
前言:从去年3月份入职到现在刚好一年半,在这一年半的时间里一直负责部门的资源服务开发与搭建,由于公司战略的调整我负责的这个服务需要交接到别的部门。因为在负责服务的一年半中遇到太多太多坑,也受到太多的批评和质疑,不过很幸运自己坚挺下来了,服务日访问量也由刚接手时候的8千变成2.0亿,业务方也扩大近一倍,今天我在这里把所有的经验与大家分享,希望大家以后在做服务时候少走弯路。
一:基础服务应该考虑的事项
1、基础服务的定义
当接手一个新服务的时候我们就必须搞明白下面2件事:
这个服务的定位
这个服务承担的职责
我在工作中有次领导突然问我你能告诉我资源服务是什么吗,当时我有点晕圈,半天没有回答出来,因为我一直在根据业务方需求或者pm来开发自己玩去处于一个被动的角色,所以那次对话给我带来的震惊挺大的。从那以后我就经常想我的服务是什么,后来就明白了它就是一个基于资源的库存系统,既然是库存系统那么它应该具有哪些能力呢,无非就是添加、消耗、返点、冻结、解冻、转账等功能,当我们明白这些功能后我们就清楚哪些是我们开发所承担的能力,哪些不属于我们承担的能力,以至于后期我对我的服务进行大量解耦(比如一个用户想获取资源还进行判断是不是会员,其实他并不属于我们服务职责,那么类似这样的业务需求我们就应该果断抛给业务方)
2、基础服务的文档
我在做服务的初期并不存在文档,但是慢慢发现文档在整个服务中也处于一个非常重要的角色,因为新每个业务方需要接入服务的时候你不能每次都直接口述,那样会耽误太多精力,而且很多接入服务出现的问题没有文档的记录也可能会丢失,这样一来新接入的业务方可能会出现同样的问题,为我们开发带来大大的不便(文档最好是准备2份,一份用wiki写接入文档,另一个是接口文档)。下面总结下wiki文档主要的内容
服务专业名字解释
服务负责人以及联系方式
服务配置说明(如版本号、沙箱ip等)
服务接口说明
服务调用demo
常见问题说明
3、服务的性能
性能是每个服务都需要关注的点,但是我们在设计服务初期就应该有一个性能指标,比如我们操作接口平均响应时长控制在30ms以内,查询接口响应时长控制在10ms以内(这些指标可以根据业务方的需要来,比如一个下单功能整体要求是500ms可能分到我们提供的接口只有50ms),因为任何性能都是有一定标准的我们就围绕这个标准去打造,性能优化指标可以参考我以前的一篇文章(https://www.cnblogs.com/LipeiNet/p/6379579.html)
4、服务的高可用
服务的高可用可以采取负载均衡来保证一台机器宕机从而不影响整体,目前我们并没有采用技术方面来保证高可用
4、服务的并发
并发基本大多服务都会面临,一旦服务出现并发很可能造成了数据安全性出现问题,比如我们服务A用户请求资源然后进行消耗,同一时间A用户继续请求资源进行消耗,那么导致的后果就是A消耗了2次资源但是只扣一次点,这样一来服务就是出现问题,解决这个问题通常我们采用锁,锁主要分2种乐观锁和悲观锁。
悲观锁:认为所有的请求都会发生并发,所以悲观锁会对每一个请求加锁,单点常用的悲观锁有synchronized和lock,具体这两种锁区别大家可以自己百度,当然另外如果服务是分布式的,那么就需要采用分布式锁,常用的分布式锁有基于redis和Zookeeper来实现的,我们这边采用的是基于redis锁,因为对性能要求比较高
乐观锁:认为所有的请求都不会发送并发,一般常用cas锁来解决,就是先比后更的模式。如对数据加入版本号,获取数据时候记录版本号,如果更新时的版本号和获取时不一致则抛出异常
5、服务的一致性
服务一致性我在这里来说明2种情况,一种是服务本身数据的一致性,另外是和调用方保持一致性.
调用方保持一致性:
我们服务提供幂等,当调用方出现超时或异常在次调用服务我们将会返回订单重复提交,调用方可以根据返回值来判断这个操作对自己业务而言是否是正确的.幂等我们服务采用的是永久性幂等,这样做法其实有缺陷,因为量级太大会占用很大的数据库资源,所以可以优化成对于添加采用永久性幂等,而一些消耗采用非永久性幂等,这样一来就可以对幂等数据做归档,就会减少数据库资源的利用。
服务本身一致性:
这个就是我们常说的一致性,我们现在并没有完全解决这个问题,目前我对于跨单消耗我采用的是占位思想进行解决,也就是先会更新资源然后出现异常进行返点。并没有采用最终一致性来解决,因为最终一致性会出现数据被多扣,比如我得资源第一次扣除失败然后放入队列,在队列进行扣除,但是恰恰新的请求过来同样会获取这条资源进行扣除,这样一来就出现数据安全问题,目前我们采用的是三次重试,所以严格来讲我们服务的一致性并没有完全解决.关于一致性问题在以后的文章会继续和大家聊。
6、服务的接入方
当业务方需要调用我们服务的时候自己一定慎重搞不好就掉坑里了,下面我说2个例子
第一个例子:
有一个业务方告诉我们他们要做活动需要每天添加资源,然后我就问了他每天的量级,经过评估后我发现量级没太大问题,但是当我要审批的时候发现有新的问题,因为活动期间添加资源会出现大量零碎的订单,如果过期时间过久那么可能数据库每种资源达到几百或者上千条,那么带来的后果就是我们在查询或者消耗时候会非常慢,而且以前因为查询过多订单导致服务超时问题,所以后续我们就这问题沟通,他们要过期时间设置1个月,然后我在做压力测试确认无误后才审批。
第二个例子:
我们提供定制化接口给业务方,这个给我们带来了特别多痛,我们提供一个消耗接口,但是这个业务方需要消耗详情,我们同样提供了,这样就导致他的消耗和别人不一样,做技术升级的时候还需要单独考虑这个接口,因为我的忽略导致几次没有考虑清楚都出现线上事故,后来我们去问他们要消耗详情干嘛,他说他业务其实不用需要把这些消耗详情存入他们的库,我们听后觉得特别无语,这样的数据直接走离线数据即可,这也是早期没聊明白需求导致一个毒瘤接口。
综上总结:
1、业务方的需求我们必须聊清楚,明白我们服务应该提供的能力,对于不合理的需求直接拒绝
2、拒绝提供定制化的接口,如果某个业务方需求影响整体同样我们必须拒绝或者找到其他兼容方案
3、对于每次业务方的接入必须邮件写的非常明白包括背景、量级、QPS等
二:基础服务过程中case汇总
1、数据迁移和数据转换引发事故
关于数据迁移和转换引起的事故请参考这篇文章https://www.cnblogs.com/LipeiNet/p/7809567.html
2、线上操作数据库表结构引发的事故
关于这个事故请查看这篇文章https://www.cnblogs.com/LipeiNet/p/9182454.html
3、重构引发的线上事故
重构我们一共出过两次事故,一个代码整合,一个是删除已废弃逻辑.
代码整合带来的问题:
背景:
刚进入公司的时候我看到项目中有大量代码重复,就想着重构,把相同的代码用函数的方式合并,最后经过审批后也这么干了,但是上线以后一线反馈自己添加的资源无法查询,最后排查日志中发现在重构代码中有一处代码的资源订单的开始生效日期是当前日期并不采用用户传入的日期。
删除已废弃逻辑带有的问题:
背景:
由于我们服务的和外部服务解耦其中的一个数据库字段被废弃,所以我们在代码中去除掉这个字段的逻辑信息,上线后业务方反馈资源消耗异常,排查后我们发现返回实体中去除字段应该是0但是我们去掉逻辑后变成null,这样一来别的业务方判断空指针异常
综上总结:
1、项目重构前一定另外拉分支,修改项目的版本号,便于回滚
2、严格测试,用测试账号测试线上接口保留返回值,然后同样的操作用于被重构后的接口,比对连个返回值是否相同,如果不同,那么就需要弄明白是否对线上业务造成影响
4、慢查询引发的线上事故
一次我上线了一个查询接口,但是不久被反馈线上服务部分出现超时,经过排查后发现sql的字段没有加索引。
总结:当我们上线新的服务时候必须经过沙箱严格测试包括性能指标。
5、内外部实体未解耦引发的线上事故
背景:
我们在新开发一个功能的时候在数据库中增加了一个int类型的字段,而这个字段主要用于服务内部,并不会对外进行提供,但是在更新库存的时候并没有分离内外部实体,然后在更新的时候讲这个字段值覆盖成为0导致了线上的bug。
修复过程:
内外部实体彻底解耦,内部接口不采用任何外部接口进行传输
综上总结:
设计阶段:
设计阶段明确内外部实体的职责,内外部实体不必保持一致,外部实体主要传输业务方需要的字段(具有业务含义)而内部实体需要和数据库字段保持一致。
升级阶段:
升级内部逻辑:
有时候因为某些原因我们需要进对内部服务升级,这个时候我们一定要注意是否在内部服务中采用了外部实体进行传输,如果有进行外部实体进行传输的就一定注意更改内部实体影响业务方,如果时间准许应该进行内外部实体进行解耦
某个业务方需求:
如果某一个业务方有特殊需求涉及属性的更改,这个时候考虑这个需求是否合理,是否应该我们服务提供的能力,如果可以通过配置化规则来解决,如果解决不了然后升级服务版本,对返回值进行升级,但是内部一定要注意不要影响其他业务方调用
所有业务方需求:
更新pom版本升级服务,统计所有的调用方,让调用方进行升级
6、持久层捕获异常引发的线上事故
背景:
持久层捕获异常并没有抛出
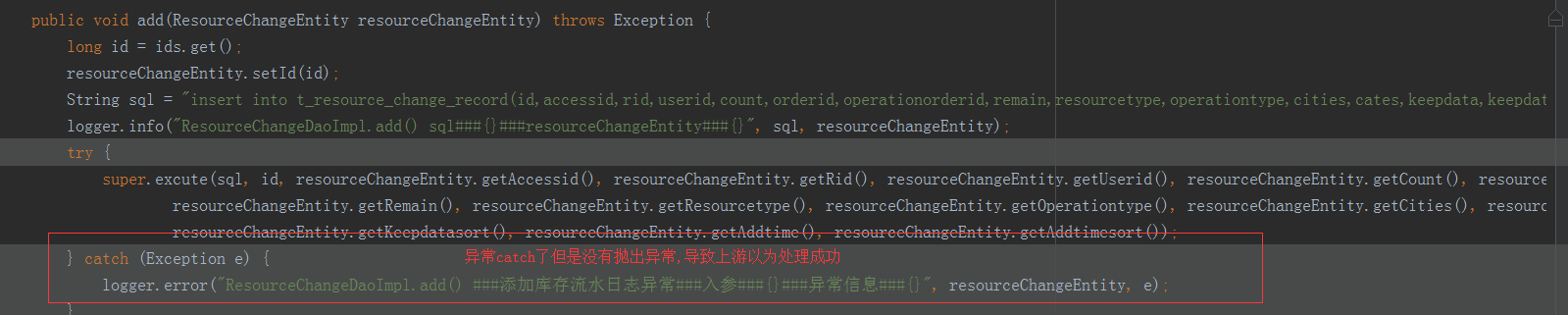
综上总结:
持久层中尽量不进行异常捕获,如果需要捕获接口中必须要有返回值
7、枚举使用不当引发的线上事故
详情请查看https://www.cnblogs.com/LipeiNet/p/9487900.html
8、限流把控不严引起业务方资源无法添加
背景:某个业务方用MQ异步调用我们的服务,但是他们是刷数据所以短时间内流量特别大,因为我们服务的限流这样一来就出现大量的数据添加异常。
问题分析:主要出现这样的问题原因有下面2个
1、业务方定时处理数据的时候没能周知我们
2、我们并没有把流量进行削峰
综上总结:
1、在服务文档上特别加上业务方定时跑数据时候提前邮件周知最大QPS,数据的量级以及操作时间
1、采用流量削峰,避免短时间的流量过来造成业务异常,主要做法将短时间多出的流量存储在MQ端,如果出现一定量级采用报警
原文出处:https://www.cnblogs.com/LipeiNet/p/9627440.html
共同学习,写下你的评论
评论加载中...
作者其他优质文章



