
前段时间一直在忙碌写毕设与项目的事情,很久没有写一些学习心得与工作记录了,开了一个新的坑,希望能继续坚持写作与记录分布式存储相关的知识。为什么叫小视角呢?因为属于随想型的内容,可能一个由小的视角来审视海量数据的存储与计算技术,把知识点分为两到三章来梳理。管中窥豹,可见一斑,希望能利用这个过程提高自己,也欢迎阅读的朋友多指正。 第一章先从Facebook的一篇论文《RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems》展开,来聊一聊存储格式的变迁,来看看如何因地制宜的让海量数据适应计算需求。上车,上车~~
1.数据存储格式
数据的布局结构深刻的影响着数据处理的效率与性能,在底层的存储系统之中如何组织数据。如何对数据进行布局会直接影响数据查询引擎的设计与实现,并且也影响着存储空间的利用效率。好的数据存储与布局能够更好的利用好存储空间,并且契合业务应用场景的查询实践。接下来,我们来看看存储数据的格式是如何随着数据需求的不同进行变迁的。
在传统的数据库系统之中,衍生出了一下几种数据的布局结构:
(1)水平行存储结构
(2)垂直列存储结构
(3)混合PAX存储结构
这几种数据布局方式各有优点与缺陷,我们来一步一步梳理看看:
2.水平的行存储结构
行存储在传统的的数据库之中占据主导地位,例如MySQL的MyISAM的MYD文件,innodb的idb文件,Hive之中的Sequence文件,都是通过行存储来实现的。如下图所示,各个数据记录被组织在一个n元存储模型之中,数据记录是一个接一个地按顺序排列的: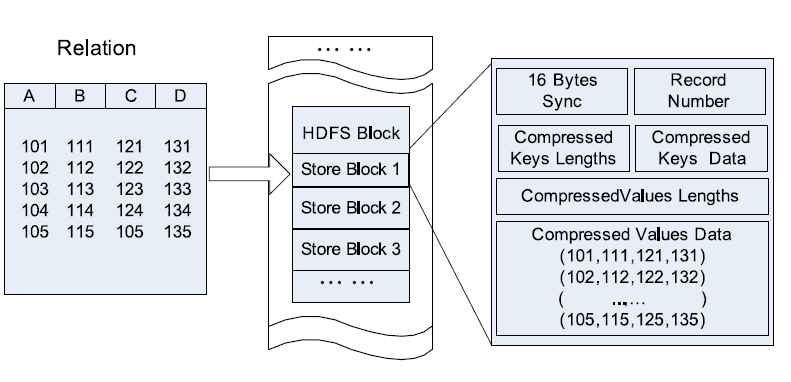
当然,这样的存储布局方式的优点是:因为每行的数据都共同存放,所以单行的数据加载快速,很适合OLTP数据库的增删改查。
而在另一方便,缺点也十分明显,就是不适用于海量数据的存储的OLAP的应用场景:
(1)当仅仅对单个列,或少量列进行数据处理时,需要读取额外许多不必要的数据,会产生极大的性能损耗。因为每次都加载了不必要的列,导致缓存被塞满无用的数据,并且随着数据量的增加,这种损耗是成倍增加的。
(2)行存储的数据相似性很低,很难实现较高的数据压缩比例,所以相对来说也比较占用存储空间。
所以行存储并不适用于海量数据的分析查询,由行存储便衍生出新的存储模式。
3.垂直的列存储结构
列存储结构可以避免行存储结构的缺点:在实际的数据读取过程中可以避免读取不必要的列。而且由于同一列的数据时共同存储的,可以轻松地实现高的压缩比例来达到节省空间的目的。
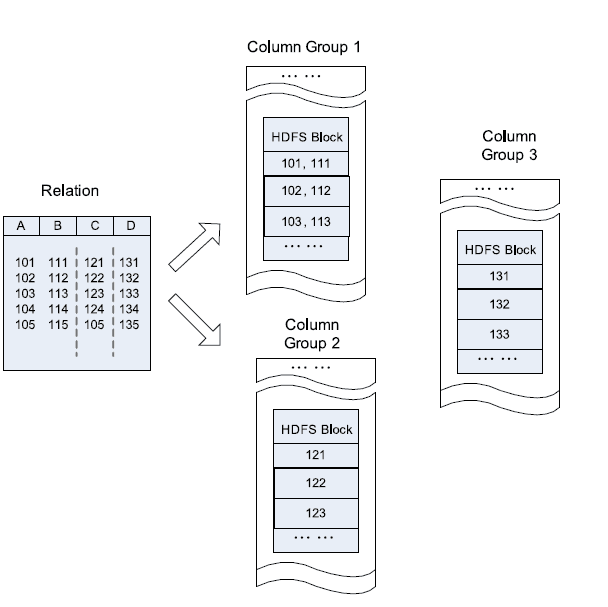
天下没有免费的午餐,既然列存储提供了许多优秀的特性,它自然也带来了它自身的缺点,如上图所示:当需要对单行进行查询处理时,列存储不能保证所有字段都存在同一个datanode之上,通常对于一个大表来说也是不可能的事情。在上图之中,同一条记录的四个字段,分别位于不同的三个HDFS块之中,这些块很可能就分布在不同的datanode之上,因此,对于行的读取将会占用集群大量的带宽资源。
更加麻烦的地方在于:当数据删除时,由于不同的数据列分布在不同的数据节点,所以需要同步多个数据节点之上的数据,由此引发的一致性问题是十分棘手的.
所以尽管列存储适用于单机的数据分析查询,但是当海量数据存放在分布式存储系统之上时,列存储似乎也要付出更多的代价。
4.混合PAX存储结构
行存储面对数据记录的访问具有灵活性,但是缓存利用能力差,数据压缩能力差。
列存储显然I/O性能更好,数据压缩能力强,但是对于单行数据的处理在分布式环境之下表现也不近人意。
好吧,你俩都不错,那就结合一下试一试,所以就引申出下文要聊的:混合PAX存储结构
PAX最早是一种改进CPU缓存的混合布局结构,通过对于具有多个不同字段的记录进行优化来提高缓存的性能。PAX利用一个缓存页面来存储属于每个字段的所有字段,并且布局它们的分布。(相当于元数据)
同样的,我们也可以利用这种混合布局的思路,来结合行存储与列存储的优点,由Facebook设计的Record Columnar File(RCFile)就借鉴了PAX存储模型,通过先进行水平分区,再垂直分区的方式保证了同一行的数据一定在同一个datanode,同时在单个datanode之上又利用行存储来优化数据的查询与存储性能。
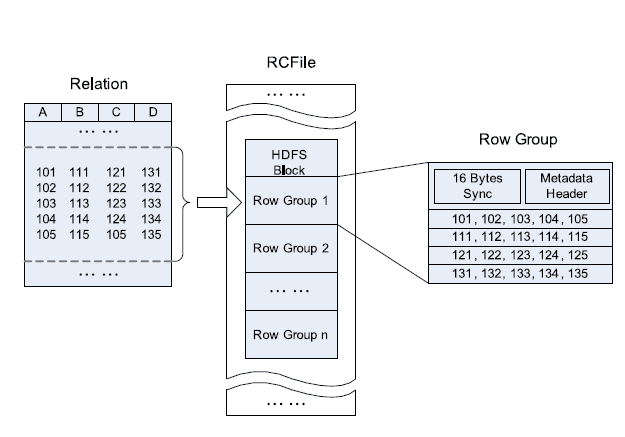
如上图所示,在RCFile之中,在每个HDFS的数据块之上,数据Row Group进行排列。每个Row Group包含了三部分:
数据分隔标志
元数据(元数据存储了该Row Group有许多记录,有多少字节。在每个列之中有多少字节)
列式存储数据 (实际存储数据的内容,不同的列可以使用不同的压缩算法来最大程度的压缩数据的存储空间)
写到这里想必大家都对RCFile有充分的了解了,我们接下来借着RCFile论文的部分再谈两个细节的问题:
懒解压:
举个栗子:假如说有如下查询 :select a from table where a > 1 ;
懒解压意味着列不一定在内存中解压缩,直到执行单元确定列中的数据需要处理才会对数据进行解压。懒解压十分适合条件查询的应用场景,如果有条件不能满足行组中的所有记录,则不需要进行数据解压,这样可以大大减少内存和CPU的占用。
例如,在上述查询中,如果该Row Group之中所有的a都小于或等于1,则没必要对Row Group的内容进行解压,可以直接跳过。当然,这里就需要依赖元数据的内容了。
Row Group的size:
显然,越大的Row Group更有利于数据的压缩处理,但是显然过大的数据存储容量会影响上文提到的懒压缩的性能。妹子的胸也不是越大越好的,所以最终Facebook选择了4MB的Row Group大小。(记住这个问题,后续我们还会回来再谈这个问题的)
5.小结:
本文主要是从数据的布局角度梳理了由行存储到RCFile的演变,分析了各种存储布局模式所合适的场景。下一篇我们将继续探讨这个问题,来看看ORCFile与Parquet的是如何更进步来解决大规模OLAP应用的数据存储格式的。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



