

-
1、countcat():字符连接;select concat('imooc','-','mysql') from db
2、countcat_ws():使用指定的分隔符进行字符连接;select concat_ws('|','A','B','C')
3、format():数字格式化,返回一个字符串;select format(12345.67,2):小数点后保留两位
4、upper():字符大写;
5、lower():字符小写;
6、left():获取左侧字符;
7、right():获取右侧字符;
8、length():获取字符串长度;
9、ltrim():删除前导空格;rtrim():删除后续空格;trim():删除前导及后续空格;select trim(leading '?' from '??mysql???'):删除前导的‘?’
select trim(trailing '?' from '??mysql???'):删除后续的‘?’
select trim(both '?' from '??mysql???'):删除所有的‘?’,但是无法删除中间的‘?’,需要使用replace()函数
replace('??my??sql???','?'," ")
10、substring():截取字符串
substring('mysql',1,2):从第1位取2位,起始为hi也可以为负值,但长度不能为负值
11、like:模式匹配
在mysql中,%代表任意多个字符,_代表任意一个字符。
使%或者_不为通配符的方法:
select * from test where first_name like '%1%%' escape '1':1后面的%不在为通配符,而是代表%
查看全部 -
子查询是指出现在select语句中的,必须出现在小括号内。
子查询的外层可以是select语句,insert语句、update语句及delete语句。
子查询中可以包含多个关键字或条件,如group by、order by、limit以及相关函数等。
使用子查询的环境:
比较运算符引发的子查询
in或not in引发的子查询
exist或not exist引发的子查询。
多表更新、多表删除、select语句中都可以使用连接。
连接的类型:
内连接(交集,左表和右表都符合条件的记录)
外连接(左连接和右连接)
运算符和函数:1、字符函数 2、数值运算符与函数3、比较运算符与函数4、日期时间函数5、信息函数6、聚合函数7、加密函数
查看全部 -
多表的删除:
DELETE tbL_name[.*] [, tbl_name[.*]] ...FROM table_references [WHERE where_condition]
首先找到多余的:SELECT goods_id,goods_name FROM tdb_goods GROUP BY(分组) goods_name HAVING(分组的条件) count(goods_name)>=2;
然后是删除:DELETE t1 FROM tdb_goods AS t1 LEFT JOIN (SELECT goods_id,goods_name FROM tdb_goods GROUP BY goods_name HAVING count(goods_name)>=2) AS t2 ON t1.goods_name=t2.goods_name WHERE t1.goods_id>t2.goods_id;
查看全部 -
数据表的自身连接:只要在表前加上p/s.就可以了。又因为种类里有很多不同的类型,我们想知道各个种类有多少个类型。此时需要计数:
如:SELECT s.type_id,s.type_name,p.type_name FROM tdb_goods_types AS s LEFT JOIN tdb_goods_types AS p ON s.parent_id=p.type_id;
p.父表;s.子表
(父子表还可以调换:SELECT p.type_id,p.type_name,count(s.type_name) child_count【计数】 FROM tdb_goods_types p LEFT JOIN tdb_goods_types s ON p.parent_id=s.type_id GROUP BY 【分组】p.type_name ORDER BY【排序】 p.type_id;)
查看全部 -
外连接:
A LEFT JOIN B join_condition(左外连接,右外连接情况下调换AB就可)
数据表B的结果集依赖数据表A。(A中有的记录才可以在B中显示,否则不显示)
数据表A的结果集根据左连接条件依赖所有数据表(B表除外)。
左外连接条件决定如何检索数据表B(在没有指定WHERE条件的情况下)。(A表决定B表)
如果数据表A的某条记录符合WHERE条件,但是在数据表B不存在符合连接条件的记录,将生成一个所有列为空的额外的B行。如果使用内连接查找的记录在连接数据表中不存在,并且在WHERE子句中尝试以下操作: col-namd IS NULL时,如果col-name被定义为NOT NULL, MySQL将在找到符合连执着条件的记录后停止搜索更多的行。
查看全部 -
外连接:左外连接,右外连接
左外连接:显示左表的全部记录及右表符全连接条件的记录,如果左表的某个字段记录右表不满足,则那个数据为NULL
右外连接:显示右表的全部记录及左表符全连接条件的记录,如果右表的某个字段记录左表不满足,则那个数据为NULL
查看全部 -
INNER JOIN,内连接
在MySQL中,JOITERN,CROSS JOIN和INNER JOIN是等价的。
LEFT [OUTER] JOIN在外连接
RIGHT [OUTER] JOIN,右外连接
连接条件
使用ON关键字来设定连接条件,也可以使用WHERE来代替。
通常使用ON关键字来设定连接条件,使用where关键字进行结果集记录的过滤。
查看全部 -
如果数据表中文字符很多,而且数据很多时那么查询运行的时间将会很多,所以有时必要将一些文字编程数字,方便查询。那么就需要建立外键,将文字转化成数字(如类型转化成品类1,2,3、、、)
一、因此先创建一个数据表: GREAT TABLE good_cates FROM tdb_goods IF NOT EXISTS good_cate;
二、然后查看总表里要更改的品类有多少个类型:SELECT good_cate FROM tdb_good GROUP BY good_cate;
三、然后将查询到的品类写入到新建表中(查看表结构DESC tdb_goods_cates;):
INSERT tdb_goods_cates(cate_name) SELECT goods_cate FROM tdb_goods GROUP BY goods_cate;
四、最后根据分类表更新总表(多表更新):
UPDATE table references SET col_namel={expr1|DEFAULT) [,col_name2={expr2 | DEFAULT])]...[WHERE where_condition]
两张表的链接可以赋予别名也可以不赋予别名,即使用表的名称进行连接。或者还可以使用表的类型进行连接。
如:UPDATE tdb_goods INNER JOIN(常用) tdb_goods_cateS ON(条件) goods_cate=cate_name SET(更新的值) goods_cate=cate.id.
表的更新步骤为:
一、创建表
二、INSERT SELECT 将记录写入数据表
三、多表的更新
多表更新:
(1) UPDATE table_references SET col_name1={expr1| DEFAULT}[ , col_name2={expr2 | DEFAULT] ... [WHERE where_condition]
(2) CREATE TABLE [IF NOT EXISTS] tbl_name [(create_definition,...] select_statement
方法(2)要优于方法(1),方法(2)相当于将查询和插入结合在一起
由于
如:语句一:SELECT brand_name FROM tdb_goods group by brand_name;
语句二:
CREAT TABLE tdb_goods_brands
—>(
—>brand_id SMALLINT UNSIGEDV PREMAY KEY AUTO_INCREMENT,
—>brand_name VARCHAR(40) NOT NULL
—>)
—>SELECT brand_name FROM tdb_goods GROUP BY brand_name;
用表的别名进行表的更新更方便:
如:UPDATE tdb_goods AS g INNERJOIN tdb_goods_brands AS b ON g.brand_name=b.brand_name
—>SET g.brand_name=b.brand_id;
五、在更新表之后,由于表的结构可能还是字符型,因此先查看一下表的结构:
SHOW COLUMNS FROM tdb_goods;(或者DESC tdb_goods)
六、然后更改结构,即将字符改成数字:
ALTER TABLEtdb_goods
—>CHANGE goods_cate cate_id SMALLINT UNSIGNED NOT NULL,
—>CAHNGE brand_name brand_id SMALLINT UNSIGNED NOT NULL;
此时才是真正的对数据表减肥
查看全部 -
-- 通过tdb_goods_cates数据表来更新tdb_goods表
UPDATE tdb_goods INNER JOIN tdb_goods_cates ON goods_cate = cate_name
SET goods_cate = cate_id ;
查看全部 -
INSERT ... SET ...
可以使用子查询 INSERT [INTO] tbl_name [(col_name,...)] SELECT ...将查询结果写入数据表
Eg:
INSERT INTO table_name [(column_name)] SELECT column_name2 FROM table_name2 GROUP BY column_name3;
子查询与连接——INSERT-SET子查询
1、INSERT tbl_name [(col_name,...)] (SELECT col2_name FROM tbl2 ...)
2、同样注意字段数量和类型匹配 CREATE TABLE IF NOT EXISTS tdb_goods_cates( cate_id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT, cate_name VARCHAR(40) NOT NULL ); SELECT goods_cate FROM tdb_goods GROUP BY goods_cate; //列出所有品牌种类cate// INSERT INTO <表名> SELECT..... DESC tdb_goods_cates; //显示出tdb_goods_cates表中的项目名称// INSERT tdb_goods_cates(cate_name) SELECT goods_cate FROM tdb_goods GROUP BY goods_cate; //在表tdb_goods_cates中插入tdb_goods中的cate种类//
查看全部 -
使用比较运算符的子查询=、>、<、>=、<=、<>、!=、<=>
语法结构 operand comparison_operator subquery
如:SELECT AVG(goods_price) FROM tb1_goods; ——查找到的是平均价格。
SELECT ROUND(AVG(goos_price),2) FROM tb1_goods; ——这个是对查找到的平均数保留两位小数。
假如平均值为:5636.36 , 那么接下来查找大于平均值的列:
SELECT goods_id,goods_name,goods_price FROM tb1_goods WHERE goods_price>=5636.36;
因为5636.36是说那个一条的结果,那么将两个语句合并后为:(子查询)
SELECT goods_id,goods_name,goods_price FROM tb1_goods WHERE goods_price>=(SELECT ROUND(AVG(goods_price),2) FROM tb1_goods);
如果要查找其他结果,如:SELECT goods_price FROM tb1_goods WHERE goods_cate='超级本'; ——查找超级本的价格
SELECT * FROM tb1_goods WHERE goods_cate='超级本'; —— 查找超极本的所有列
SELECT good_id,goods_name,goods_price FROM tb1_goods WHERE goods_price>(SELECT goods_price FROM tb1_name WHERE goods_cate = '超极本'); ——返回值为错误,原因是>后面的查找结果不是唯一的,而且并没有指定>的是具体那个数或者范围,那么:
此时就需要用到:operand comparison_operator ANY (subquery)
operand comparison_operator SOME (subquery)
operand comparison_operator ALL (subquery)其中,ANY, SOME, ALL的使用原则就是:
ANY SOME ALL
> 和 >= min min max
< 和 <= max max min
= 任意值 任意值
<> 和 != 任意值
查看全部 -
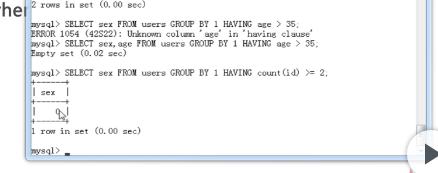
having进行条件指定讲究有点多啊,如果是having部分的条件是聚合函数,比如最大值,最小值,平均值,等等,则可以写不在select中的字段,写在聚合函数里面即可,但是如果没有聚合函数则必须是存在于select中的某个字段
 查看全部
查看全部 -
查询结果分组 GROUP BY
[GROUP BY {col_name|position} [ASC|DESC],...]
ASC:升序,默认
DESC:降序
position:SELECT语句中列的序号
例:
SELECT sex FROM users GROUP BY sex;
对users中的sex按sex进行分组
例:
SELECT * FROM users GROUP BY 1;
(这里的1表示查询的第一个字段,这里查询所有字段信息,第一个字段就是id,所以会按照id字段进行分组)
1表示SELECT语句中第一个出现的字段,即位置。
建议BY后写列名称,不写位置,因为位置还要人为数。
注意:如果存在相同的值(例如上面的age可能有多个相同的值),只会保留一个。但使用ORDER BY 就不会省略。
查看全部 -
WHERE 条件表达式 对记录进行过滤,
如果没有指定的WHERE子句,则显示所有记录 在WHERE表达式中,
可以使用MYSQL 支持的函数或运算符
查看全部 -
查询表达式
每一个表达式表示想要的一列,必须至少有一个
多个列之间以英文逗号分隔
星号(*)表示所以列 tbl_name.*可以表示命名表的所有列
查询表达式可以使用[As]alias_name为其赋予别名
别名可用于GROUP BY,ORDRE BY或HAVING子句
SELECT 字段出现顺序影响结果集出现顺序,字段别名也影响结果集字段别名。
一、查找记录
1、语法:
SELECT select_expr [,select expr2...] 只查找某一个函数或表达式
{
FROM table_references 查询表名
[WHERE where_conditon] 查询条件
[GROUP BY {col_name|position} [ASC|DESC],...] 按某个字段进行分组,相同的只显示第一个
[HAVING where_conditon] 分组时,给出显示条件
[ORDER BY {col_name|expr|position} [ASC|DESC],...] 排序
[LIMIT {[offset,]row_count|row_count OFFSET offset}] 限制返回数量
}
2、查询表达式的顺序会影响结果顺序
每个表达式表示想要的一列,必须有至少一个
多个列直接以英文逗号分隔
星号*表示所有列
3、使用tbl_name.col_name来表示列记录,这多表查询时可以区别开同名的列
4、使用[AS] alias_name为其赋予别名,别名可以用于GROUP BY、ORDER BY或HAVING子句,例如SELECT id AS userId,username AS uname FROM users; 这样查询出来的结果会用别名表示
查看全部

举报