
特别声明:本文仅学习交流,感兴趣的朋友可以留言互相讨论。
文章简介
本文是在学习过程中通过自己对模型的理解及复盘整理,并不对代码逻辑进行讲解,文中外链资料都是在学习过程中觉得比较容易理解的资料,可以作为参考,本来不想写那么长的,越写发现越写不完......
数据来源:Kaggle下载creditcard.csv信用卡欺诈数据,数据做过脱敏处理,可自行下载。模型介绍
一元线性回归是一种很容易理解的模型,就相当于y = f(x) = ax + b,表明自变量x与因变量y的关系。那么x0,x1,x2,会生成y0,y1,y2其实(x0,y0)、(x1,y1)就是分布在二维向量间的多个点,我们可以拟合一个线性方程:y =β0 +β1*x1 +β2*x2 +β3*x3 +...+βn*xn并通过最小二乘法估计各个β系数的值。(点我跳转到 最小二乘法通俗解释 相关资料)
那么到底什么是逻辑回归?
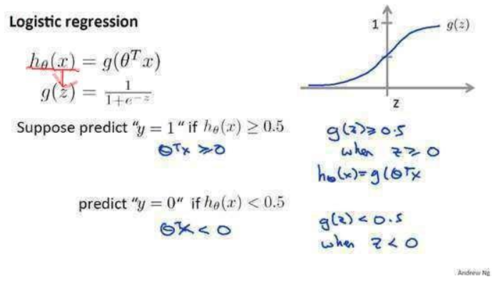
这里又要讲到一个Sigmoid函数,Logistic回归算法基于Sigmoid函数,或者说Sigmoid就是逻辑回归函数。下图个人觉得非常好理解,g(z)函数就是Sigmoid函数,它将线性拟合h(x)函数作为参数z带入公式,线性方程我们知道他的x,y可以是±∞,那么通过Sigmoid函数之后可以将y的值域范围压缩到(0,1),注意这是开区间,它仅无限接近0和1,这结果其实就是最后二分类的概率值,一般默认概率大于等于0.5则默认为1,小于0.5则为0,阀值可以设置。
用一句话来说就是:逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数得出分类概率,通过阈值过滤来达到将数据二分类的目的。(伯努利分布又称二项分布,是无数个独立试验的正样例成功次数的概率分布,详细点我跳转到相关资料)(点我跳转到 最大似然法通俗解释 相关资料)
数据观察
先看样本数据source_data.head(3)
字段名都被做过特殊处理,Class为最后的标识(Label)看到所有的特征(Feature)都在(1,-1)间,但Amount的数值波动范围较大,机器学习中其实就等于转化为数学问题,数据按大小来界定权重,Amount大重要程度大,所以在这需要对Amount进行数据标准数据标准化(Normalization)
常用的2个标准化方法 :Z-Score和Min_Max这两种标准化方法不光在机器学习中有用,平时多维数据简单归一拉到一个水平线上加权制定系数也是常用到这两个方法。
1、Min_Max 标准化将原始数据线性化的方法转换到[0,1]的范围,归一化公式如下:
2、Z-Score 归一化方法将原始数据集归一化为均值为0、方差1的数据集,那么它的阈值范围自然为[-1,1]归一化公式如下:

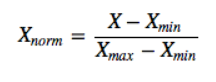
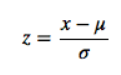
# 1、StandardScaler就是z-score方法 # 2、MaxMinScaler就是min_max方法from sklearn.preprocessing import StandardScaler source_data['New_Amount'] = StandardScaler().fit_transform(source_data['Amount'].values.reshape(-1,1))# StandardScaler参数只接受矩阵data = source_data.drop(columns=['Amount','Time'])
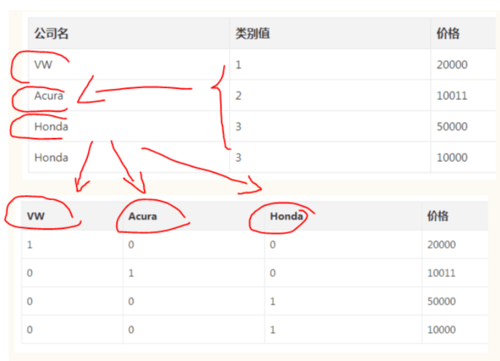
独热编码(One-Hot Encoding)
是不是已经各种术语弄得快放弃了? 画了一张图,可能不是很严谨但我觉得很好理解
就是把离散变量作为fature,对应fature以1作为标识,这个编码转化过程就是One-Hot Encoding,还有一种编码叫LabelEncoder就是将公司名变成类别值样本重采样(Resample)
# 检查正负样本label差异pd.value_counts(source_data['Class'])

样本重采样是对样本Label数量不均衡处理,这里可以有2种处理方式:欠采样(代表算法:EasyEnsemble) 、 过采样(代表算法:SMOTE) ,两种方法概念其实很简单。
1、欠采样:即去除一些反例使得正反例数目接近,再进行学习。由于丢弃很多反例,会使得训练集远小于初始训练集,所以有可能导致欠拟合。
2、过采样:增加一些正例使得正反例数目接近,然后再学习。需要注意的是不能只是对初始正例样本重复采样,否则导致严重的过拟合,SMOTE算法中用用到了另一种机器学习的算法KNN(K邻近取样算法)。
from imblearn.over_sampling import SMOTEfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import confusion_matrix# 数据集中正反lable相差悬殊,需进行重采样# 重采样常用方法有2种,1、欠采样 代表算法:EasyEnsemble 2、过采样 代表算法:SMOTE# 先对数据进行切分labels = data['Class'] features = data.drop(columns=['Class']) x_train, x_test, y_train , y_test = train_test_split(features, labels, test_size = 0.3, random_state = 0)# 这里进行SMOTE过采样的方法over_sample = SMOTE(random_state=0) os_x_train , os_y_train = over_sample.fit_sample(x_train ,y_train) os_x_train = pd.DataFrame(os_x_train) os_y_train = pd.DataFrame(os_y_train)
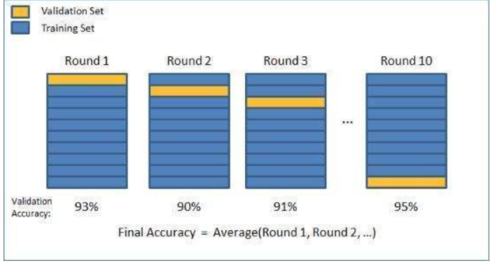
交叉验证(Cross - Validation)
用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model)
损失函数(Loss Function)
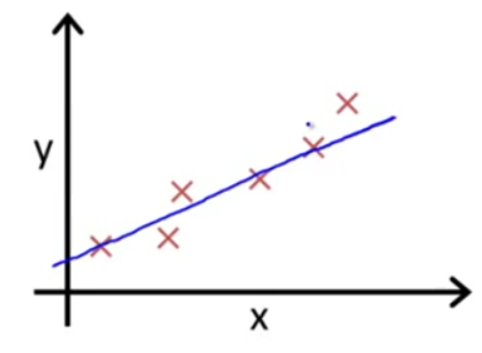
看到一个比较容易理解的说法如下:
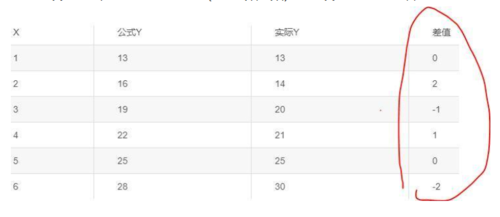
我们假设直线的方程为Y=a0+a1X(a为常数系数)。假设a0=10 a1=3 那么Y=10+3X
上面的案例它的绝对损失函数求和计算求得为:6,这个函数就称为损失函数(loss function),或者叫代价函数(cost function),我们希望我们预测的公式与实际值差值越小越好,所以就定义了一种衡量模型好坏的方式。
公式Y-实际Y的绝对值,数学表达式:
为后续数学计算方便,我们通常使用平方损失函数代替绝对损失函数,公式Y-实际Y的平方,数学表达式:
还有在下面讲到正则化的部分,损失函数 = 误差部分(loss term) + 正则化部分(regularization term)正则化惩罚
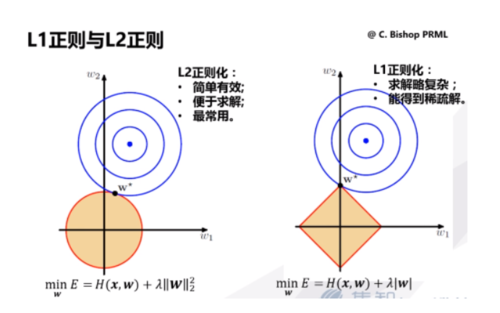
常用正则范数:L1正则、L2正则
1、L2正则化惩罚项(λ为惩罚力度权重):
loss = loss + 1/2w² ,w为明显波动情况,通过过W去判断模型最终loss值,越低模型效果越好
2、L1正则化惩罚项 (λ为惩罚力度权重):
loss = loss + |w| ,w为明显波动情况,通过过W去判断模型最终loss值,越低模型效果越好
加入正则化的目的:防止过拟合、约束(限制)要优化的参数
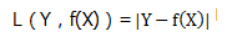
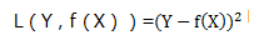
混淆矩阵(Confusion Matrix)
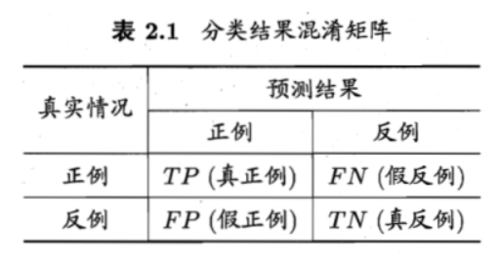
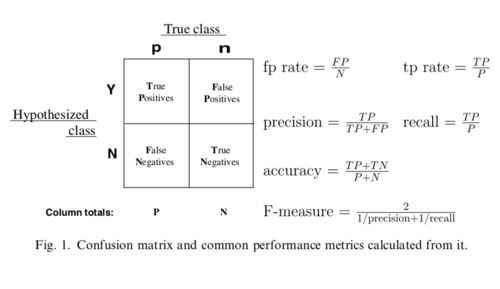
首先它长这样,就一个多维矩阵,呵呵!!统计学就术语可以让我们从放弃到崩溃。我们从混淆矩阵的4个基础指标中可以衍生出各类评估指标,模型好坏都靠这些指标进行评估。
感觉很多资料讲的不够通俗,个人理解给大家翻译一下,我们先把正例和反例替换成比较通俗的"买"和"不买":真正例(True Positive,TP):真实情况是"买",预测结果也是"买",TP表示正例预测成功次数。假正例(False Positive,FP):真实情况是"不买",预测结果也是"买",FP表示负例预测错误次数。假负例(False Negative,FN):真实情况是"买",预测结果也是"不买",FN表示正例预测错误次数。真负例(True Negative,TN):真实情况是"不买",预测结果也是"不买",TN表示负例预测成功次数。
现在明白了吧,其实很简单,再来看下常用的衍生指标的意思。模型精度(Accuracy):Accuracy = (TP + TN) / (TP + FP + TN + FN)
一般情况下,模型的精度越高,说明模型的效果越好。准确率,又称查准率(Precision,P):Precision = TP / (TP + FP)
一般情况下,查准率越高,说明模型的效果越好。召回率,又称查全率(Recall,R):Recall = TP / (TP + FN)
一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。F1值(F1-Score):F1 Score = P*R/2(P+R),其中P和R分别为 precision 和 recall
一般情况下,F1-Score越高,说明模型的效果越好。
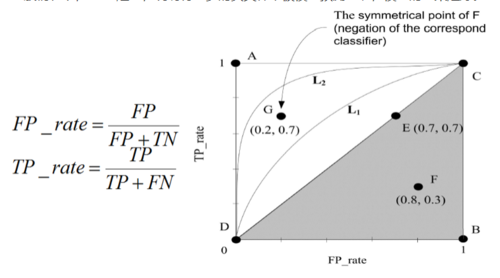
那么我们再来看几个图形指标真阳性率(True Positive Rate,TPR ):TPR = TP / (TP+FN)
等于Recall,一般情况下,TPR 越高,说明有更多的正类样本被模型预测正确,模型的效果越好。假阳性率(False Positive Rate,FPR ):FPR= FP / (FP+TN)
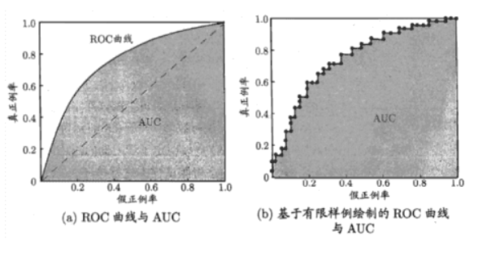
一般情况下,FPR 越低,说明有更多的负类样本被模型预测正确,模型的效果越好。ROC(Receiver Operating Characteristic):ROC曲线的纵坐标为 TPR,横坐标为 FPRAUC(Area Under Curve):ROC曲线下的面积,很明显,AUC 的结果不会超过 1,通常 ROC 曲线都在 y = x 这条直线上面,所以,AUC 的值一般在 0.5 ~ 1 之间,面积越大模型效果越好。
以上都是很重要的模型评估的常用指标,代码如下
from sklearn.metrics import roc_curve, auc# y = np.array([1,1,2,2])# pred = np.array([0.1, 0.4, 0.35, 0.8])fpr, tpr, thresholds = roc_curve(y, pred, pos_label=1) fpr # array([ 0. , 0.5, 0.5, 1. ])tpr # array([ 0.5, 0.5, 1. , 1. ])thresholds #array([ 0.8 , 0.4 , 0.35, 0.1 ])auc(fpr, tpr)
那么这张图我们现在就相当好理解了吧。
以下两个链接对混淆矩阵及涉及到的指标讲述的非常明白易懂,还不清楚的可以点开看阅读。混淆矩阵及评估指标相关扩展资料1,外链混淆矩阵及评估指标相关扩展资料2,外链
混淆矩阵图例
为了美观,做了混淆举证图例展示,其实如果平时完全可以,用上面普通矩阵形式进行观察
import itertoolsdef plot_confusion_matrix(cm,
classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]# print("Normalized confusion matrix")
else: pass# print('Confusion matrix, without normalization')
im = plt.imshow(cm, interpolation='nearest', cmap=cmap, vmax = cm.max() / 3.)
plt.title(title,fontsize = 16)
plt.colorbar(im,shrink=0.63,pad=0.05)
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0,fontsize = 14)
plt.yticks(tick_marks, classes,fontsize = 14,rotation=90)# fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j]),
horizontalalignment="center",
fontsize = 16,
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()# plt.ylabel('True label',fontsize = 14)# plt.xlabel('Predicted label',fontsize = 14)# 模型评估标准 re_call = TP/(TP+NF)plt.figure(figsize=(12,6))
for i,t in enumerate(range(3,9),start=1):
thresholds = t / 10
y_proba = lr.predict_proba(x_test.values)[:,1] > thresholds
plt.subplot(2,3,i)
matrix = confusion_matrix(y_test, y_proba)
plot_confusion_matrix(matrix, classes=['Label_0','Label_1'],title = 'Thresholds > %s' % thresholds)# print(classification_report(y_test, y_proba))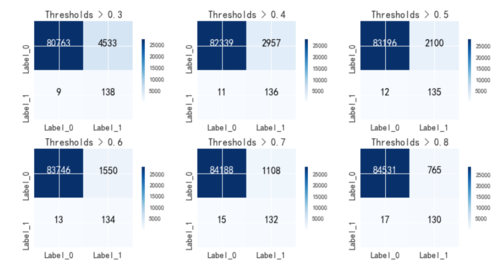
模型评估(Model Evaluation)
模型评估常用的包括了上面提到的交叉验证,损失函数,正则化惩罚,混淆矩阵,FPR,TPR(也可以称为recall),ROC,AUC,F1-Score
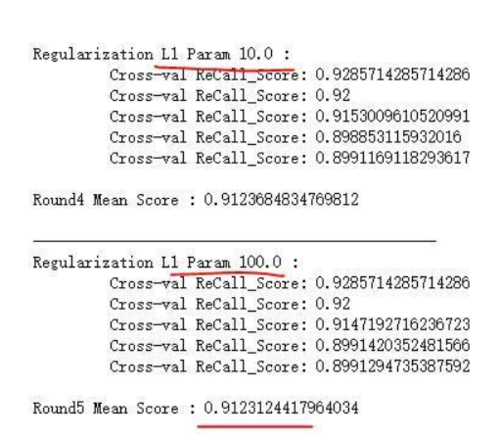
下面不仅做了一次5层的交叉验证,还用了用了L1惩罚项,不断用惩罚系数去调整模型的精确度,确认惩罚系数,从结果图中可以看到,模型精确度不断在提升。
# 交叉验证准备,切分数据集def kfold_result_info(x,y,n=5):
os_x_train = x
os_x_train = y # K-fold交叉验证
kfold = KFold(len(os_y_train),n_folds= n ,shuffle=False,random_state=0) for num in range(5): # c_param 为参数λ惩罚力度权重,代入不断尝试,构造参数
c_param = 0.01 * 10 ** num
print('Regularization L1 Param %s :' %(c_param))
recall_list = []
for i ,val_idx in enumerate(kfold, start=1): # 建立逻辑回归测试模型
lr = LogisticRegression(C = c_param, penalty='l1')
lr.fit(os_x_train.iloc[val_idx[0],:], os_y_train.iloc[val_idx[0],:].values.ravel())
os_pre_result = lr.predict(os_x_train.iloc[val_idx[1],:].values) # 模型评估标准 re_call = TP/(TP+NF)
re_call = recall_score(os_y_train.iloc[val_idx[1],:].values,os_pre_result)
recall_list.append(re_call)
print('\t Cross-val ReCall_Score: %s' % re_call)
mean_score = np.mean(recall_list)
print('\nRound%s Mean Score : %s' % (num + 1, mean_score))
print('\n-----------------------------------------------')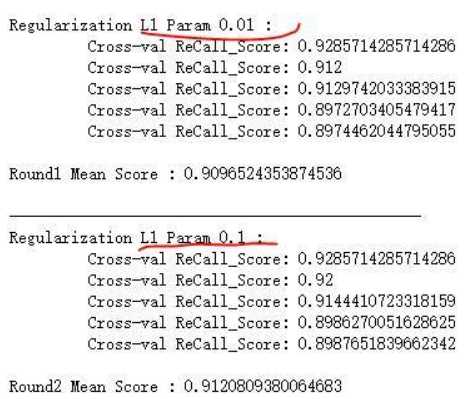
作者:我叫丶钱小钱
链接:https://www.jianshu.com/p/af100139b920
共同学习,写下你的评论
评论加载中...
作者其他优质文章



