
是不是有时星球内容太多刷不过来?是不是想把星球精华内容撸下来做个电子书?
本文就带你实现用 Python 抓取星球内容,并生产 PDF 电子书。
先上效果:

内容基于 https://github.com/96chh/crawl-zsxq 进行的优化,主要优化内容在于,翻页时间的处理、大段空白处理、评论抓取、超链接处理等。
涉及到隐私问题,这里我们以免费星球「万人学习分享群」为爬取对象。
过程分析
模拟登录
爬取的是网页版知识星球,https://wx.zsxq.com/dweb/。
这个网站并不是依靠 cookie 来判断你是否登录,而是请求头中的 Authorization 字段。
所以,需要把 Authorization,User-Agent 换成你自己的。(注意 User-Agent 也要换成你自己的)
一般来说,星球使用微信扫码登录后,可以获取到一个 Authorization,这个歌有效期很长反正,真的很长。
headers = {
'Authorization': 'C08AEDBB-A627-F9F1-1223-7E212B1C9D7D',
'x-request-id': "7b898dff-e40f-578e-6cfd-9687a3a32e49",
'accept': "application/json, text/plain, */*",
'host': "api.zsxq.com",
'connection': "keep-alive",
'referer': "https://wx.zsxq.com/dweb/",
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
}页面内容分析
登录成功后,一般我习惯右键、检查或者查看源代码。
但是这个页面比较特殊,它不把内容放到当前地址栏 URL 下,而是通过异步加载(XHR),只要找对接口就可以了。
精华区的接口:https://api.zsxq.com/v1.10/groups/2421112121/topics?scope=digests&count=20
这个接口是最新 20 条数据的,还有后面数据对应不同接口,这就是后面要说的翻页。
制作 PDF 电子书
需安装模块:
wkhtmltopdf,用作导出 PDF,安装完成后可用命令生成 PDF,例如:
wkhtmltopdf http://www.google.com.hk google.pdfpdfkit,是 python 对 wkhtmltopdf 调用的封装,支持 URL、本地文件、文本内容到 PDF 的转换,实际转换还是最终调用 wkhtmltopdf 命令
本来精华区是没有标题的,我把每个问题的前 6 个字符当做标题,以此区分不同问题。
爬取图片
很明显,在返回的数据中的 images 键就是图片,只需提取 large 的,即高清的 url 即可。
关键在于将图片标签 img 插入到 HTML 文档。我使用 BeautifulSoup 操纵 DOM 的方式。
需要注意的是,有可能图片不止一张,所以需要用 for 循环全部迭代出来。
if content.get('images'):
soup = BeautifulSoup(html_template, 'html.parser') for img in content.get('images'):
url = img.get('large').get('url')
img_tag = soup.new_tag('img', src=url)
soup.body.append(img_tag)
html_img = str(soup)
html = html_img.format(title=title, text=text)制作精美 PDF
通过 css 样式来控制字体大小、布局、颜色等,详见 test.css 文件。
再将此文件引入到 options 字段中。
options = { "user-style-sheet": "test.css",
...
}难点分析
翻页逻辑
爬取地址是:{url}?scope=digests&count=20&end_time=2018-04-12T15%3A49%3A13.443%2B0800
路径后面的 end_time 表示加载帖子的最后日期,以此达到翻页。
这个 end_time 是经过 url 转义了的,可以通过 urllib.parse.quote 方法进行转义,关键是找出这个 end_time 是从那里来的。
经过我细细观察发现:每次请求返回 20 条帖子,最后一条贴子就与下一条链接的 end_time 有关系。
例如最后一条帖子的 create_time 是 2018-01-10T11:49:39.668+0800,那么下一条链接的 end_time 就是 2018-01-10T11:49:39.667+0800,注意,一个 668,一个 667 , 两者相差,于是我们便得到了获取 end_time 的公式:
end_time = create_time[:20]+str(int(create_time[20:23])-1)+create_time[23:]
不过事情没有那么简单,因为上一个 create_time 有可能是 2018-03-06T22%3A29%3A59.000%2B0800,-1 后出现了负数!
由于时分秒都有出现 0 的可能,看来最好的方法是,若出现 000,则利用时间模块 datetime 获取 create_time 的上一秒,然后在拼接 999。
# int -1 后需要进行补 0 处理,test_str.zfill(3)end_time = create_time[:20]+str(int(create_time[20:23])-1).zfill(3)+create_time[23:]# 时间出现整点时需要特殊处理,否则会出现 -1if create_time[20:23] == '000':
temp_time = datetime.datetime.strptime(create_time, "%Y-%m-%dT%H:%M:%S.%f+0800")
temp_time += datetime.timedelta(seconds=-1)
end_time = temp_time.strftime("%Y-%m-%dT%H:%M:%S") + '.999+0800'end_time = quote(end_time)
next_url = start_url + '&end_time=' + end_time处理过程有点啰嗦,原谅我时间后面的 000 我没找到直接处理的办法,只能这样曲线救国了。
判断最后一页
翻页到最后返回的数据是:
{"succeeded":true,"resp_data":{"topics":[]}}故以 next_page = rsp.json().get('resp_data').get('topics') 来判断是否有下一页。
评论爬取
发现评论里也有很多有用的内容,评论的格式如下:
{ "comment_id": 15118288421852, "create_time": "2018-08-16T16:19:39.216+0800", "owner": { "user_id": 1484141222, "name": "xxx", "alias": "xxx", "avatar_url": "https://images.xxx"
}, "text": "他这个资源不做投资才傻", "likes_count": 0, "rewards_count": 0, "repliee": { "user_id": 484552118, "name": "Kiwi", "avatar_url": "https://images.zsxqxxxTRQKsci9Q="
}
}我们主要解析其中的 owner.name 和 text,其他信息我们暂时不关心,比如是对谁谁谁的回复,我们暂时只把评论列举出来。
# 评论解析comments = topic.get('show_comments')
comments_str = ''if comments: for comment in comments:
comments_str += comment.get('owner').get('name') + " : " + handle_link(comment.get('text'))
comments_str += '<br><br>'最终评论展示效果:

优化
中文问题
生成 PDF 后,打开发现中文全部显示为方框,如下图:
这表示服务器未安装中文字体,安装字体即可,安装下面说明;
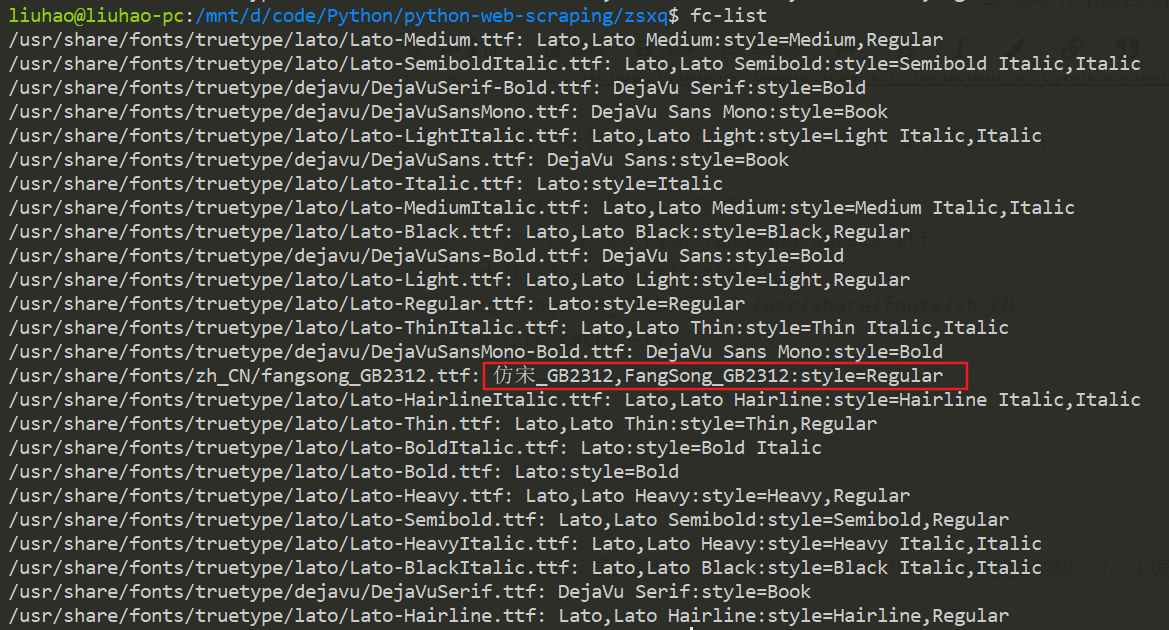
查看目前安装字体:fc-list
下载所需字体,例如 fangsong_GB2312.ttf
mkdir /usr/share/fonts/zh_CN
cp fangsong_GB2312.ttf /usr/share/fonts/zh_CN
执行fc-cache -fv
查看是否安装成功:fc-list,查看是已安装
重新生成后,一切 OK:

页面空白优化
生成成功,但是返现每篇文章默认都是新的一页,出现大块空白,阅读时非常别扭,于是我想着是否可以进行优化。
之所以是一篇星球推文显示成单独的一页,是因为原作者处理时,是将推文分别保存成 HTML 文件进行处理,然后再转换成 PDF。
那么我的思路就是,将每篇推文放在单独的 <body> 里,最后合并成一个 HTML,这样最终显示的就是连续的页面了。
修改前:

修改后:

超链接优化
在原作者的代码中,没有对超链接进行处理,而星球中有大部分都是进行超链接的分享。

没有处理的原因是,抓取到的代码中,超链接是这种形式的:
<e type="web" href="https%3A%2F%2Fmp.weixin.qq.com%2Fs%2Fw8geobayB8sIRWYcxmvCSQ" title="5000%E5%AD%97%E9%95%BF%E6%96%87%E5%91%8A%E8%AF%89%E4%BD%A0%EF%BC%8CSEO%E6%AF%8F%E6%97%A5%E6%B5%81%E9%87%8F%E5%A6%82%E4%BD%95%E4%BB%8E0%E5%88%B010000%2B" cache="http%3A%2F%2Fcache.zsxq.com%2F201808%2F732760494981a6500d8aadf0469efbf205c21d23ca472826f13e127799973455"/>
发现是用 <e> 标签包围的,这不是 HTML 原生标签,所以导致无法解析,进而页面也无法展示,我们要做的就是从中解析出超链接内容,并拼接成 HTML 中的超链接。
另外,发现超链接的 URL 是转码后的内容,我们也需要对其进行处理。
这部分的处理代码如下:
# 对文本进行 URL 解码,要不后面解析处理也无法点击def handle_link(text):
# 星球中用 <e> 表示超链接
# 这里我们进行转换
soup = BeautifulSoup(text,"html.parser")
links = soup.find_all('e', attrs={'type':'web'}) if len(links): for link in links:
title = link.attrs['title']
href = link.attrs['href']
s = '<a href={}>{} </a>'.format(href,title)
text += s
# 清理原文中的 <e> 标签
# 这里不清理也没问题,HTML 解析不了,页面也不会显示
# 但是,强迫症。
text = re.sub(r'<e[^>]*>', '', text).strip() return text处理后:

当然,最好的方式是把超链接的内容也爬取出来,一并放在 PDF 里,这里我就不搞了,有兴趣的尝试下吧。
换行处理
换行在星球上显示是这样的:
但是到 PDF 后,换行全部没了,大段文字看起来很费劲:

这个处理起来就比较简单了,只要将返回数据中的 \n 替换为 HTML 中的换行标签 <br> 即可:
例如获取精华正文时:
text = handle_link(unquote(content.get('text', '').replace("\n", "<br>")))需要注意的是,需要在解码之前进行替换。
效果:

共同学习,写下你的评论
评论加载中...
作者其他优质文章



