
1.以下关于盒子模型描述正确的是:( )
A.标准盒子模型中:盒子的总宽度 = 左右margin + 左右border + 左右padding + width
B.IE盒子模型中:盒子总宽度 = 左右margin + 左右border + width
C.标准盒子模型中:盒子的总宽度 = 左右margin + 左右border + width
D.IE盒子模型中:盒子总宽度 = width
分析:盒子模型都是:左右margin + 左右border + 左右padding + width,IE和标准盒子的区别在于content的内容,IE的content包括width和border。
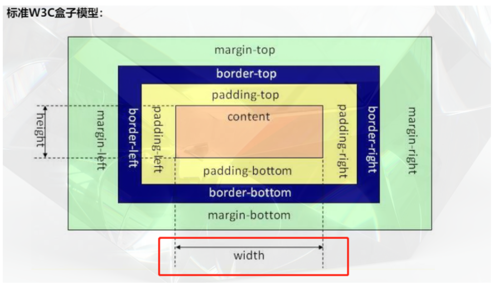
标准W3C盒子模型
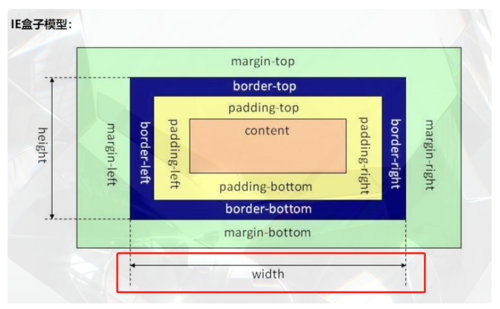
IE盒子模型
2.关于正则表达式声明6位数字的邮编,以下代码正确的是( )
A. var reg = /\d6/;
B. var reg = \d{6};
C. var reg = /\d{6}/;
D. var reg = new RegExp("\d{6}");
分析:炸一看C、D都对,实验后发现new出来的需要对 \ 符号进行转义,正确写法:new RegExp("\\d{6}")。
3.CSS中 link 和@import 的区别是?( )
A、link属于HTML标签,而@import是CSS提供的;
B、页面被加载的时,link会同时被加载,而@import引用的CSS会等到页面被加载完再加载;
C、import只在IE5以上才能识别,而link是HTML标签,无兼容问题;
D、@import方式的样式的权重高于link的权重;
分析:属于XHTML没有任何疑议,主要在于D选项犹豫。1. link方式:写在html文档head里面。2.@import方式:写在css文档里面引入样式表。在自己写栗子时并没有发现import高于link权重问题,经过资料的搜集总算整明白,爱好奇的你一定想点击这里。
4.在css中,能够去掉项目列表符号的属性是( )
A.list-style-image 属性
B.list-style-position属性
C.list-style属性
D.list-style-type属性
分析:写了这么多年的css一直没注意list-style是一个复合的属性,list-style-type只是其中的一项。语法:list-style : list-style-image || list-style-position || list-style-type。
5.什么是 Window 对象? 什么是 Document 对象?
BOM:
Browser Object Model:浏览器对象模型,用来访问和操纵浏览器窗口,使js有能力与浏览器“对话”,通过使用BOM,可移动窗口、更改状态文本、执行其他不与页面内容发生直接联系第操作,且没有相关标准,但被广泛支持。
1、外部对象就是浏览器提供(内部)的API
2、这些对象由W3C规定,由浏览器开发者设计并开发
3、这些对象分为2部分,其中BOM包含了DOM
4、我们可以通过js访问这些对象
栗子:
Window对象:-alert(),confirm(),prompt(“”)。-setTimeout(),clearTimeout()。-setInterval(),clearInterval()。
SCREEN对象:-width/height。-availWidth/availHeight...
History对象:-history对象包含用户访问过的URL,-length属性:浏览器历史列表中的URL数量,-back(),-forward(),-go(num)。
location对象:--location对象包含有关当前URL的信息,--href属性:当前窗口正在浏览的网页地址,-reload():重写载入当前网址,按下刷新按钮。
navigator对象:--navigator对象包含有关浏览器的信息。
DOM:
Document Object Model:文档对象模型,用来操作文档
--定义了访问和操作HTML文档的标准方法
--应用程序通过对DOM树的操作,来实现对HTML文档数据第操作。
栗子:
document.getElementById(),-parentNode,-childNodes........各节点操作。
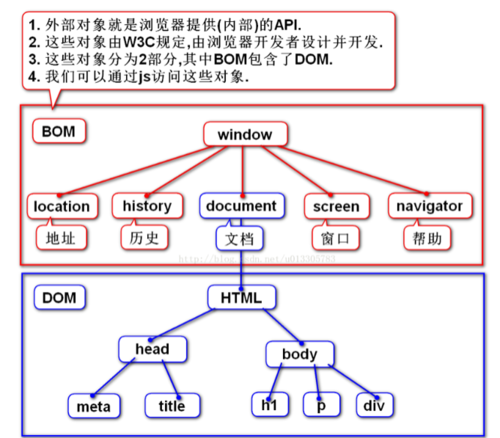
javascript外部对象,window对象,document对象
6.请简述浏览器的渲染原理
这次简单聊聊我对浏览器的渲染机制的理解。首先需要提到几个基本概念:
DOM:Document Object Model,浏览器将HTML解析成树形的数据结构,简称DOM。
CSSOM:CSS Object Model,浏览器将CSS解析成树形的数据结构,简称CSSOM。
Render Tree: DOM和CSSOM合并后生成Render Tree,如下图:
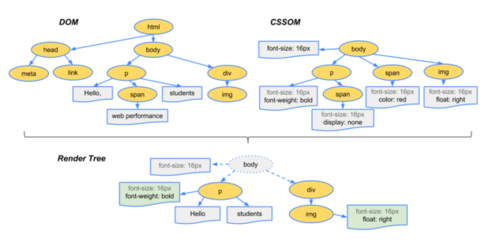
浏览器渲染机制
Layout: 计算出Render Tree每个节点的具体位置。
Painting:通过显卡,将Layout后的节点内容分别呈现到屏幕上。
下面我们来说说具体的流程。
如何通过url获取对应的html文件的过程我就不详细介绍了,不熟悉的同学可以看看输入url到页面返回的全过程
当我们的浏览器获得html文件后,会自上而下的加载,并在加载过程中进行解析和渲染。
加载说的就是获取资源文件的过程,如果在加载的过程中,遇到外部css文件和图片,浏览器会另外发出一个请求,来获取css文件和相应的图片,这个请求是异步的,并不会影响html文件。
但是如果遇到javascript文件,html文件会挂起渲染的线程,等待javascript加载完毕后,html文件再继续渲染。
为什么html需要等待javascript呢?因为javascript可能会修改DOM,导致后续的html资源白白加载,所以html必须等待javascript文件加载完毕后,再继续渲染。这也就是为什么javascript文件要写在底部body标签前的原因。
好了,接下来我们介绍渲染的细节,html的渲染过程就是将html代码按照深度优先遍历来生成DOM树。
css文件下载完后也会进行渲染,生成相应的CSSOM。
当所有的css文件下载完且所有的CSSOM构建结束后,就会和DOM一起生成Render Tree。
接下来,浏览器就会进入Layout环节,将所有的节点位置计算出来。
最后,通过Painting环节将所有的节点内容呈现到屏幕上。
我们理解的重排和重绘也就是分别触发了Layout环节和Painting环节。现在是不是清晰多了呢?
当然,每个浏览器对于渲染的实现机制都不相同,比如说chrome会在一开始就将不影响DOM结构的javascript也异步加载从而进一步提高性能等。以上的过程也只是我个人的理解,如果有什么不严谨的地方,还望大神提出。
7.一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?
同上蓝色。
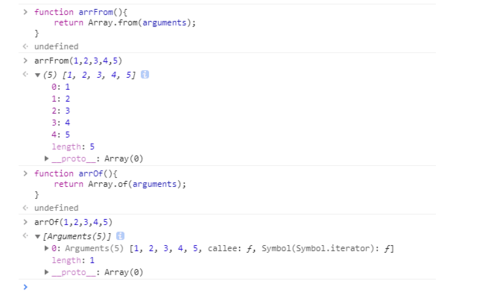
8.举例说明下Array.from和Array.of的用法
Array.from()
Array.from方法用于将两类对象转为真正的数组:类数组的对象( array-like object )和可遍历( iterable )的对象(包括 ES6 新增的数据结构 Set 和Map )。
let arrayLike = {
'0': 'a',
'1': 'b',
'2': 'c',
length: 3 };
// ES5 的写法 var arr1 = [].slice.call(arrayLike); // [‘a‘, ‘b‘, ‘c‘] // ES6 的写法 let arr2 = Array.from(arrayLike); // [‘a‘, ‘b‘, ‘c‘]
// NodeList 对象 let ps = document.querySelectorAll('p');
Array.from(ps).forEach(function (p) {
console.log(p);
});
// arguments 对象 function foo() {
var args = Array.from(arguments);
// ... }
//字符串转换为字符数组str.split('') Array.from('hello') // ['h', 'e', 'l', 'l', 'o'] let namesSet = new Set(['a', 'b'])
Array.from(namesSet) // ['a', 'b']
Array.from({ length: 3 }); // [ undefined, undefined, undefined ]对于还没有部署该方法的浏览器,可以用Array.prototype.slice方法替代:
const toArray = (() => Array.from ? Array.from : obj => [].slice.call(obj) )();
Array.from还可以接受第二个参数,作用类似于数组的map方法,用来对每个元素进行处理,将处理后的值放入返回的数组。
Array.from(arrayLike, x => x * x); // 等同于 Array.from(arrayLike).map(x => x * x); Array.from([1, 2, 3], (x) => x * x) // [1, 4, 9]
//Array.from回调函数var arr1 = Array.from([1,2,3], function(item){ return item*item;
});var arr2 = Array.from([1,2,3]).map(function(item){ return item*item;
});var arr3 = Array.from([1,2,3], (item) => item*item);console.log(arr1); //[ 1, 4, 9 ]console.log(arr2); //[ 1, 4, 9 ]console.log(arr3); //[ 1, 4, 9 ]Array.of()
Array.of方法用于将一组值,转换为数组。Array.of总是返回参数值组成的数组。如果没有参数,就返回一个空数组。
Array.of基本上可以用来替代Array()或new Array(),并且不存在由于参数不同而导致的重载。它的行为非常统一。
这个方法的主要目的,是弥补数组构造函数Array()的不足。因为参数个数的不同,会导致Array()的行为有差异。
Array() // [] Array(3) // [, , ,] Array(3, 11, 8) // [3, 11, 8] Array.of() // [] Array.of(3) // [3] Array.of(3, 11, 8) // [3,11,8] Array.of(3).length // 1 Array.of(undefined) // [undefined] Array.of(1) // [1] Array.of(1, 2) // [1, 2]
Array.of方法可以用下面的代码模拟实现:
function ArrayOf(){ return [].slice.call(arguments);
}似乎都可用于数组的转换 =.=

噼里啪啦噼里啪啦
补充:
fill()填充数组
fill()使用给定值,填充一个数组。
let arr = ['a', 'b', 'c'].fill(7)document.write(arr); // [7, 7, 7] let newArr = new Array(3).fill(7)document.write(newArr); // [7, 7, 7]
9.ES6新增遍历数组的实例方法有哪几个?
ES6提供三个新的方法:
entries()
keys()
values()
用于遍历数组。它们都返回一个遍历器,可以用for...of循环进行遍历,唯一的区别是keys()是对键名的遍历、values()是对键值的遍历,entries()是对键值对的遍历。
for (let index of ['a', 'b'].keys()) { document.write(index);
}// 0// 1
for (let elem of ['a', 'b'].values()) { document.write(elem);
}// 'a'// 'b'
for (let [index, elem] of ['a', 'b'].entries()) { document.write(index, elem);
}// 0 "a"// 1 "b"10. 说明下数据对象深拷贝的实现方式?
浅拷贝
首先可以通过 Object.assign 来解决这个问题。
let a = { age: 1}let b = Object.assign({}, a)
a.age = 2console.log(b.age) // 1当然我们也可以通过展开运算符(…)来解决
let a = { age: 1}let b = {...a}
a.age = 2console.log(b.age) // 1通常浅拷贝就能解决大部分问题了,但是当我们遇到如下情况就需要使用到深拷贝了
let a = { age: 1, jobs: { first: 'FE'
}
}let b = {...a}
a.jobs.first = 'native'console.log(b.jobs.first) // native浅拷贝只解决了第一层的问题,如果接下去的值中还有对象的话,那么就又回到刚开始的话题了,两者享有相同的引用。要解决这个问题,我们需要引入深拷贝。
深拷贝
这个问题通常可以通过JSON.parse(JSON.stringify(object))来解决。
let a = { age: 1, jobs: { first: 'FE'
}
}let b = JSON.parse(JSON.stringify(a))
a.jobs.first = 'native'console.log(b.jobs.first) // FE但是该方法也是有局限性的:
1.会忽略 undefined
2.不能序列化函数
3.不能解决循环引用的对象
let obj = { a: 1, b: { c: 2, d: 3,
},
}
obj.c = obj.b
obj.e = obj.a
obj.b.c = obj.c
obj.b.d = obj.b
obj.b.e = obj.b.clet newObj = JSON.parse(JSON.stringify(obj))console.log(newObj)如果你有这么一个循环引用对象,你会发现你不能通过该方法深拷贝

在遇到函数或者undefined的时候,该对象也不能正常的序列化
let a = { age: undefined, jobs: function() {}, name: 'cool'}let b = JSON.parse(JSON.stringify(a))console.log(b) // {name: "cool"}你会发现在上述情况中,该方法会忽略掉函数和 undefined 。
但是在通常情况下,复杂数据都是可以序列化的,所以这个函数可以解决大部分问题,并且该函数是内置函数中处理深拷贝性能最快的。当然如果你的数据中含有以上三种情况下,可以使用 lodash 的深拷贝函数。
如果你所需拷贝的对象含有内置类型并且不包含函数,可以使用 MessageChannel
function structuralClone(obj) { return new Promise(resolve => { const {port1, port2} = new MessageChannel();
port2.onmessage = ev => resolve(ev.data);
port1.postMessage(obj);
});
}var obj = {a: 1, b: { c: b
}}// 注意该方法是异步的// 可以处理 undefined 和循环引用对象const clone = await structuralClone(obj);11.说明下事件代理 事件委托 事件冒泡
事件冒泡:子级元素的某个事件被触发,它的上级元素的该事件也被递归触发。
事件代理(事件委托):使用了事件冒泡的原理,从触发某事件的元素开始,递归地向上级元素传播事件。
事件委托的优点:
1.对于要大量处理的元素,不必为每个元素都绑定事件,只需要在它们的父元素上绑定一次即可,提高性能。
2.可以处理动态插入DOM中的元素,对动态插入DOM中的元素进行直接绑定是不行的。
作者:littleyu
链接:https://www.jianshu.com/p/4e1a650c5fd2
共同学习,写下你的评论
评论加载中...
作者其他优质文章


