
包括:
理解卷积神经网络
使用数据增强缓解过拟合
使用预训练卷积网络做特征提取
微调预训练网络模型
可视化卷积网络学习结果以及分类决策过程
介绍卷积神经网络,convnets,深度学习在计算机视觉方面广泛应用的一个网络模型。
卷积网络介绍
在介绍卷积神经网络理论以及神经网络在计算机视觉方面应用广泛的原因之前,先介绍一个卷积网络的实例,整体了解卷积网络模型。用卷积网络识别MNIST数据集。
from keras import layersfrom keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu'))
卷积网络接收(image_height,image_width,image_channels)形状的张量作为输入(不包括batch size)。MNIST中,将图片转换成(28,28,1)形状,然后在第一层传递input_shape参数。
显示网络架构
model.summary() ________________________________________________________________ Layer (type) Output Shape Param #================================================================ conv2d_1 (Conv2D) (None, 26, 26, 32) 320________________________________________________________________ maxpooling2d_1 (MaxPooling2D) (None, 13, 13, 32) 0________________________________________________________________ conv2d_2 (Conv2D) (None, 11, 11, 64) 18496________________________________________________________________ maxpooling2d_2 (MaxPooling2D) (None, 5, 5, 64) 0________________________________________________________________ conv2d_3 (Conv2D) (None, 3, 3, 64) 36928================================================================ Total params: 55,744Trainable params: 55,744Non-trainable params: 0
可以看到每个Conv2D和MaxPooling2D网络层输出都是3D张量,形状为(height,width,channels).随着网络层的加深,长度和宽度逐渐减小;通道数通过Conv2D层的参数控制。
下一步连接Dense层,但当前输出为3D张量,需要将3D张量平铺成1D,然后添加Dense层。
model.add(layers.Flatten()) model.add(layers.Dense(64,activation='relu')) model.add(layers.Dense(10,activation='softmax'))
因为是10分类,最后一层为10个神经元,激活函数为softmax。
最后的网络架构
>>> model.summary() Layer (type) Output Shape Param #================================================================ conv2d_1 (Conv2D) (None, 26, 26, 32) 320________________________________________________________________ maxpooling2d_1 (MaxPooling2D) (None, 13, 13, 32) 0________________________________________________________________ conv2d_2 (Conv2D) (None, 11, 11, 64) 18496________________________________________________________________ maxpooling2d_2 (MaxPooling2D) (None, 5, 5, 64) 0________________________________________________________________ conv2d_3 (Conv2D) (None, 3, 3, 64) 36928________________________________________________________________ flatten_1 (Flatten) (None, 576) 0________________________________________________________________ dense_1 (Dense) (None, 64) 36928________________________________________________________________ dense_2 (Dense) (None, 10) 650================================================================ Total params: 93,322Trainable params: 93,322Non-trainable params: 0
(3,3,64)输出平摊成(576,)向量。
网络训练
from keras.datasets import mnistfrom keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)测试集上模型评估:
>>> test_loss, test_acc = model.evaluate(test_images, test_labels)>>> test_acc0.99080000000000001
在Dense网络上准确率为97.8%,基本卷积网络上准确率到99%.为什么简单的卷积网络工作效果这么好?回答之前,先了解Conv2D和MaxPooling2D层。
卷积操作
全连接网络和卷积网络的区别在于Dense全连接层学习输入特征空间的全局模式特征,而卷积神经网络学习输入特征空间的局部模式特征。
卷积网络的两个关键特性:
学习具有平移不变性的模式特征:一旦学习到图片左上角的模式特征,可以在任何地方识别,如右下角,这种特性使得图片处理更加有效,需要的样本相对减少(实际生活中具有平移不变性)
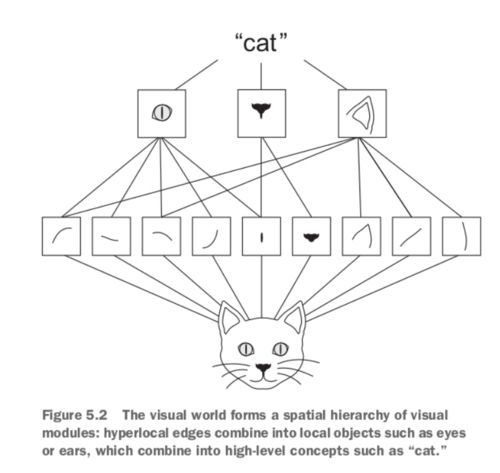
学习模式的空间层次结构:第一个卷积层将学习小的局部模式,如边缘,第二个卷积层将学习由第一层特征构成的更大图案,等等。这使得卷积网络能够有效地学习越来越复杂和抽象的视觉概念。(现实生活中许多都是分级的)。

image
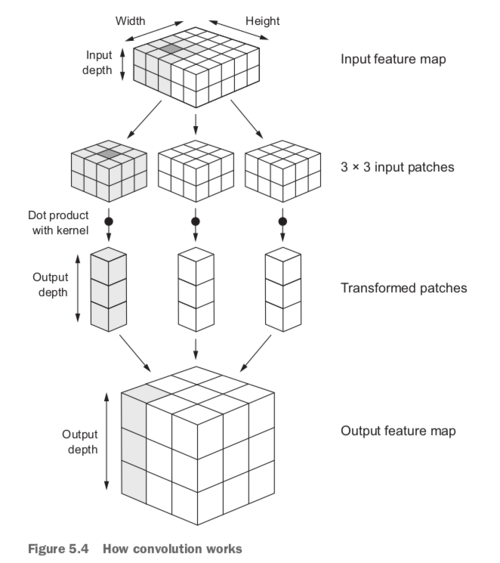
卷积在3D张量上运算,称为特征映射,具有两个空间轴(高度和宽度)以及深度轴(也称为通道轴).对RGB三原色图片来说,通道数为3--红、绿、蓝;MNIST数据集中图片通道数为1--灰度图。卷积操作在输入特征图上小分片上,然后将多个操作结果生成最后的特征图。输出的特征图仍然是3D张量:width、height,深度可以是任意值,因为深度是网络层的一个参数,而且深度值不再代表红绿蓝颜色通道,表示过滤器的个数。过滤器对输入数据的特定方面进行编码:比如在高级别,单个过滤器可以编码“输入中存在面部”的概念。
卷积定义的两个参数:
卷积核大小:通常为3x3,5x5.
卷积核个数:卷积核个数等于本层网络输出层的深度。
Keras中,Conv2D网络层定义:Conv2D(output_depth, (window_height, window_width)) .
卷积:卷积核在上一层的特征图的全通道进行滑动,然后抽取形状为(window_height,window_width,input_depth)形状的3D片特征。每个3D片特征最后转换成1D向量(卷积运算--张量点积),形状(output_depth,),所有的结果向量整合形成最后的3D特征(height,width,output_depth).
image
输出结果的宽度和高度可能和输入宽度高度不同,由于:
Padding项;
Strides 步长
最大池化 MaxPooling
最大池化层的作用在于对特征图进行下采样。最大池化在特征图中选择window,然后每个通道的在窗口内求最大值。概念上与卷积操作类似,卷积操作在小patch 中做线性转换,最大池化是求最大值,通过tensor的max张量操作。最大池化通常采用2x2窗口,步长为2,特征图减半。卷积通常卷积核大小为3x3,步长为1。
下采样的目的在于减少要处理特征图的参数量,通过使连续的卷积层看到越来越大的窗口(就它们所涵盖的原始输入的比例而言)来促使空间滤波器层次结构。
最大池化并不是唯一的下采样方法。可以使用带步长卷积、或平均池化,但是最大池化的工作效果更好。
小数据集上训练卷积网络
计算机视觉中进场会遇到使用很少的数据集去训练一个图像分类模型。“小样本”意味着样本量在几百到几万张. 比如猫狗分类,共4000张图片,猫2000张,狗2000张。用2000张图片来训练--1000张验证集,1000张测试集。
首先不做任何正则化处理,直接训练,得到一个baseline模型,准确率为71%。主要问题在于模型过拟合。之后介绍data augmentation数据增强,减缓过拟合。训练后为82%。更有效的方法是用已训练好的模型最特征提取---准确率90%~96%,或者微调已训练好的网络做特征提取(97%)。这三种方法有助于在小数据集上的模型训练。
深度学习与小数据问题的相关性
可能经常听说:深度学习只能工作在大数据集上。这种说法部分正确:深度学习的一个重要特性在于深度学习能自己在训练数据中寻找特征,而不需要人工干预,而这个特性只有在大数据样本量上才有效,特别是输入数据维度特别高时,eg图片。
但是,对于初学者来说,构成大量样本的内容与尝试训练的网络的大小和深度是相对的。用几十张图片训练卷积网络来解决一个十分复杂的问题是不可能的,但如果模型比较简单经过正则化处理,同时任务比较简单,几百张图片也能解决问题。因为卷积网络学习局部的、具有平移不变性的特征,它们在感知问题上具有很高的数据效率。 尽管相对缺乏数据,但无需额外的特征工程,即使在非常小的图像数据集上从头开始训练,卷积网络仍然会产生合理的结果。
更重要的是,深度学习模型本质上是高度可再利用的:例如,可以采用在大规模数据集上训练的图像分类或语音到文本模型,只需进行微小的更改,就可以重新用于显著不同的问题上。具体而言,以计算机视觉为例,许多预先训练好的模型(通常在ImageNet数据集上训练)提供公开下载,当样本量少时,可以用在模型中(做特征提取使用)提升工作效果。
数据下载
Keras中没有包括Dogs vs. Cats数据集。可以在Kaggle上下载。
图片格式为JPEGs.数据集包含25000张猫狗图片(一半一半)。下载解压缩后,创建一个新数据集包括3个文件夹:每类1000张的训练集、每类500张的验证集和每类500张的测试集。
import os,shutil#原始数据original_dataset_dir = '/Users/fchollet/Downloads/kaggle_original_data'#新数据集目录base_dir = '/Users/fchollet/Downloads/cats_and_dogs_small'os.mkdir(base_dir)#创建训练集、验证集、测试集目录train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)#创建对应数据集下不同类别的目录train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]#取前1000张猫图片for fname in fnames:#将前一千张猫图片复制到新数据集目录下
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]#取500张猫图片for fname in fnames:#500张猫图片复制到验证集
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]#取500张猫图片for fname in fnames:#500张猫图片做测试集
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)#狗图片fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]#1000张狗图片做训练集for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]for fname in fnames:#500张狗图片做验证集
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst) Copies the next 500fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]for fname in fnames:#500张狗图片做测试集
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)构建模型
from keras import layersfrom keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))
模型架构:
>>> model.summary() Layer (type) Output Shape Param #================================================================ conv2d_1 (Conv2D) (None, 148, 148, 32) 896________________________________________________________________ maxpooling2d_1 (MaxPooling2D) (None, 74, 74, 32) 0________________________________________________________________ conv2d_2 (Conv2D) (None, 72, 72, 64) 18496________________________________________________________________ maxpooling2d_2 (MaxPooling2D) (None, 36, 36, 64) 0________________________________________________________________ conv2d_3 (Conv2D) (None, 34, 34, 128) 73856________________________________________________________________ maxpooling2d_3 (MaxPooling2D) (None, 17, 17, 128) 0________________________________________________________________ conv2d_4 (Conv2D) (None, 15, 15, 128) 147584________________________________________________________________ maxpooling2d_4 (MaxPooling2D) (None, 7, 7, 128) 0________________________________________________________________ flatten_1 (Flatten) (None, 6272) 0________________________________________________________________ dense_1 (Dense) (None, 512) 3211776________________________________________________________________ dense_2 (Dense) (None, 1) 513================================================================ Total params: 3,453,121Trainable params: 3,453,121Non-trainable params: 0
编译阶段,使用RMSProp优化算法,binary crossentropy为损失函数。
from keras import optimizers model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(lr=1e-4),metrics=['acc'])
数据预处理
数据在送到网络模型之前应该转换成浮点类型的张量。目前数据集中数据格式为JPEG,所以处理步骤大致为:
读取图片文件;
将JPEG格式转换为RGB像素值;
转换成浮点类型张量;
将像素值(0~255)缩放到[0,1]之间。
针对上述步骤,Keras中有自动化处理方法。Keras中有一个图像处理模块,keras.preprocessing.image. 其中包括一个ImageDataGenerator类,可以将磁盘上的图片文件自动转换成预处理的张量batch批量。使用方法:
from keras.preprocessing.image import ImageDataGenerator train_datagen = ImageDataGenerator(rescale=1./255) test_datagen = ImageDataGenerator(rescale=1./255)#将图片转换成150x150,类别为2;class_mode 确定返回标签的类型binary二分类 1D类型train_generator=train_datagen.flow_from_directory(train_dir,\ target_size=(150,150),batch_size=20,class_mode='binary') validation_generator = test_datagen.flow_from_directory( validation_dir,target_size=(150, 150),batch_size=20,class_mode='binary')
生成器generator的数据结果为150x150 RGB批量图片,尺寸为(20,150,150,3),二进制标签形状(20,)。每个批量大小为20个样本(batch_size为20). 注意-生成器无限期地生成这些批次:它在目标文件夹的图像上无休止地循环。
使用generator数据生成器对模型进行训练。使用fit_generator方法,对于数据生成器来说,相当于fit方法。fit_generator第一个参数是Python生成器类型,能不断地生成输入和标签批量。因为数据不断生成,Keras模型需要知道在声明一个epoch之前从发生器中抽取多少批量;steps_per_epoch参数:从生成器中生成 steps_per_epoch个批量数据;在经过steps_per_epoch次梯度下降后,在下一个epoch上进行训练。在这里,批量大小为20,一个epoch有100个批量,生成2000张图片样本。
使用fit_generator方法,可以传递validataion_data参数,和fit方法相似。值得注意的是,这个参数可以赋值为数据生成器,也可以是numpy数组的元组。如果validation_data参数是数据生成器,生成器能不断地生成数据,所以需要设置validation_steps参数,确定从生成器中生成多少验证集批量。
history = model.fit_generator(train_generator,steps_per_epoch=100,epoch=30,validation_data=validation_generator,validation_steps=50)
模型保存:
model.save('cats_and_dogs_small_1.h5')训练集验证集准确率、损失值变化:
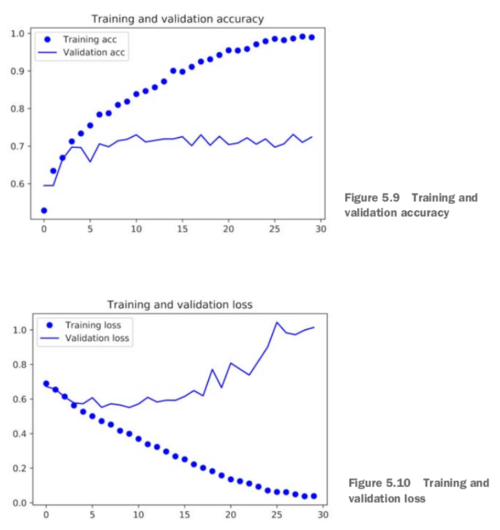
image
可以发现模型发生过拟合现象。训练准确率随着时间线性增加,直到100%,而验证集准确率在70-72%波动。验证集损失在5个epoch之后达到最小值,之后开始波动;训练集损失线性减少直到为0
因为训练集只有2000张图片,遇到的第一个问题就是模型过拟合。Dropout、权重衰减可以减缓过拟合,还有一个计算机视觉任务中,经常使用的处理方法:数据增强data augmentation。
数据增强
过度拟合是由于样本太少而无法学习,导致无法训练可以推广到新数据的模型。给定无限的数据,模型可以学习到手头数据分布的每个可能方面:永远不会过拟合。数据增强采用从现有训练样本生成更多训练数据的方法,通过大量随机变换来增加样本,从而产生新的可靠的图像样本。
目标是在训练时,模型将永远不会看到两张完全相同的图片。这有助于模型观察数据的更多方面并更好地概括数据。
Keras中,可以通过实例化ImageDataGenerator实例,确定图片转换方法,从而实现数据增强。
datagen = ImageDataGenerator( rotation_range=40,#最大旋转角度 width_shift_range=0.2,#水平随机平移图片的范围,比例 height_shift_range=0.2,#垂直随机平移图片的范围 shear_range=0.2,#随机应用剪切变换 zoom_range=0.2,#随机缩放图片 horizontal_flip=True,#随机翻转图片 fill_mode='nearest')#用于填充新创建的像素的策略,在旋转或宽度/高度偏移后出现
如果使用这样的数据增强配置训练新网络,网络将永远不会看到两张相同的输入图片。但它看到的输入仍然是严重相互关联的,因为它们来自少量原始图像 - 无法生成新信息,只能重新混合现有信息。因此,这不可能完全摆脱过拟合。为了进一步减缓过拟合,需要增加Dropout层,在全连接层之前。
新网络模型:
model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Flatten()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(512, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(lr=1e-4),metrics=['acc'])
使用数据增强和Dropout训练网络。
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150, 150),batch_size=32,class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150, 150),batch_size=32,class_mode='binary')
history = model.fit_generator(train_generator,steps_per_epoch=100,
epochs=100,validation_data=validation_generator,validation_steps=50)
model.save('cats_and_dogs_small_2.h5')#模型保存使用数据增强和Dropout后,训练集、验证集准确率和损失函数变化。
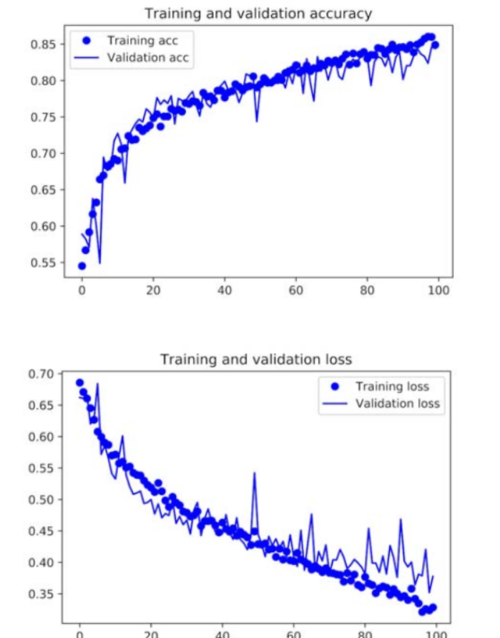
image
模型不再过拟合:训练集曲线和验证集曲线几乎相互吻合。准确率82%,提高了15%左右。使用正则化技术,微调网络超参数,模型准确率会进一步提高,到86%~87%.但是很难继续提高,因为训练数据有限,样本量太少。另一种方法,可以采用预先训练好的网络模型,做特征提取,提高准确率。
使用预训练卷积网络
在小图像数据集上使用深度学习的一种常见且高效的方法是使用预训练网络。预训练网络是先前在大型数据集上训练的已保存网络,通常是处理大规模图像分类任务。如果这个原始数据集足够大且代表性强,则预训练网络学习的特征的空间层次结构可以有效地充当视觉世界的通用模型,因此其特征可以证明对许多不同的计算机视觉问题都有用,甚至这些新问题可能涉及与原始任务完全不同。例如,可以在ImageNet上训练网络(其中类主要是动物和日常物品),然后将这个训练好的网络重新用于识别图像中的家具物品任务中。与许多较旧的浅学习方法(传统机器学习方法)相比,学习特征在不同问题中的这种可移植性是深度学习的关键优势,并且它使得深度学习对于小数据问题非常有效。
比如在ImageNet数据集上训练的网络模型(140万个标记图像和1,000个不同类)。ImageNet包含许多动物类别,包括不同种类的猫和狗,因此可以期望在狗与猫的分类问题上表现良好。
使用VGG16网络架构,它是ImageNet的简单且广泛使用的convnet架构。
使用预训练网络有两种方法:特征提取和微调。
特征提取
特征提取包括使用先前网络学习的表示从新样本中提取有趣特征。然后,这些功能将通过一个新的分类器运行,该分类器从头开始训练。
如前所述,用于图像分类的网络包含两部分:它们以一系列池化和卷积层开始,并以密集连接的分类器结束。第一部分称为模型的卷积基础。在卷积网络中,特征提取包括获取先前训练的网络的卷积基础,通过它运行新数据,以及在输出之上训练新的分类器。
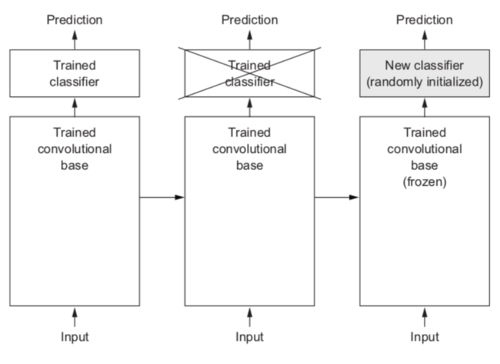
image
为什么只重用卷积网络?是否可以重复使用全连接分类器?一般来说,应该避免这样做。原因是卷积网络学习的表示可能更通用,因此更可重复使用:特征网络的特征图是图片上一般概念的存在图,无论处理的计算机视觉问题是什么,都可能是有用的。但是,分类器学习的表示必然特定于训练模型的类集 - 它们将仅包含关于整个图像中该类或该类的存在概率的信息。此外,在全连接网络层的输出表示不再包含有关对象在输入图像中的位置信息:这些表示消除了空间的概念,而卷积特征图还可以描述对象的位置信息。对于对象位置很重要的问题,全连接的特征表示在很大程度上是无用的。
注意,由特定卷积层提取的表示的一般性(以及因此可重用性)的级别取决于模型中网络层的深度。模型中较早出现的图层会提取局部的,高度通用的特征贴图(例如可视边缘,颜色和纹理),而较高层的图层会提取更抽象的概念(例如“猫耳朵”或“狗眼”) 。因此,如果训练数据集与训练原始模型的数据集有很大差异,那么最好只使用模型的前几层来进行特征提取,而不是使用整个卷积网络的输出。
在这种情况下,因为ImageNet类集包含多个dog和cat类,所以重用原始模型的全连接层中包含的信息可能是有益的。但是我们会选择不这样做,以便涵盖新问题的类集不与原始模型的类集重叠的更一般情况。通过使用在ImageNet上训练的VGG16网络的卷积网络来实现这一点,从猫和狗图像中提取有趣的特征,然后在这些特征之上训练狗与猫的分类器。
Keras中可以直接获取VGG16模型,包含在keras.applications模块中。其中还包括其他模型:
Xception
Inception V3
ResNet50
VGG16
VGG19
MobileNet
实例化VGG16模型:
from keras.application import vgg16 conv_base = VGG16(weights='imagenet',include_top=False,input_shape=(150, 150, 3))
构造器的3个参数:
weights:读取权重保存点文件,初始化模型;
include_top:是否包含网络的全连接层。模型,全连接层分类类别在ImageNet上的1000类。因为要使用自己创建的全连接分类器,可以不使用原来的全连接层;
input_shape:送到模型中图片张量的形状;参数是可选的:如果不传递参数,网络可以处理任意形状的输入。
VGG16网络模型架构:
>>> conv_base.summary() Layer (type) Output Shape Param #================================================================ input_1 (InputLayer) (None, 150, 150, 3) 0________________________________________________________________ block1_conv1 (Convolution2D) (None, 150, 150, 64) 1792________________________________________________________________ block1_conv2 (Convolution2D) (None, 150, 150, 64) 36928________________________________________________________________ block1_pool (MaxPooling2D) (None, 75, 75, 64) 0________________________________________________________________ block2_conv1 (Convolution2D) (None, 75, 75, 128) 73856________________________________________________________________ block2_conv2 (Convolution2D) (None, 75, 75, 128) 147584________________________________________________________________ block2_pool (MaxPooling2D) (None, 37, 37, 128) 0________________________________________________________________ block3_conv1 (Convolution2D) (None, 37, 37, 256) 295168________________________________________________________________ block3_conv2 (Convolution2D) (None, 37, 37, 256) 590080________________________________________________________________ block3_conv3 (Convolution2D) (None, 37, 37, 256) 590080________________________________________________________________ block3_pool (MaxPooling2D) (None, 18, 18, 256) 0________________________________________________________________ block4_conv1 (Convolution2D) (None, 18, 18, 512) 1180160________________________________________________________________ block4_conv2 (Convolution2D) (None, 18, 18, 512) 2359808________________________________________________________________ block4_conv3 (Convolution2D) (None, 18, 18, 512) 2359808________________________________________________________________ block4_pool (MaxPooling2D) (None, 9, 9, 512) 0________________________________________________________________ block5_conv1 (Convolution2D) (None, 9, 9, 512) 2359808________________________________________________________________ block5_conv2 (Convolution2D) (None, 9, 9, 512) 2359808________________________________________________________________ block5_conv3 (Convolution2D) (None, 9, 9, 512) 2359808________________________________________________________________ block5_pool (MaxPooling2D) (None, 4, 4, 512) 0================================================================ Total params: 14,714,688Trainable params: 14,714,688Non-trainable params: 0
最后一层的特征图形状为(4,4,512).之后连接到全连接分类器上。有两种处理方法:
训练卷积网络模型部分,将输出结果保存在磁盘上,之后读取磁盘上的数据送到全连接分类器中。优点在于运行高效、快速,因为卷积网络部分针对每张输入图片只运行一次,而卷积部分是最耗时、耗费运算能力资源的;但同时不能使用数据增强;
将全连接分类器和卷积部分整合到一起,在输入数据上端到端的运行;可以使用数据增强,因为每次输入模型的图像都会通过模型经过卷积部分。
不使用数据增强的特征提取
使用ImageDataGenerator将磁盘文件和标签读取成张量形式,运行卷积部分的predict提取图片特征。
import osimport numpy as npfrom keras.preprocessing.image import ImageDataGenerator base_dir = '/Users/fchollet/Downloads/cats_and_dogs_small'train_dir = os.path.join(base_dir, 'train')#训练数据validation_dir = os.path.join(base_dir, 'validation')#验证数据test_dir = os.path.join(base_dir, 'test')#测试数据datagen = ImageDataGenerator(rescale=1./255)#batch_size = 20def extract_features(directory, sample_count):#读取文件,转换成张量形式; features = np.zeros(shape=(sample_count, 4, 4, 512)) labels = np.zeros(shape=(sample_count)) generator = datagen.flow_from_directory(directory, target_size=(150, 150), batch_size=batch_size, class_mode='binary') i = 0 for inputs_batch, labels_batch in generator:#生成对应批量数据 features_batch = conv_base.predict(inputs_batch)#卷积特征提取结果 features[i * batch_size : (i + 1) * batch_size] = features_batch labels[i * batch_size : (i + 1) * batch_size] = labels_batch i += 1 if i * batch_size >= sample_count: break return features, labels train_features, train_labels = extract_features(train_dir, 2000) validation_features,validation_labels=extract_features(validation_dir, 1000) test_features, test_labels = extract_features(test_dir, 1000)
当前提取特征形状为(samples,4,4,512),在送到全连接层之前,需要先平铺成(samples,8192),。
train_features = np.reshape(train_features, (2000, 4 * 4 * 512)) validation_features=np.reshape(validation_features, (1000, 4 * 4 * 512)) test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
定义全连接分类器,将特征数据送到分类器中训练。
from keras import modelsfrom keras import layersfrom keras import optimizers model = models.Sequential() model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512)) model.add(layers.Dropout(0.5)) model.add(layers.Dense(1, activation='sigmoid')) model.compile(optimizer=optimizers.RMSprop(lr=2e-5), loss='binary_crossentropy',metrics=['acc']) history = model.fit(train_features, train_labels,epochs=30, batch_size=20, validation_data=(validation_features, validation_labels))
验证集、训练集上损失值和准确率变化情况:
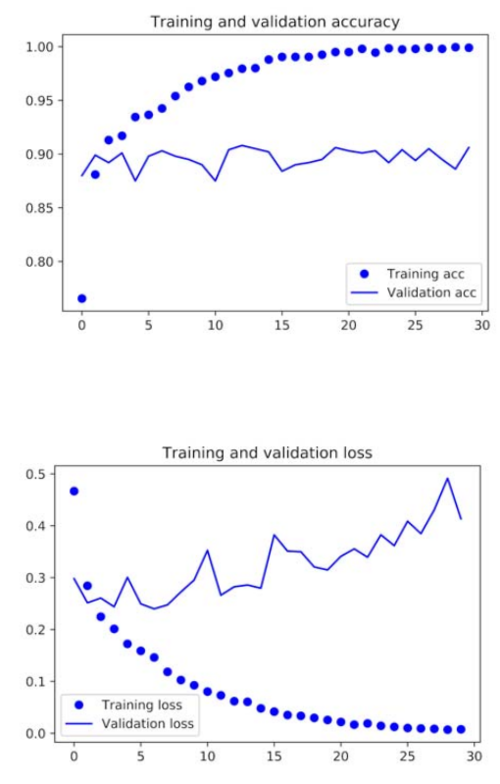
image
验证集准确率达到90%.但图示显示模型从开始就过拟合了。使用数据正增强可以缓解一下。
使用数据增强的特征提取
和第一种方法相比,运算速度更慢、耗费运算资源更多,通常需要GPU。如果GPU上速度还慢,最好使用第一种方法。
from keras import modelsfrom keras import layers model = models.Sequential() model.add(conv_base) model.add(layers.Flatten()) model.add(layers.Dense(256, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))
模型架构为:
>>> model.summary() Layer (type) Output Shape Param #================================================================ vgg16 (Model) (None, 4, 4, 512) 14714688________________________________________________________________ flatten_1 (Flatten) (None, 8192) 0________________________________________________________________ dense_1 (Dense) (None, 256) 2097408________________________________________________________________ dense_2 (Dense) (None, 1) 257================================================================ Total params: 16,812,353Trainable params: 16,812,353Non-trainable params: 0
在模型训练之前,需要对卷积部分进行freeze‘冻住’。Freezing网络层意味着避免在训练过程网络层的参数被更新。如果不做‘freeze’处理,训练过程中卷积部分提取的特征会逐渐改变。
在Keras中,可以通过设置trainable参数为False进行Freeze处理。
conv_base.trainable = False
注意,为了使这些更改生效,必须首先编译模型。如果在编译后修改了权重可训练性,则应重新编译模型,否则将忽略这些更改。
from keras.preprocessing.image import ImageDataGeneratorfrom keras import optimizers train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest') test_datagen = ImageDataGenerator(rescale=1./255) train_generator=train_datagen.flow_from_directory(train_dir, target_size=(150, 150), batch_size=20,class_mode='binary') validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(150, 150),batch_size=20,class_mode='binary') model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(lr=2e-5),metrics=['acc']) history = model.fit_generator(train_generator,steps_per_epoch=100, epochs=30,validation_data=validation_generator,validation_steps=50)
损失值和准确率变化:
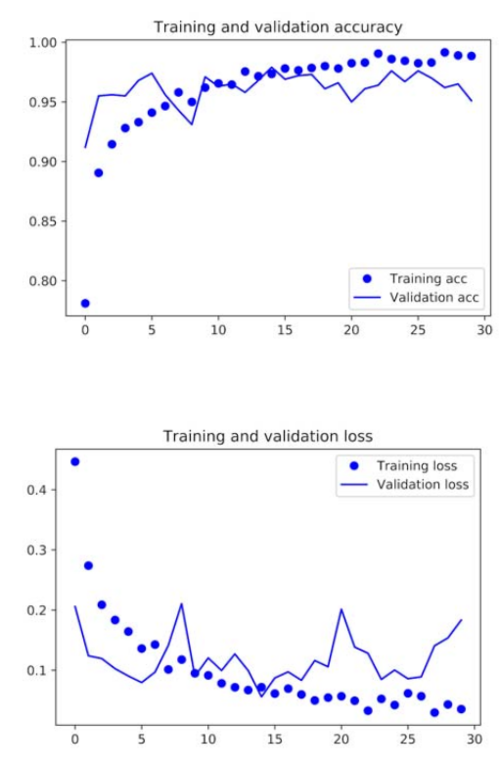
image
验证集上准确率达到96%.
模型微调Fine-tuning
另一种广泛使用的模型重用技术,对特征提取的补充,就是模型参数微调。微调包括解冻用于特征提取的冻结模型基础的一些顶层,并联合训练模型的新添加部分(在这种情况下,全连接的分类器)和这些顶层。这称为微调,因为它稍微调整了重复使用的模型的抽象表示,以使它们与手头的问题更相关。
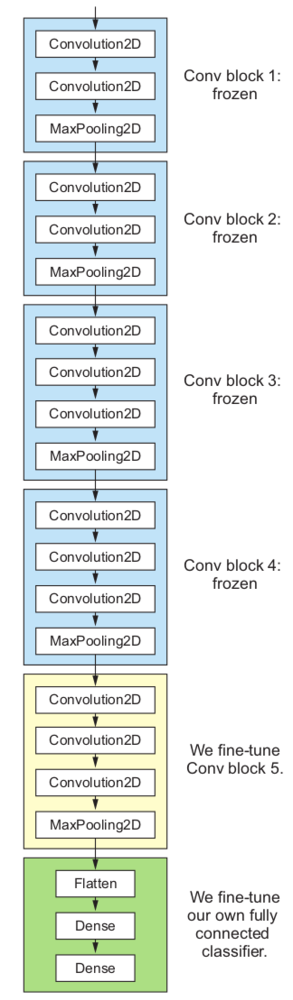
image
微调网络模型步骤:
在已经训练好的网络模型上添加自定义网络模型;
Freeze”冻住“训练好的模型;
训练添加部分网络;
Unfreeze”解冻“部分base 网络;
重新训练解冻部分和添加部分。
base部分网络模型:
>>> conv_base.summary() Layer (type) Output Shape Param #================================================================ input_1 (InputLayer) (None, 150, 150, 3) 0________________________________________________________________ block1_conv1 (Convolution2D)(None, 150, 150, 64) 1792________________________________________________________________ block1_conv2 (Convolution2D)(None, 150, 150, 64) 36928________________________________________________________________ block1_pool (MaxPooling2D) (None, 75, 75, 64) 0________________________________________________________________ block2_conv1 (Convolution2D)(None, 75, 75, 128) 73856________________________________________________________________ block2_conv2 (Convolution2D)(None, 75, 75, 128) 147584________________________________________________________________ block2_pool (MaxPooling2D) (None, 37, 37, 128) 0________________________________________________________________ block3_conv1 (Convolution2D)(None, 37, 37, 256) 295168________________________________________________________________ block3_conv2 (Convolution2D)(None, 37, 37, 256) 590080________________________________________________________________ block3_conv3 (Convolution2D)(None, 37, 37, 256) 590080________________________________________________________________ block3_pool (MaxPooling2D) (None, 18, 18, 256) 0________________________________________________________________ block4_conv1 (Convolution2D)(None, 18, 18, 512) 1180160________________________________________________________________ block4_conv2 (Convolution2D)(None, 18, 18, 512) 2359808________________________________________________________________ block4_conv3 (Convolution2D)(None, 18, 18, 512) 2359808________________________________________________________________ block4_pool (MaxPooling2D) (None, 9, 9, 512) 0________________________________________________________________ block5_conv1 (Convolution2D)(None, 9, 9, 512) 2359808________________________________________________________________ block5_conv2 (Convolution2D)(None, 9, 9, 512) 2359808________________________________________________________________ block5_conv3 (Convolution2D)(None, 9, 9, 512) 2359808________________________________________________________________ block5_pool (MaxPooling2D) (None, 4, 4, 512) 0================================================================ Total params: 14714688
微调模型的最后3个卷积层,意味着到block4_pool之前都被”冻住“,网络层block5_conv1,block5_conv2和block5_conv3都是可训练的。
为什么不微调更多层?为什么不微调整个卷积网络?可以这么做。但是你需要考虑以下几点:
卷积网络中的前几层编码更通用,可重用的特征,而更高层的编码更专业的特征。微调更专业的功能更有用,因为这些功能需要重新用于新问题。微调下层会有快速下降的回报。
训练的参数越多,越有可能过度拟合。卷积网络模型有1500万个参数,因此尝试在小数据集上训练它会有风险。
一个很好的策略是只微调卷积基础中的前两个或三个层。
conv_base.trainable = Trueset_trainable = Falsefor layer in conv_base.layers: if layer.name == 'block5_conv1':#block5_conv1可训练 set_trainable = True#flag可训练 if set_trainable: layer.trainable = True#block5_conv1网络层设置为可训练; else: layer.trainable = False#其它层不可训练
现在可以开始微调网络了。使用RMSProp优化器以非常低的学习速率执行此操作。使用低学习率的原因是希望限制对正在微调的三个网络层的表示所做的修改的幅度。太大的更新可能会损害这些表示。
model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(lr=1e-5),metrics=['acc']) history = model.fit_generator(train_generator,steps_per_epoch=100, epochs=100,validation_data=validation_generator,validation_steps=50)
验证集、测试集上损失函数和准确率变化:
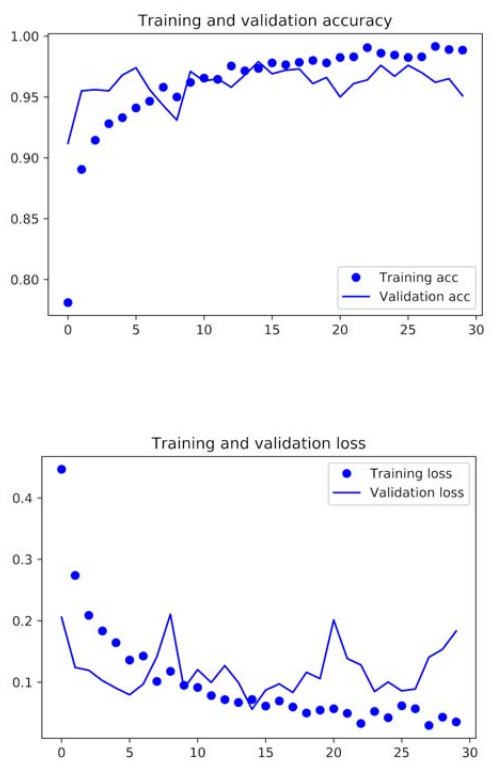
image
请注意,损失曲线没有显示任何真正的改善(事实上,它正在恶化)。如果损失没有减少,准确度如何保持稳定或改善?答案很简单:展示的是指数损失值的平均值;但是对于准确性而言重要的是损失值的分布,而不是它们的平均值,因为精度是模型预测的类概率的二元阈值的结果。即使没有反映在平均损失中,该模型仍可能会有所改善。
在测试集上评估:
test_generator = test_datagen.flow_from_directory(test_dir,
target_size=(150, 150),batch_size=20,class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator,steps=50)
print('test acc:', test_acc)#97%小结
Convnets是用于计算机视觉任务的最佳机器学习模型。即使在非常小的数据集上也可以从头开始训练,并获得不错的结果。
在小型数据集上,过度拟合将是主要问题。在处理图像数据时,数据增强是对抗过度拟合的有效方法;
通过重用现有的卷积网络模型可以在新数据集上做特征提取;这是处理小图像数据集的有用技术。
作为特征提取的补充,可以使用模型微调,让模型适应新问题---以前现有模型可以学习新问题的特征表示,能进一步推动性能。
卷积学习结果可视化
人们常说,深度学习模型是“黑匣子”:学习表示难以提取以及很难以人类可读的形式呈现。虽然对于某些类型的深度学习模型来说这是部分正确的,但对于convnets来说绝对不是这样。由convnet学习的表示非常适合可视化,这在很大程度上是因为它们是视觉概念的表示。三种常见的可视化方法:
可视化中间信号输出(中间激活)--有助于了解连续的convnet层如何转换输入数据,以及了解各个convnet过滤器的含义;
可视化convnets过滤器---有助于准确理解convnet中每个过滤器可接受的视觉模式或概念;
可视化图像中类激活的热图---有助于了解图像的哪些部分被识别为属于给定的类,从而可以在图像中本地化对象。
可视化中间激活值
可视化中间激活包括在给定特定输入的情况下显示由网络中的各种卷积和池化层输出的特征映射(层的输出通常称为其激活,激活函数的输出)。这给出了如何将输入分解为网络学习的不同过滤器的视图。希望从三个维度:宽度,高度和深度(通道)可视化特征图。每个通道编码相对独立的特征,因此可视化这些特征图的正确方法是通过将每个通道的内容独立地绘制为2D图像。
加载保存的模型
from keras.models import load_model
model = load_model('cats_and_dogs_small_2.h5')
img_path = './cats_and_dogs_small/test/cats/cat.1700.jpg'#给定一张图片from keras.preprocessing import imageimport numpy as np
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis=0)
img_tensor /= 255.查看所有网络层的输出结果:
from keras import models layer_outputs = [layer.output for layer in model.layers[:8]] activation_model=models.Model(inputs=model.input,outputs=layer_outputs)
输入图像输入时,此模型返回原始模型中网络层激活的值。一个多输出模型:到目前为止,看到的模型只有一个输入和一个输出。在一般情况下,模型可以具有任意数量的输入和输出。这个有一个输入和八个输出:每层激活一个输出。
模型运行:
activations = activation_model.predict(img_tensor)#输出:每层激活值一个数组
第一个卷积层结果:
first_layer_activation = activations[0] print(first_layer_activation.shape)#(1, 148, 148, 32)import matplotlib.pyplot as plt plt.matshow(first_layer_activation[0, :, :, 4], cmap='viridis')#第4通道可视化
image
网络中所有激活函数值可视化,将8个网络层激活函数值的所有通道结果显示出来。
layer_names = []for layer in model.layers[:8]:
layer_names.append(layer.name)
images_per_row = 16for layer_name, layer_activation in zip(layer_names, activations):
n_features = layer_activation.shape[-1]
size = layer_activation.shape[1]
n_cols = n_features // images_per_row
display_grid = np.zeros((size * n_cols, images_per_row * size)) for col in range(n_cols): for row in range(images_per_row):
channel_image=layer_activation[0,:,:,col*images_per_row+row]
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image=np.clip(channel_image,0, 255).astype('uint8')
display_grid[col*size:(col+1)*size,row*size:(row+1)*size]=channel_image
scale = 1. / size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, aspect='auto', cmap='viridis')[图片上传失败...(image-49e53e-1532251766723)]
值得注意的是:
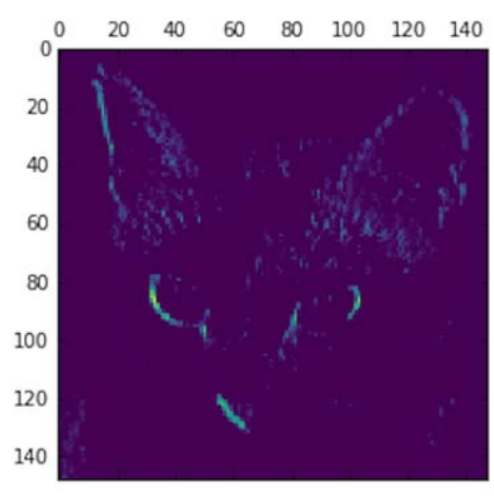
第一层充当各种边缘检测器的集合。在那个阶段,激活值几乎保留了初始图片中的所有信息;
随着网络层的增加,激活变得越来越抽象,在视觉上也不那么容易理解;开始编码更高级别的概念,如“猫耳”和“猫眼。”更高级别的表示关于图像的视觉内容越来越少,关于图像类型的信息越来越多;
激活的稀疏性随着层的深度而增加:在第一层中,所有滤波器都由输入图像激活;但在以下图层中,越来越多的过滤器为空白。这意味着在输入图像中找不到滤镜编码的图案。
刚刚证明了深度神经网络所学习的表征的一个重要的普遍特征:由层提取的特征随着层的深度而变得越来越抽象。更高层的激活越来越少地显示关于所看到的特定输入的信息,越来越多关于目标的信息. 深度神经网络有效地充当信息蒸馏管道,原始数据进入(在这种情况下为RGB图像)并被重复变换以便过滤掉无关信息(例如,图像的特定视觉外观),以及有用的信息被放大和细化(例如,图像的类)。
可视化卷积核
另一种检查由convnet学习的过滤器的简单方法是显示每个过滤器要响应的视觉模式。这可以通过输入空间中的渐变上升来完成:将渐变下降应用于convnet的输入图像的值空间上;从空白输入图像开始,最大化特定过滤器的响应。得到的输入图像将是所选滤波器最大响应的图像。
过程很简单:您将构建一个损失函数,使给定卷积层中给定滤波器的值最大化,然后您将使用随机梯度下降来调整输入图像的值,以便最大化此激活值。例如,这是在VGG16的block3_conv1中激活过滤器0的损失.
from keras.applications import VGG16from keras import backend as K model = VGG16(weights='imagenet',include_top=False) layer_name = 'block3_conv1'filter_index = 0layer_output=model.get_layer(layer_name).output#得到block3_conv1的激活值loss = K.mean(layer_output[:, :, :, filter_index])
要实现梯度下降,需要相对于模型输入求损失的梯度。
grads = K.gradients(loss, model.input)[0]
使用梯度正则化平滑梯度值
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
计算损失张量和梯度张量。使用keras的iterate函数,接收numpy张量,返回关于损失和梯度的张量列表。
iterate = K.function([model.input], [loss, grads])import numpy as np loss_value, grads_value = iterate([np.zeros((1, 150, 150, 3))])
将张量转换为图片格式:
def deprocess_image(x):
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
x += 0.5
x = np.clip(x, 0, 1)
x *= 255
x = np.clip(x, 0, 255).astype('uint8') return x整合卷积核可视化函数:
def generate_pattern(layer_name, filter_index, size=150): layer_output = model.get_layer(layer_name).output loss = K.mean(layer_output[:, :, :, filter_index]) grads = K.gradients(loss, model.input)[0] grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5) iterate = K.function([model.input], [loss, grads]) input_img_data = np.random.random((1, size, size, 3)) * 20 + 128. step = 1. for i in range(40): loss_value, grads_value = iterate([input_img_data]) input_img_data += grads_value * step img = input_img_data[0] return deprocess_image(img)
这些过滤器可视化展示了很多关于如何使用数字网络层来查看世界:网络中的每个层都学习了一组过滤器,以便它们的输入可以表示为过滤器的组合。
类别激活值heatmap可视化
一种可视化技术:有助于理解给定图像的哪些部分引导其进行最终分类决策的可视化技术。
这种通用类别的技术称为类激活图(CAM)可视化,它包括在输入图像上生成类激活的热图。类激活热图是与特定输出类相关联的分数的2D网格,针对任何输入图像中的每个位置计算,指示每个位置相对于所考虑的类的重要程度。

image
小结
Convnets是处理视觉分类问题的最佳工具;
Convnets通过学习模块化模式和概念的层次结构来表示视觉世界;
现在能够从头开始训练自己的网络以解决图像分类问题;
如何使用数据增强、重用预训练网络、微调与训练过网络来缓解过拟合现象;
生成由convnet学习的过滤器的可视化等。
作者:七八音
链接:https://www.jianshu.com/p/e887ba4ecd92
共同学习,写下你的评论
评论加载中...
作者其他优质文章



