
1.概述
在《HBase查询优化》一文中,介绍了基于HBase层面的读取优化。由于HBase的实际数据是以HFile的形式,存储在HDFS上。那么,HDFS层面也有它自己的优化点,即:Short-Circuit Local Reads。本篇博客笔者将从HDFS层面来进行优化,从而间接的提升HBase的查询性能。
2.内容
Hadoop系统在设计之初,遵循一个原则,那就是移动计算的代价比移动数据要小。故Hadoop在做计算的时候,通常是在本地节点上的数据中进行计算。即计算和数据本地化。流程如下图所示:

在最开始的时候,短回路本地化读取和跨节点的读取的处理方式是一样的,流程都是先从DataNode读取数据,然后通过RPC服务把数据传输给DFSClient,这样处理虽然流程比较简单,但是读取性能会受到影响,因为跨节点读取数据,需要经过网络将一个DataNode的数据传输到另外一个DataNode节点(一般来说,HDFS有3个副本,所以,本地取不到数据,会到其他DataNode节点去取数据)。
2.1 方案一:客户端直接读取DataNode文件
短回路本地化读取的核心思想是,由于客户端和数据在同一个节点上,所以DataNode不需要在数据路径中。相反,客户端本身可以简单地读取来自本地磁盘的数据。这种性能优化集成在CDH的Hadoop相关项目中,实现如下图所示:
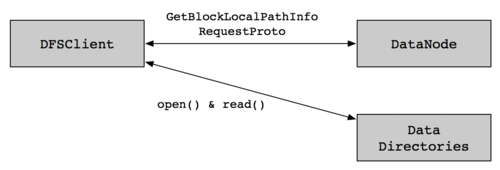
这种短回路本地化读取的思路虽然很好,但是配置问题比较麻烦。系统管理员必须更改DataNode数据目录的权限,以便客户端有权限能够打开相关文件。这样就不得不专门为那些能够使用短回路本地化读取的用户提供白名单,不允许其他用户使用。通常,这些用也必须被放置在一个特殊的UNIX组中。
另外,这种本地化短回路读取的思路还存在另外一个安全问题,客户端在读取DataNode数据目录时打开了一些权限,这样意味着,拥有这个目录的权限,那么其目录下的子目录中的数据也可以被访问,比如HBase用户。由于存在这种安全风险,所以这个实现思路已经不建议使用了。
2.2 方案二:短回路本地化安全读取
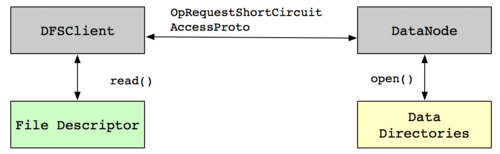
为了解决上述问题,在实际读取中需要非常小心的选择文件。在UNIX中有这样一种机制,叫做“文件描述符传递”。使用这种机制来实现安全的短回路本地读取,而不是通过目录名称的客户端,DataNode打开Block文件和元数据文件,将它们直接给客户端。因为文件描述符是只读的,用户不能修改文件。由于它没有进入Block目录本身,它无法读取任何不应该访问的目录。
举个例子:
现有两个用户hbase1和hbase2,hbase1拥有访问HDFS目录上/appdata/hbase1文件的权限,而hbase2用户没有改权限,但是hbase2用户又需要访问这个文件,那么可以借助这种“文件描述符传递”的机制,可以让hbase1用户打开文件得到一个文件描述符,然后把文件描述符传递给hbase2用户,那么hbase2用户就可以读取文件里面的内容了,即使hbase2用户没有权限。这种关系映射到HDFS中,可以把DataNode看作hbase1用户,客户端DFSClient看作hbase2用户,需要读取的文件就是DataNode目录中的/appdata/hbase1文件。实现如下图所示:
2.3 缓存文件描述
HDFS客户端可能会有经常读取相同Block文件的场景,为了提升这种读取性能,旧的短回路本地读取实现具有Block路径的高速缓存。该缓存允许客户端重新打开其最近已读取的Block文件,而不需要再去访问DataNode路径读取。
新的短回路本地读取实现不是一个路径缓存,而是一个名为FileInputStreamCache的文件描述符缓存。这样比路径缓存要更好一些,因为它不需要客户端重新打开文件来重新读取Block,这种读取方式比就的短回路本地读取方式在读性能上有更好的表现。
缓存的大小可以通过dfs.client.read.shortcircuit.streams.cache.size属性来进行调整,默认是256,缓存超时可以通过dfs.client.read.shortcircuit.streams.cache.expiry.ms属性来进行控制,默认是300000,也可以将其设置为0来将其进行关闭,这两个属性均在hdfs-site.xml文件中可以配置。
2.4 如何配置
为了配置短回路本地化读取,需要启用libhadoop.so,一般来说所使用Hadoop通常都是包含这些包的,可以通过以下命令来检测是否有安装:

$ hadoop checknative -a Native library checking: hadoop: true /home/ozawa/hadoop/lib/native/libhadoop.so.1.0.0 zlib: true /lib/x86_64-linux-gnu/libz.so.1 snappy: true /usr/lib/libsnappy.so.1 lz4: true revision:99 bzip2: false
短回路本地化读取利用UNIX的域套接字(UNIX domain socket),它在文件系统中有一个特定的路径,允许客户端和DataNode进行通信。在使用的时候需要设置这个路径到Socket中,同时DataNode需要能够创建这个路径。另外,这个路径应该不可能被除了hdfs用户或root用户之外的任何用户创建。因此,在实际创建时,通常会使用/var/run或者/var/lib路径。
短回路本地化读取在DataNode和客户端都需要配置,配置如下:
<configuration> <property> <name>dfs.client.read.shortcircuit</name> <value>true</value> </property> <property> <name>dfs.domain.socket.path</name> <value>/var/lib/hadoop-hdfs/dn_socket</value> </property> </configuration>
其中,配置dfs.client.read.shortcircuit属性是打开这个功能的开关,dfs.domain.socket.path属性是DataNode和客户端之间进行通信的Socket路径地址,核心指标配置参数如下:
| 属性 | 描述 |
| dfs.client.read.shortcircuit | 打开短回路本地化读取,默认false |
| dfs.client.read.shortcircuit.skip.checksum | 如果配置这个参数,短回路本地化读取将会跳过checksum,默认false |
| dfs.client.read.shortcircuit.streams.cache.size | 客户端维护一个最近打开文件的描述符缓存,默认256 |
| dfs.domain.socket.path | DataNode和客户端DFSClient通信的Socket地址 |
| dfs.client.read.shortcircuit.streams.cache.expiry.ms | 设置超时时间,用来设置文件描述符可以被放进FileInputStreamCache的最小时间 |
| dfs.client.domain.socket.data.traffic | 通过UNIX域套接字传输正常的数据流量,默认false |
3.总结
短回路本地化读取能够从HDFS层面来提升读取性能,如果HBase场景中,有涉及到读多写少的场景,在除了从HBase服务端和客户端层面优化外,还可以尝试从HDFS层面来进行优化。
4.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。
原文出处:https://www.cnblogs.com/smartloli/p/9462835.html
共同学习,写下你的评论
评论加载中...
作者其他优质文章



