
Hadoop是什么?
Hadoop是一个处理海量数据的开源框架。2002年Nutch项目面世,这是一个爬取网页工具和搜索引擎系统,和其他众多的工具一样,都遇到了在处理海量数据时效率低下,无法存储爬取网页和搜索网页时产生的海量数据的问题。2003年谷歌发布了一篇论文,专门介绍他们的分布式文件存储系统GFS。鉴于GFS在存储超大文件方面的优势,Nutch按照GFS的思想在2004年实现了Nutch的开源分布式文件系统,即NDFS。2004年谷歌发布了另一篇论文,专门介绍他们处理大数据的计算框架MapReduce,2005年初Nutch开发人员在Nutch上实现了开源的MapReduce,这就是Hadoop的雏形。2006年Nutch将NDFS和MapReduce迁出Nutch,并命名为Hadoop,同时雅虎公司专门为Hadoop建立一个团队,将其发展成为能够处理海量数据的Web框架,2008年Hadoop成为Apache的顶级项目。
2007年9月发布hadoop 0.14.1,第一个稳定版本。
2009年4月发布hadoop 0.20.0版本。
2011年12月发布hadoop 1.0.0版本,这是经过将近6年的酝酿后发布的一个版本,该版本基于0.20安全代码线,增加如下的功能:
安全,
Hbase(append/hsynch/hflush和security)
webhdfs(完全支持安全)
增加HBase访问本地文件系统的性能
2.12年5月发布hadoop 2.0.0-alpha,则是hadoop-2.X系列的第一个版本,增加很多重要的特性:
1、NameNode HA(High Availability高可靠性),当主NameNode挂掉时,备用NameNode可以快速启动,成为主NameNode节点,向外提供服务。
2、HDFS Federation。
3、YARN aka NextGen MapReduce。
2017年9月份发布Hadoop 3.0.0 generally版本,这是hadoop 3.x系列的第一个版本。
目前市面上还是以Hadoop2.x系列为主,Hadoop3.x还没正式的运用到生产系统中。
一句话总结:Hadoop是开源的大数据处理框架,分为处理数据的MapReduce和存储数据的HDFS。
Hadoop能做什么?
Hadoop可以用来处理海量数据,对数据进行分析。现在互联网企业每天都产生大量的日志数据,有的甚至达到PB级别,像国外的facebook,twitter,国内的阿里、腾讯、京东、百度等企业。在Haddop没出现之前,都是用小型机处理数据,价格昂贵不说,还耗费时间,Hadoop面世之后,可以使用廉价机器搭建Hadoop集群,一台小型机的价格就可以搭建起一个20个节点的Hadoop集群。2007年雅虎在900个节点的hadoop集群上对1T的数据进行排序只需要209秒,引起业界的关注,从此Haddoop逐渐成为大数据处理的标准,众多厂商纷纷向其靠拢。目前国内的互联网企业对Hadoop的使用都比较成熟,在2015年的时候百度的Hadoop集群就达到4000个节点。
Hadoop的缺点
Hadoop适合处理海量的离线数据,对于处理实时数据却不合适,例如实时股票交易分析。实时海量数据处理目前有比较好的框架,分别是Spark Streaming,Storm,Flink。他们也都是基于Hadoop的基础上实现的,数据Hadoop生态系统中的一员。
Hadoop生态框架
现在我们讲Hadoop,泛指Hadoop生态系统中的各种组件,包括用于构架数据仓库和分析数据的Hive,基于HDFS的列式数据库HBase,实时数据处理框架Flink、Storm、Spark Streaming等。下图是Hadoop的生态系统图。
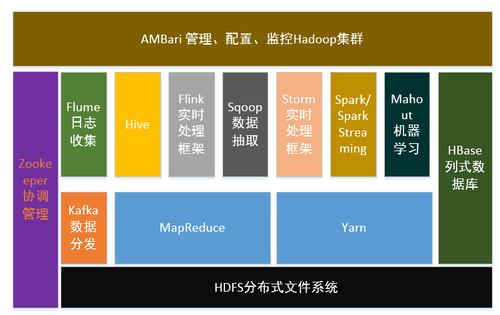
原文出处:https://www.cnblogs.com/airnew/p/9511101.html
共同学习,写下你的评论
评论加载中...
作者其他优质文章



