

-
通过函数isinstance()可以判断一个变量的类型。
查看全部 -
lass Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
student = Student('Alice', 'girl', 100)
print(student.name) # ==> Alice
print(student.gender) # ==> girl
print(student.score) # ==> 100在定义继承类的时候,有几点是需要注意的:
class Student()定义的时候,需要在括号内写明继承的类Person
在__init__()方法,需要调用super(Student, self).__init__(name, gender),来初始化从父类继承过来的属性
查看全部 -
Python定义类方法
在上一节课,为了操作实例对象的私有属性,我们定义了实例方法;同样的,如果需要需要操作类的私有属性,则应该定义类的方法。
默认的,在class中定义的全部是实例方法,实例方法第一个参数 self 是实例本身。
要在class中定义类方法,需要这么写:class Animal(object): __localtion = 'Asia' def __init__(self, name, age): self.name = name self.age = age @classmethod def set_localtion(cls, localtion): cls.__localtion = localtion @classmethod def get_localtion(cls): return cls.__localtion print(Animal.get_localtion()) # ==> Asia Animal.set_localtion('Afica') print(Animal.get_localtion()) # ==> Africa
和实例方法不同的是,这里有两点需要特别注意:
类方法需要使用@classmethod来标记为类方法,否则定义的还是实例方法
类方法的第一个参数将传入类本身,通常将参数名命名为 cls,上面的 cls.__localtion 实际上相当于Animal.__localtion。
查看全部 -
Python定义实例方法
上一节课提到,私有属性没有办法从外部访问,只能在类的内部操作;那如果外部需要操作私有属性怎么办?这个时候可以通过定义类或者实例的方法来操作私有属性,本节课先来介绍实例方法。
实例的方法指的就是在类中定义的函数,实例方法的第一个参数永远都是self,self是一个引用,指向调用该方法的实例对象本身,除此以外,其他参数和普通函数是完全一样的。class Person(object): def __init__(self, name): self.__name = name def get_name(self): return self.__name
在上面的定义,name是实例的私有属性,从外部是无法访问的,而get_name(self) 就是一个实例方法,在实例方法里面是可以操作私有属性的,注意,它的第一个参数是self。
另外,__init__(self, name)其实也可看做是一个特殊的实例方法。
通过定义get_name(self)方法,在外部就可以通过这个方法访问私有属性了。p = Person('Alice') print(p.get_name()) # ==> Alice
注意,在外部调用实例方法时,是不需要显式传递self参数的。
查看全部 -
在类属性和实例属性同时存在的情况下,实例属性的优先级是要高于类属性的,
查看全部 -
__init__ 这里是双下划线
查看全部 -
Python类的定义与实例化
class Person: pass
class Person(): pass
class Person(object): pass定义了类之后,就可以对类进行实例化了,实例化是指,把抽象的类,赋予实物的过程。比如,定义好Person这个类后,就可以实例化多个Person出来了。
创建实例使用类名+(),类似函数调用的形式创建:class Person(object): pass xiaohong = Person() xiaoming = Person()
查看全部 -
class A(object):
def __init__(self, a):
print ('init A...')
self.a = a
class B(A):
def __init__(self, a):
super(B, self).__init__(a)
print ('init B...')
class C(A):
def __init__(self, a):
super(C, self).__init__(a)
print ('init C...')
class D(C, B):
def __init__(self, a):
super(D, self).__init__(a)
print ('init D...')
d=D('d')结果(class D(C,B) ==> 先执行B再执行C):
init A...
init B...
init C...
init D...
查看全部 -
在类属性和实例属性同名的情况下,实例属性的优先级是要高于类属性的,在操作实例的时候,优先是操作实例的属性。
查看全部 -
import time
def performance(unit):
def perf_decorator(f):
def wrapper(*args, **kwargs):
t1 = time.time()
r = f(*args, **kwargs)
t2 = time.time()
t = (t2 - t1) * 1000
if unit == 'ms':
t = (t2 - t1) * 1000 * 1000
print('call {}() in {}{}'.format(f.__name__,t,unit))
return r
return wrapper
return perf_decorator
@performance('ms')
def factorial(n):
return reduce(lambda x,y:x + y,range(1, n+1))
factorial(10)
查看全部 -
import time
def performance(f):
def fn(*args, **kw):
t1 = time.time()
r = f(*args, **kw)
t2 = time.time()
print('call %s() in %fs' %(f.__name__,(t2 - t1)))
return r
return fn
@performance
def ffa(n):
return reduce(lambda x,y: x + y, range(1,n+1))
print(ffa(10))
查看全部 -
# Enter a code
import socket
server = socket.socket() # 1.新建 socket
server.bind(('127.0.0.1', 8999)) # 2.绑定IP和端口(其中127.0.0.1为本机回环IP)
server.listen(5) # 3.监听连接
s, addr = server.accept() #4. 接受连接
print('connect addr :{}'.format(addr))
content = s.recv(1024)
print(str(content, encoding = 'utf-8')) #接受来自客户端的消息,并编码打印出来\
s.close()
import socket
client = socket.socket() #1.新建socket
client.connect(('127.0.0.1', 8999)) #2.连接服务端(注意,IP和端口要和服务端一致)
client.send(bytes('hello world, hello socket', encoding = 'utf-8')) #发送内容,注意发送的是字节字符串
client.close()
查看全部 -
注意应该是self 不是类名
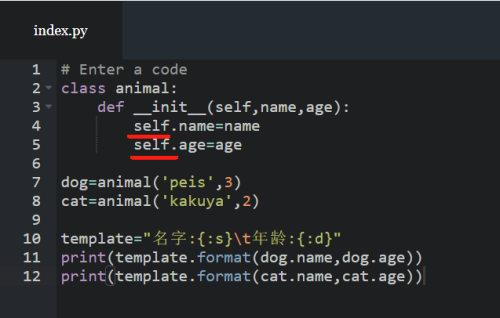 查看全部
查看全部 -
在上面的代码中,localtion就是属于Animal这个类的类属性,此后,通过Animal()实例化的所有对象,都可以访问到localtion,并且得到唯一的结果。
类属性也是可以动态添加和修改的,需要注意的是,因为类属性只有一份,所以改变了,所有实例可以访问到的类属性都会变更:
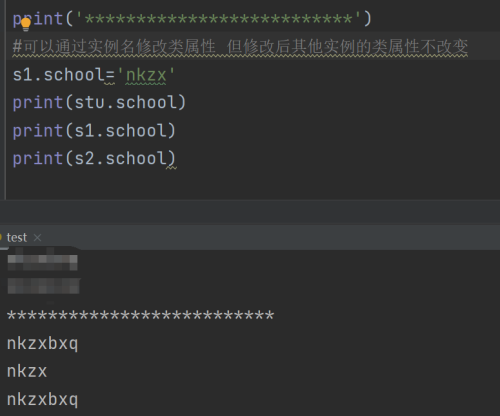
注意应该是Animal(类名) 不是self
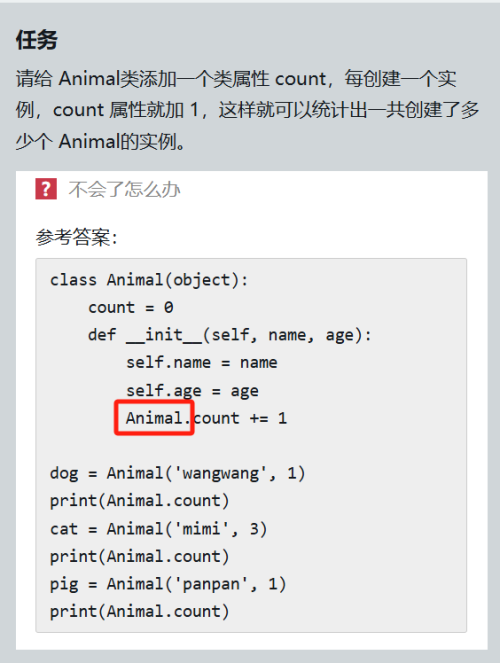 查看全部
查看全部 -
# Enter a code
class Fib(object):
def __init__(self, num):
self.num = num
self.res = []
a = 0
b = 1
for x in range(num):
self.res.append(a)
a,b = b, a + b
def __str__(self):
return str(self.res)
def __len__(self):
return self.num
fib = Fib(10)
print(fib)
print(len(fib))
查看全部



举报