
一、Python 模块简介
在开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在 Python 中,一个 .py 文件就称之为一个模块(Module)。
之前我们学习过函数,知道函数是实现一项或多项功能的一段程序 。其实模块就是函数功能的扩展。为什么这么说呢?那是因为模块其实就是实现一项或多项功能的程序块。
通过上面的定义,不难发现,函数和模块都是用来实现功能的,只是模块的范围比函数广,在模块中,可以有多个函数。
竟然了解了什么是模块了,那么为什么需要模块呢?竟然有了函数,那为啥那需要模块?
最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括 Python内置的模块和来自第三方的模块。
使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
Python 本身就内置了很多非常有用的模块,只要安装完毕,这些模块就可以立刻使用。我们可以尝试找下这些模块,比如我的 Python 安装目录是默认的安装目录,在 C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36 ,然后找到 Lib 目录,就可以发现里面全部都是模块,没错,这些 .py 文件就是模块了。
python36bin目录
其实模块可以分为标准库模块和自定义模块,而刚刚我们看到的 Lib 目录下的都是标准库模块。
二、模块的使用
1、import
Python 模块的使用跟其他编程语言也是类似的。你要使用某个模块,在使用之前,必须要导入这个模块。导入模块我们使用关键字 import 。
import 的语法基本如下:
import module1[, module2[,... moduleN]
比如我们使用标准库模块中的 math 模块。当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
#!/usr/bin/env python3# -*- coding: UTF-8 -*-
import math
_author_ = '两点水'
print(math.pi)
输出的结果:
3.141592653589793
一个模块只会被导入一次,不管你执行了多少次 import。这样可以防止导入模块被一遍又一遍地执行。
当我们使用 import 语句的时候,Python 解释器是怎样找到对应的文件的呢?
这就涉及到 Python 的搜索路径,搜索路径是由一系列目录名组成的,Python 解释器就依次从这些目录中去寻找所引入的模块。这看起来很像环境变量,事实上,也可以通过定义环境变量的方式来确定搜索路径。搜索路径是在 Python 编译或安装的时候确定的,安装新的库应该也会修改。搜索路径被存储在sys 模块中的 path 变量 。
因此,我们可以查一下路径:
#!/usr/bin/env python# -*- coding: UTF-8 -*-
import sys
print(sys.path)
输出结果:
['C:\\\\Users\\\\Administrator\\\\Desktop\\\\Python\\\\Python8Code', 'G:\\\\PyCharm 2017.1.4\\\\helpers\\\\pycharm', 'C:\\\\Users\\\\Administrator\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36\\\\python36.zip', 'C:\\\\Users\\\\Administrator\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36\\\\DLLs', 'C:\\\\Users\\\\Administrator\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36\\\\lib', 'C:\\\\Users\\\\Administrator\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36', 'C:\\\\Users\\\\Administrator\\\\AppData\\\\Local\\\\Programs\\\\Python\\\\Python36\\\\lib\\\\site-packages', 'C:\\\\Users\\\\Administrator\\\\Desktop\\\\Python\\\\Python8Code\\\\com\\\\Learn\\\\module\\\\sys']
2、from...import
有没有想过,怎么直接导入某个模块中的属性和方法呢?
Python 中,导入一个模块的方法我们使用的是 import 关键字,这样做是导入了这个模块,这里需要注意了,这样做只是导入了模块,并没有导入模块中具体的某个属性或方法的。而我们想直接导入某个模块中的某一个功能,也就是属性和方法的话,我们可以使用 from...import 语句。
语法如下:
from modname import name1[, name2[, ... nameN]]
看完简介后可能会想, from...import 和 import 方法有啥区别呢?
想知道区别是什么,观察下面两个例子:
import 导入 sys 模块,然后使用 version 属性
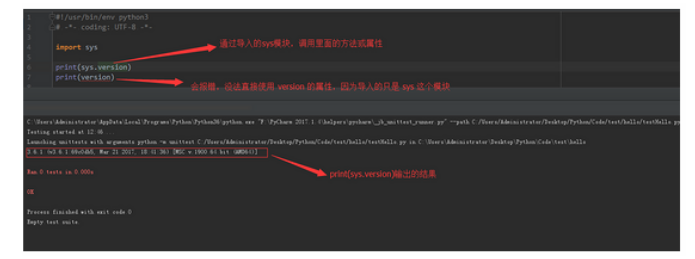
from...import和 import的区别1
from...import 直接导入 version 属性
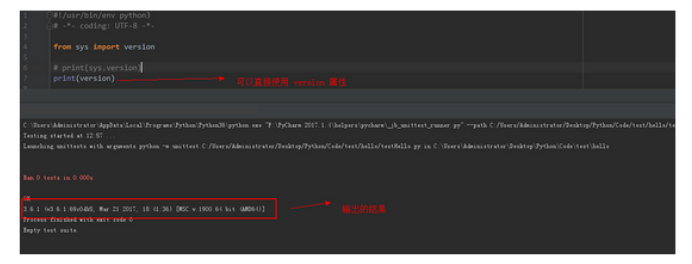
from...import和 import的区别2
3、from ... import *
通过上面的学习,我们知道了 from sys import version 可以直接导入 version 属性。但是如果我们想使用其他的属性呢?比如使用 sys 模块中的 executable ,难道又要写多一句 from sys import executable ,两个还好,如果三个,四个呢?难道要一直这样写下去?
这时候就需要 from ... import * 语句了,这个语句可以把某个模块中的所有方法属性都导入。比如:
#!/usr/bin/env python3# -*- coding: UTF-8 -*-
from sys import *
print(version)
print(executable)
输出的结果为:
3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)]C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\python.exe
注意:这提供了一个简单的方法来导入一个模块中的所有方法属性。然而这种声明不该被过多地使用。
三、主模块和非主模块
1、主模块和非主模块的定义
在 Python 函数中,如果一个函数调用了其他函数完成一项功能,我们称这个函数为主函数,如果一个函数没有调用其他函数,我们称这种函数为非主函数。主模块和非主模块的定义也类似,如果一个模块被直接使用,而没有被别人调用,我们称这个模块为主模块,如果一个模块被别人调用,我们称这个模块为非主模块。
2、name属性
在 Python 中,有主模块和非主模块之分,当然,我们也得区分他们啊。那么怎么区分主模块和非主模块呢?
这就需要用到 __name__ 属性了,这个 ——name—— 属性值是一个变量,且这个变量是系统给出的。利用这个变量可以判断一个模块是否是主模块。如果一个属性的值是 __main__ ,那么就说明这个模块是主模块,反之亦然。但是要注意了: 这个 __main__ 属性只是帮助我们判断是否是主模块,并不是说这个属性决定他们是否是主模块,决定是否是主模块的条件只是这个模块有没有被人调用
具体看示例:
首先创建了模块 lname ,然后判断一下是否是主模块,如果是主模块就输出 main 不是,就输出 not main ,首先直接运行该模块,由于该模块是直接使用,而没有被人调用,所以是主模块,因此输出了 main ,具体看下图:
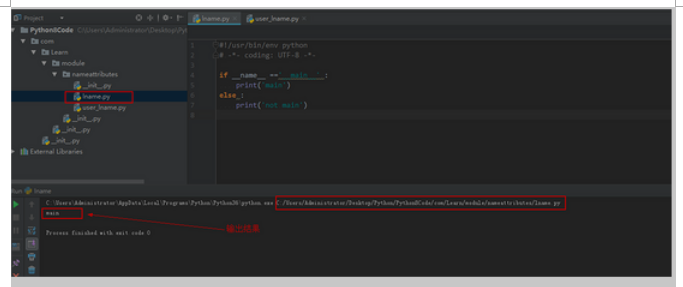
name属性区分模块1
然后又创建一个 user_lname 模块,里面只是简单的导入了 lname 模块,然后执行,输出的结果是 not main ,因为 lname 模块被该模块调用了,所以不是主模块,输出结果如图:
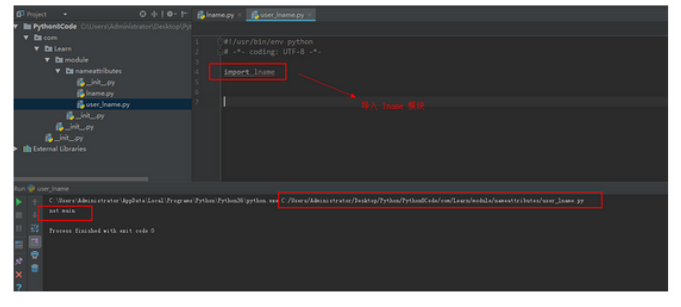
name属性区分模块2
四、包
包,其实在上面的一些例子中,都创建了不同的包名了,具体可以仔细观察。在一开始模块的简介中提到,使用模块可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。但是这里也有个问题,如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python 又引入了按目录来组织模块的方法,称为包(Package)。
比如最开始的例子,就引入了包,这样子做就算有相同的模块名,也不会造成重复,因为包名不同,其实也就是路径不同。如下图,引入了包名后, lname.py 其实变成了 com.Learn.module.nameattributes.lname
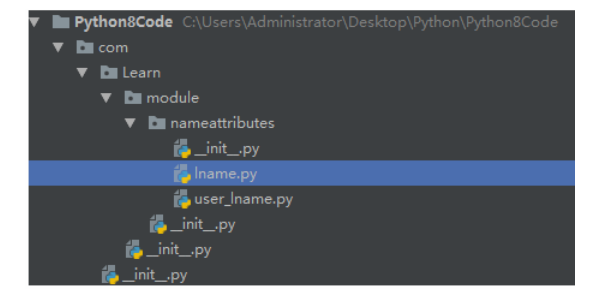
Python 包
仔细观察的人,基本会发现,每一个包目录下面都会有一个 __init__.py 的文件,为什么呢?
因为这个文件是必须的,否则,Python 就把这个目录当成普通目录,而不是一个包 。 __init__.py 可以是空文件,也可以有Python代码,因为 __init__.py 本身就是一个模块,而它对应的模块名就是它的包名。
五、作用域
学习过 Java 的同学都知道,Java 的类里面可以给方法和属性定义公共的( public )或者是私有的 ( private ),这样做主要是为了我们希望有些函数和属性能给别人使用或者只能内部使用。 通过学习 Python 中的模块,其实和 Java 中的类相似,那么我们怎么实现在一个模块中,有的函数和变量给别人使用,有的函数和变量仅仅在模块内部使用呢?
在 Python 中,是通过 _ 前缀来实现的。正常的函数和变量名是公开的(public),可以被直接引用,比如:abc,ni12,PI等;类似 __xxx__ 这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如上面的 __name__ 就是特殊变量,还有 __author__ 也是特殊变量,用来标明作者。注意,我们自己的变量一般不要用这种变量名;类似 _xxx 和 __xxx 这样的函数或变量就是非公开的(private),不应该被直接引用,比如 _abc , __abc 等;
注意,这里是说不应该,而不是不能。因为 Python 种并没有一种方法可以完全限制访问 private 函数或变量,但是,从编程习惯上不应该引用 private 函数或变量。
比如:
#!/usr/bin/env python3# -*- coding: UTF-8 -*-
def _diamond_vip(lv):
print('尊敬的钻石会员用户,您好')
vip_name = 'DiamondVIP' + str(lv)
return vip_name
def _gold_vip(lv):
print('尊敬的黄金会员用户,您好')
vip_name = 'GoldVIP' + str(lv)
return vip_name
def vip_lv_name(lv):
if lv == 1:
print(_gold_vip(lv))
elif lv == 2:
print(_diamond_vip(lv))
vip_lv_name(2)
输出的结果:
尊敬的钻石会员用户,您好
DiamondVIP2
在这个模块中,我们公开 vip_lv_name 方法函数,而其他内部的逻辑分别在 vip_lv_name 和vip_lv_name private 函数中实现,因为是内部实现逻辑,调用者根本不需要关心这个函数方法,它只需关心调用 vip_lv_name 的方法函数,所以用 private 是非常有用的代码封装和抽象的方法
一般情况下,外部不需要引用的函数全部定义成 private,只有外部需要引用的函数才定义为 public。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



