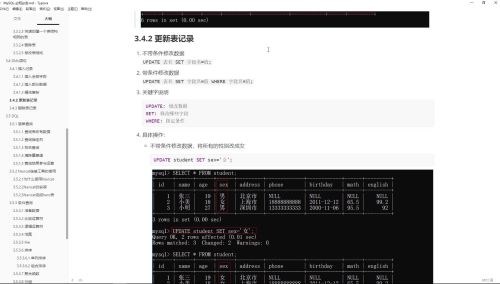
UPDATE: 修改数据
SET: 修改哪些字段
WHERE: 指定条件
UPDATE 表名 SET 字段名=值; //不带条件修改数据
UPDATE 表名 SET 字段名=值 WHERE 字段名=值; //带条件的修改数据
DELETE FROM 表名; // 不带条件的删除数据
DELETE FROM 表名 WHERE 字段名=值; // 带条件的删除数据
TRUNCATE TABLE 表名; // 删除表记录
trancale和delete的区别:
delete是将表中的数据一条一条删除
truncate是将整个表摧毁,重新创建一个新的表,新表的结构和原来的表的结构一样查看全部 -
叉入表数据
 查看全部
查看全部 -
插入 表数据
查看全部 -
插入表数据
查看全部 -
插入表数据
查看全部 -
数据复制
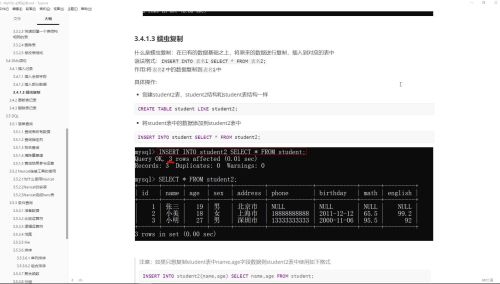 查看全部
查看全部 -
插入表数据
 查看全部
查看全部 -
CREATE TABLE 表名(字段名1 字段类型1,字段名2 字段类型2...); //创建表 与字段
SHOW TABLES; // 查看某个数据库的所有表
DESC 表名; //查看表结构
SHOW CREATE TABLE 表名; //查看建表的sql语句
CREATE TABLE 新表名 LIKE 旧表名 ; // 快速创建一个结构相同的表名
DROP TABLE 表名 ; //直接删除表
DROP TABLE IF EXISTS 表名; //判断表是否存在并删除表
ALTER TABLE 表名 ADD 列名 类型; //添加列表
ALTER TABLE 表名 MODIFY 列名 新的类型; //修改列的类型
ALTER TABLE 表名 CHANGE 旧列名 新列名 类型(类型不能改,要和原来的一样); // 修改列名
ALTER TABLE 表名 DROP 列名; //删除列
RENAME TABLE 表名 TO 新表名; // 修改表名
ALTER TABLE 表名 character set 字符集; //修改字符集查看全部 -
CREATE DATABASE 数据库名; //直接创建数据库
CREATE DATABASE IF NOT EXISTS 数据库名//判断是否存在并创建数据库
CREATE DATABASE 数据库名 CHARACTER SET 字符集;//创建数据库并指定字符集
SHOW DATABASES; //查看所有数据库
SHOW CREATE DATABASE 数据库名; //查看某个数据库的定义信息
ALTER DATABASE 数据库 DEFAULT CHARACTER SET 字符集;//修改数据库字符集
DROP DATABASE 数据库名; //删除数据库
SELECT DATABASE(); //查看正在使用的数据库USE 数据库名; //使用/切换数据库
show table status from 库名 where name='表名' ; //查看某个表使用的引擎
查看全部 -
windows+r service.smc
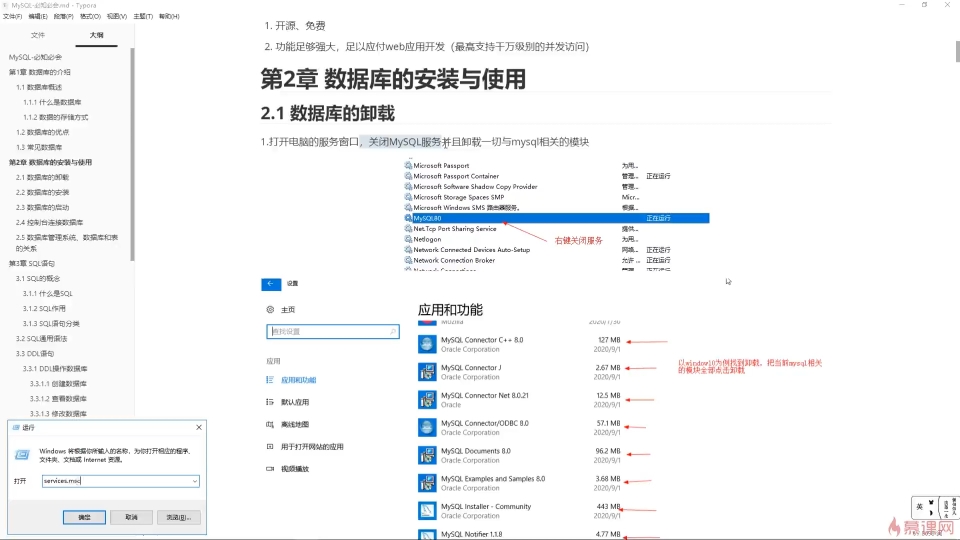 查看全部
查看全部 -
1、默认值:往表中添加数据时,如果不指定这个字段的数据,就使用默认值
2、基本语法结构:字段名 字段类型 DEFAULT 默认值
查看全部 -
1、非空:这个字段必须设置值,不能为NULL
2、非空约束的基本语法:字段名 字段类型 NOT NULL
3、可以和唯一约束搭配:字段名 字段类型 UNIQUE NOT NULL
查看全部 -
1、唯一:在这张表中这个字段的值不能重复
2、唯一约束基本格式:字段名 字段类型 UNIQUE
3、实现唯一约束,不能插入相同的值,但是NULL没有值,所以不存在重复的值,可以插入多个NULL
查看全部 -
1、主键(PRIMARY KEY):用来唯一标识一条记录,每个表都应该有一个主键,并且每个表只能有一个主键
2、哪个字段应该作为表的主键?通常不用业务字段作为主键,单独给每张表设计一个id字段,把id字段作为主键。主键是给数据库和程序使用的,不是给最终客户使用的。所以主键有没有含义没有关系,只要不重复,非空就行。
3、创建主键:PRIMARY KEY
4、主键的特点:主键必须包含唯一的值;主键列不能包含NULL值
5、创建主键方式:
在创建表的时候给字段添加主键:字段名 字段类型 PRIMARY KEY
6、删除主键
ALTER TABLE 表名 OROP PRIMARY KEY;
7、主键自增
AUTO_INCREMENT 表示自动增长(字段类型必须是整数类型)
扩展
默认AUTO_INCREMENT的开始值是1,如果希望修改起始值,使用以下SQL语法:
ALTER TABLE 表名 AUTO_INCREMENT=起始值;
8、DELETE和TRUNCATE 的区别
DELETE:删除表中的数据,但不重复AUTO_INCREMENT的值
TRUNCATE摧毁表,重建表,AUTO_INCREMENT重置为1
查看全部 -
数据库的约束:对表中的数据进行进一步的限制,保证数据的正确性、有效性和完整性
约束种类:
PRIMARY KEY:主键
UNIQUE:唯一
NOT NULL:非空
OEFAUL:默认
FOREIGN KEY:外键
主键(PRIMARY KEY):用来唯一标识一条记录,每个表都应该有一个主键,并且每个表只能有一个主键
哪个字段应该作为表的主键?
通常不用业务字段作为主键,单独给每张表设计一个id字段,把id字段作为主键。主键是给数据库和程序使用的,不是给最终客户使用的。所以主键有没有含义没有关系,只要不重复,非空就行。
创建主键:PRIMARY KEY
主键的特点:主键必须包含唯一的值;主键列不能包含NULL值
创建主键方式:在创建表的时候给字段添加主键:
字段名 字段类型 PRIMARY KEY
查看全部 -
数据库的约束:对表中的数据进行进一步的限制,保证数据的正确性、有效性和完整性
约束种类:
PRIMARY KEY:主键
UNIQUE:唯一
NOT NULL:非空
OEFAUL:默认
FOREIGN KEY:外键
查看全部 -
1、limit语句
limit是限制的意思,limit的作用就是限制查询记录的条数
SELECT *|字段列表 [as 别名] FROM 表名 [WHERE 子句] [GROUPBY子句] [HAVING 子句] [ORDER BY 子句] [LIMIT 子句];
limit子句放在最后是因为前面所有的限制条件都处理完了,只剩下显示多少条记录的问题了。
2、LIMIT语法格式:
LIMIT offset,length ; 或者 limit length;offset 是指偏移量,可以认为是跳过的记录数量,默认为0
length 是指需要显示的总记录数
例如
查询hero表中数据,从第三条开始显示,显示6条
SELECT * FROM students LIMIT 2 , 6;
3、LIMIT使用场景:分页
例如登录的淘宝、京东等,返回的信息有很多,是一页页显示固定的条数
每页显示5条
第一页:LIMIT 0,5; 跳过0条,显示5条
第二页:LIMIT 5,10;跳过5条,显示5条
第三页:LIMIT 10,5;跳过10条,显示5条
查看全部 -
CREATE DATABASE db1 创建数据库
SHOW DATABASES 显示数据库
查看全部 -
分组
分组查询是指使用GROUP BY语句对查询信息进行分组,相同的数据作为一组
SELECT 字段1,字段2,…… FROM 表名 GROUP BY 分组字段 [HAVING 条件];
分组后用having进行条件过滤
GROUP BY 怎么分组的?将分组字段结果中相同内容作为一组
分组和聚合函数一起使用
注意事项:当使用某个字段分组,在查询的时候也需要将这个字段查询出来,否则看不到数据是属于哪组的
having与where的区别
having 是在分组后对数据进行过滤
where 是在分组前对数据进行过滤
having 后面可以使用聚合函数
where 后面不可用使用聚合函数
查看全部







举报