

-
hadoop客户端节点安装
查看全部 -
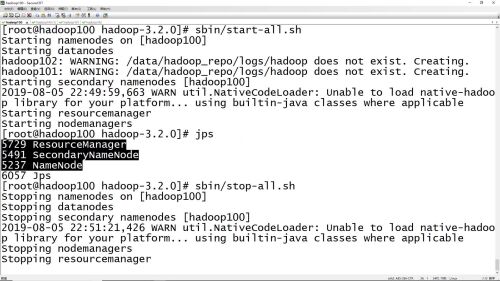
hadoop分布式集群 start-all.sh、stop-all.sh启动和停止命令
 查看全部
查看全部 -
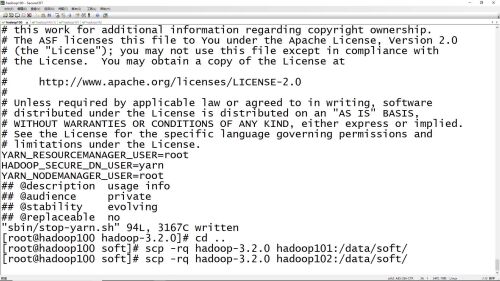
hadoop解压文件从主节点拷贝到从节点
 查看全部
查看全部 -
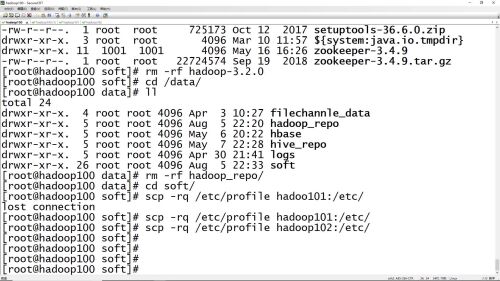
主节点环境配置拷贝到从节点
 查看全部
查看全部 -
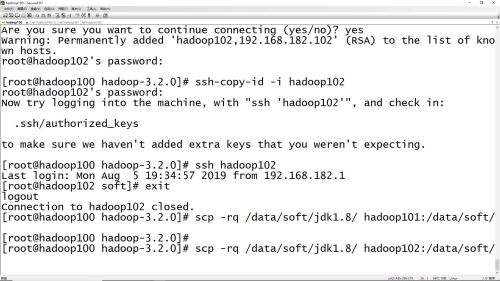
主节点jdk拷贝到从节点
 查看全部
查看全部 -
分布式集群部署:主节点可以免密登陆到其他所有节点,ssh-copy-id i hadoop101 把主节点的ssh秘钥id复制到其他从节点上
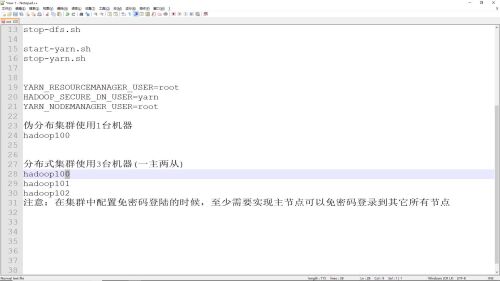
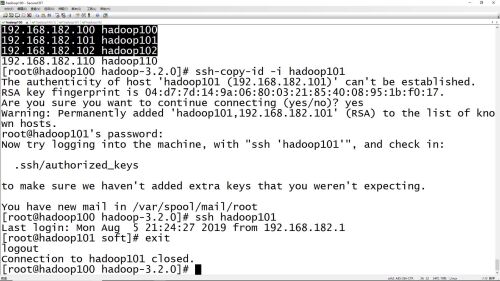 查看全部
查看全部 -
sbin/stop-all.sh停掉集群命令
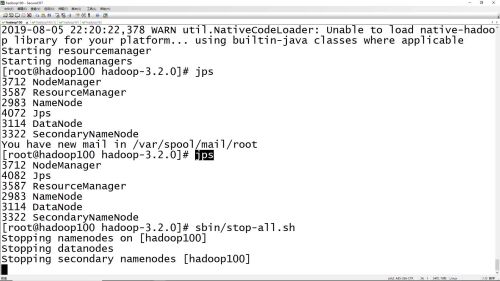 查看全部
查看全部 -
window /etc/host配置hadoopip
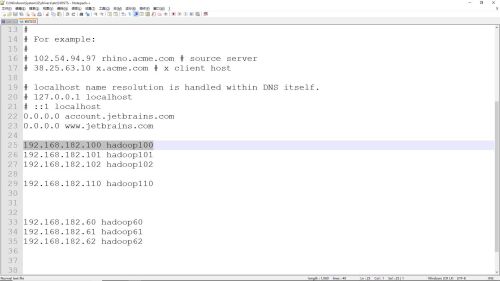 查看全部
查看全部 -
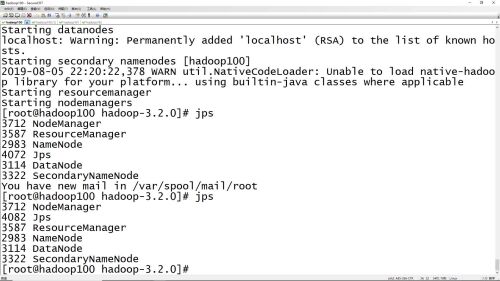
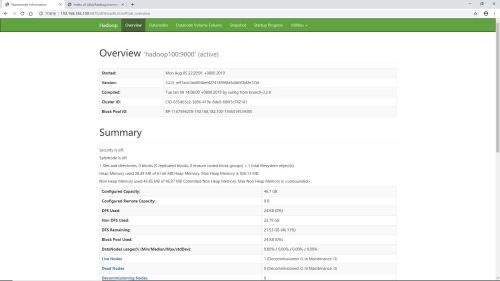
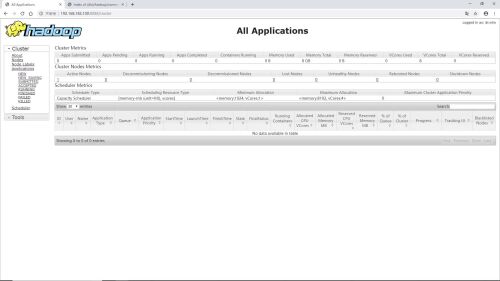
集群安装成功标识
 查看全部
查看全部 -
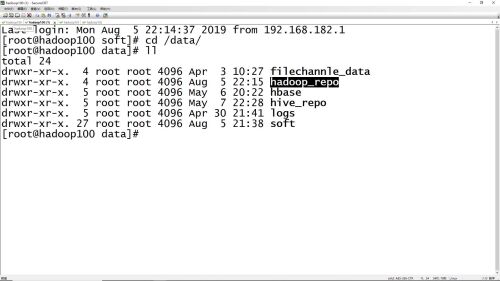
初始化失败,要先删掉hadoop_repo文件在重新初始化
 查看全部
查看全部 -
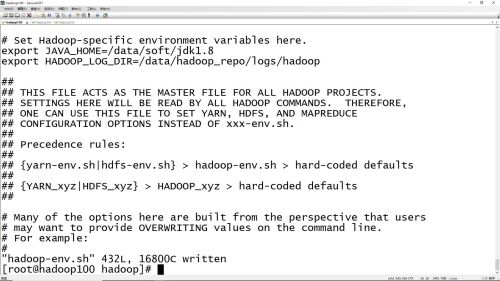
hadoop-env.sh环境变量文件修改
 查看全部
查看全部 -
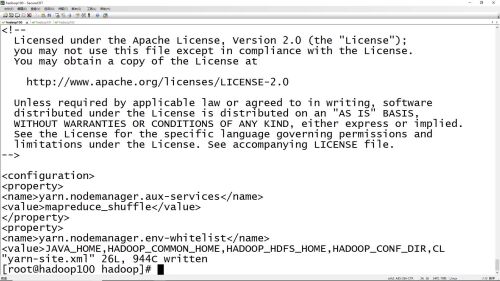
yarn-size.xml配置文件修改
 查看全部
查看全部 -
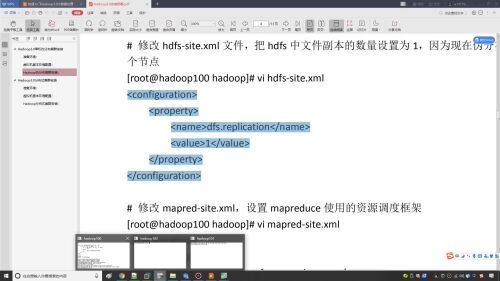
修改mapred-size.xml配置文件
查看全部 -
修改hdfs-size.xml文件
 查看全部
查看全部 -
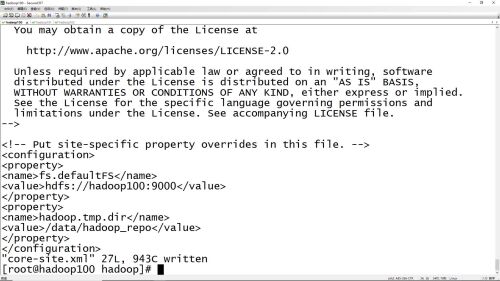
修改配置文件core-site.xml
 查看全部
查看全部

举报
0/150
提交
取消