
9 四大组件的工作过程
本章的意义在于加深对四大组件工作方式的认识,有助于加深对Android整体的体系结构的认识。很多情况下,只有对Android的体系结构有一定认识,在实际开发中才能写出优秀的代码。 读者对四大组件的工作过程有一个感性的认识并且能够给予上层开发一些指导意义。
9.1 四大组件的运行状态
Android的四大组件除了BroadcastReceiver以外,都需要在AndroidManifest文件注册,BroadcastReceiver可以通过代码注册。调用方式上,除了ContentProvider以外的三种组件都需要借助intent。
Activity
是一种展示型组件,用于向用户直接地展示一个界面,并且可以接收用户的输入信息从而进行交互,扮演的是一个前台界面的角色。Activity的启动由intent触发,有隐式和显式两种方式。一个Activity可以有特定的启动模式,finish方法结束Activity运行。
Service
是一种计算型组件,在后台执行一系列计算任务。它本身还是运行在主线程中的,所以耗时的逻辑仍需要单独的线程去完成。Activity只有一种状态:启动状态。而service有两种:启动状态和绑定状态。当service处于绑定状态时,外界可以很方便的和service进行通信,而在启动状态中是不可与外界通信的。Service可以停止, 需要灵活采用stopService和unBindService
BroadcastReceiver
是一种消息型组件,用于在不同的组件乃至不同的应用之间传递消
息。
静态注册
在清单文件中进行注册广播, 这种广播在应用安装时会被系统解析, 此种形式的广播不需要应用启动就可以接收到相应的广播.动态注册
需要通过Context.registerReceiver()来实现, 并在不需要的时候通过Context.unRegisterReceiver()来解除广播. 此种形态的广播要应用启动才能注册和接收广播. 在实际开发中通过Context的一系列的send方法来发送广播, 被发送的广播会被系统发送给感兴趣的广播接收者, 发送和接收的过程的匹配是通过广播接收者的<intent-filter>来描述的.可以实现低耦合的观察者模式, 观察者和被观察者之间可以没有任何耦合. 但广播不适合来做耗时操作.
ContentProvider
是一种数据共享型组件,用于向其他组件乃至其他应用共享数据。在它内部维持着一份数据集合, 这个数据集合既可以通过数据库来实现, 也可以采用其他任何类型来实现, 例如list或者map. ContentProvider对数据集合的具体实现并没有任何要求.要注意处理好内部的insert, delete, update, query方法的线程同步, 因为这几个方法是在Binder线程池被调用.
9.2 Activity的工作过程
Activity的所有 startActivity 重载方法最终都会调用 startActivityForResult 。
调用 mInstrumentation.execStartActivity.execStartActivity() 方法。
代码中启动Activity的真正实现是由ActivityManagerNative.getDefault().startActivity()方法完成的. ActivityManagerService简称AMS. AMS继承自ActivityManagerNative(), 而ActivityManagerNative()继承自Binder并实现了IActivityManager这个Binder接口, 因此AMS也是一个Binder, 它是IActivityManager的具体实现.ActivityManagerNative.getDefault()本质是一个IActivityManager类型的Binder对象, 因此具体实现是AMS.
在ActivityManagerNative中, AMS这个Binder对象采用单例模式对外提供, Singleton是一个单例封装类. 第一次调用它的get()方法时会通过create方法来初始化AMS这个Binder对象, 在后续调用中会返回这个对象.
AMS的startActivity()过程
checkStartActivityResult () 方法检查启动Activity的结果( 包括检查有无在
manifest注册)Activity启动过程经过两次转移, 最后又转移到了mStackSupervisor.startActivityMayWait()这个方法, 所属类为ActivityStackSupervisor. 在startActivityMayWait()内部又调用了startActivityLocked()这里会返回结果码就是之前checkStartActivityResult()用到的。
方法最后会调用startActivityUncheckedLocked(), 然后又调用了ActivityStack#resumeTopActivityLocked(). 这个时候启动过程已经从ActivityStackSupervisor转移到了ActivityStack类中
在最后的 ActivityStackSupervisor. realStartActivityLocked() 中,调用了 app.thread.scheduleLaunchActivity() 方法。 这个app.thread是ApplicationThread 类型,继承于 IApplicationThread 是一个Binder类,内部是各种启动/停止 Service/Activity的接口。
在ApplicationThread中, scheduleLaunchActivity() 用来启动Activity,里面的实现就是发送一个Activity的消息( 封装成 从ActivityClientRecord 对象) 交给Handler处理。这个Handler有一个简洁的名字 H 。
在H的 handleMessage() 方法里,通过 handleLaunchActivity() 方法完成Activity对象的创建和启动,并且ActivityThread通过handleResumeActivity()方法来调用被启动的onResume()这一生命周期方法。PerformLaunchActivity()主要完成了如下几件事:
从ActivityClientRecord对象中获取待启动的Activity组件信息
通过 Instrumentation 的 newActivity 方法使用类加载器创建Activity对象
通过 LoadedApk 的makeApplication方法尝试创建Application对象,通过类加载器实现( 如果Application已经创建过了就不会再创建)
创建 ContextImpl 对象并通过Activity的 attach 方法完成一些重要数据的初始化(ContextImpl是一个很重要的数据结构, 它是Context的具体实现, Context中的大部分逻辑都是由ContentImpl来完成的. ContextImpl是通过Activity的attach()方法来和Activity建立关联的,除此之外, 在attach()中Activity还会完成Window的创建并建立自己和Window的关联, 这样当Window接收到外部输入事件收就可以将事件传递给Activity.)
通过 mInstrumentation.callActivityOnCreate(activity, r.state) 方法调用Activity的 onCreate 方法
9.3 Service的工作过程
启动状态:执行后台计算
绑定状态:用于其他组件与Service交互
两种状态是可以共存的
9.3.1 Service的启动过程Service的启动从 ContextWrapper 的 startService 开始
在ContextWrapper中,大部分操作通过一个 ContextImpl 对象mBase实现
在ContextImpl中, mBase.startService() 会调用 startServiceCommon 方法,而
startServiceCommon方法又会通过 ActivityManagerNative.getDefault() ( 实际上就是AMS) 这个对象来启动一个服务。AMS会通过一个 ActiveService 对象( 辅助AMS进行Service管理的类,包括Service的启动,绑定和停止等) mServices来完成启动Service: mServices.startServiceLocked() 。
在mServices.startServiceLocked()最后会调用 startServiceInnerLocked() 方法:将Service的信息包装成一个 ServiceRecord 对象,ServiceRecord一直贯穿着整个Service的启动过程。通过 bringUpServiceLocked() 方法来处理,bringUpServiceLocked()又调用了 realStartServiceLocked() 方法,这才真正地去启动一个Service了。
realStartServiceLocked()方法的工作如下:
app.thread.scheduleCreateService() 来创建Service并调用其onCreate()生命周期方法
sendServiceArgsLocked() 调用其他生命周期方法,如onStartCommand()
app.thread对象是 IApplicationThread 类型,实际上就是一个Binder,具体实现是ApplicationThread继承ApplictionThreadNative
具体看Application对Service的启动过程app.thread.scheduleCreateService():通过 sendMessage(H.CREATE_SERVICE , s) ,这个过程和Activity启动过程类似,同时通过发送消息给Handler H来完成的。
H会接受这个CREATE_SERVICE消息并通过ActivityThread的 handleCreateService() 来完成Service的最终启动。
handleCreateService()完成了以下工作:
通过ClassLoader创建Service对象
创建Service内部的Context对象
创建Application,并调用其onCreate()( 只会有一次)
通过 service.attach() 方法建立Service与context的联系( 与Activity类似)
调用service的 onCreate() 生命周期方法,至此,Service已经启动了
将Service对象存储到ActivityThread的一个ArrayMap中
9.3.2 Service的绑定过程
和service的启动过程类似的:
Service的绑定是从 ContextWrapper 的 bindService 开始
在ContextWrapper中,交给 ContextImpl 对象 mBase.bindService()
最终会调用ContextImpl的 bindServiceCommon 方法,这个方法完成两件事:
将客户端的ServiceConnection转化成 ServiceDispatcher.InnerConnection 对象。ServiceDispatcher连接ServiceConnection和InnerConnection。这个过程通过 LoadedApk 的 getServiceDispatcher 方法来实现,将客户端的ServiceConnection和ServiceDispatcher的映射关系存在一个ArrayMap中。
通过AMS来完成Service的具体绑定过程 ActivityManagerNative.getDefault().bindService()
AMS中,bindService()方法再调用 bindServiceLocked() ,bindServiceLocked()再调用 bringUpServiceLocked() ,bringUpServiceLocked()又会调用 realStartServiceLocked() 。
AMS的realStartServiceLocked()会调用 ActiveServices 的requrestServiceBindingLocked() 方法,最终是调用了ServiceRecord对象r的 app.thread.scheduleBindService() 方法。
ApplicationThread的一系列以schedule开头的方法,内部都通过Handler H来中转:scheduleBindService()内部也是通过 sendMessage(H.BIND_SERVICE , s)
在H内部接收到BIND_SERVICE这类消息时就交给 ActivityThread 的handleBindService() 方法处理:
根据Servcie的token取出Service对象
调用Service的 onBind() 方法,至此,Service就处于绑定状态了。
这时客户端还不知道已经成功连接Service,需要调用客户端的binder对象来调用客户端的ServiceConnection中的 onServiceConnected() 方法,这个通过 ActivityManagerNative.getDefault().publishService() 进行。ActivityManagerNative.getDefault()就是AMS。
AMS的publishService()交给ActivityService对象 mServices 的 publishServiceLocked() 来处理,核心代码就一句话 c.conn.connected(r.name,service) 。对象c的类型是 ConnectionRecord ,c.conn就是ServiceDispatcher.InnerConnection对象,service就是Service的onBind方法返回的Binder对象。
c.conn.connected(r.name,service)内部实现是交给了mActivityThread.post(new RunnConnection(name ,service,0)); 实现。ServiceDispatcher的mActivityThread是一个Handler,其实就是ActivityThread中的H。这样一来RunConnection就经由H的post方法从而运行在主线程中,因此客户端ServiceConnection中的方法是在主线程中被回调的。
RunConnection的定义如下:
继承Runnable接口, run() 方法的实现也是简单调用了ServiceDispatcher的 doConnected 方法。
由于ServiceDispatcher内部保存了客户端的ServiceConntion对象,可以很方便地调用ServiceConntion对象的 onServiceConnected 方法。
客户端的onServiceConnected方法执行后,Service的绑定过程也就完成了。
根据步骤8、9、10service绑定后通过ServiceDispatcher通知客户端的过程可以说明ServiceDispatcher起着连接ServiceConnection和InnerConnection的作用。 至于Service的停止和解除绑定的过程,系统流程都是类似的。
9.4 BroadcastReceiver的工作过程
简单回顾一下广播的使用方法, 首先定义广播接收者, 只需要继承BroadcastReceiver并重写onReceive()方法即可. 定义好了广播接收者, 还需要注册广播接收者, 分为两种静态注册或者动态注册. 注册完成之后就可以发送广播了.
9.4.1 广播的注册过程
动态注册的过程是从ContextWrapper#registerReceiver()开始的. 和Activity或者Service一样. ContextWrapper并没有做实际的工作, 而是将注册的过程直接交给了ContextImpl来完成.
ContextImpl#registerReceiver()方法调用了本类的registerReceiverInternal()方法.
系统首先从mPackageInfo获取到IIntentReceiver对象, 然后再采用跨进程的方式向AMS发送广播注册的请求. 之所以采用IIntentReceiver而不是直接采用BroadcastReceiver, 这是因为上述注册过程中是一个进程间通信的过程. 而BroadcastReceiver作为Android中的一个组件是不能直接跨进程传递的. 所有需要通过IIntentReceiver来中转一下.
IIntentReceiver作为一个Binder接口, 它的具体实现是LoadedApk.ReceiverDispatcher.InnerReceiver, ReceiverDispatcher的内部同时保存了BroadcastReceiver和InnerReceiver, 这样当接收到广播的时候, ReceiverDispatcher可以很方便的调用BroadcastReceiver#onReceive()方法. 这里和Service很像有同样的类, 并且内部类中同样也是一个Binder接口.
由于注册广播真正实现过程是在AMS中, 因此跟进AMS中, 首先看registerReceiver()方法, 这里只关心里面的核心部分. 这段代码最终会把远程的InnerReceiver对象以及IntentFilter对象存储起来, 这样整个广播的注册就完成了.
9.4.2 广播的发送和接收过程
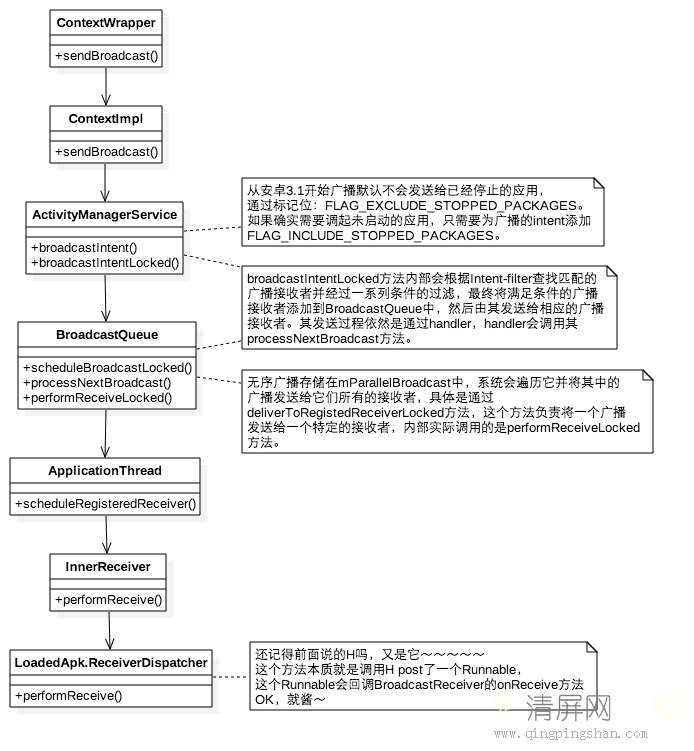
广播的发送有几种:普通广播、有序广播和粘性广播,他们的发送/接收流程是类似的,因此
只分析普通广播的实现。
广播的发送和接收, 本质就是一个过程的两个阶段. 广播的发送仍然开始于ContextImpl#sendBroadcase()方法, 之所以不是Context, 那是因为Context#sendBroad()是一个抽象方法. 和广播的注册过程一样, ContextWrapper#sendBroadcast()仍然什么都不做, 只是把事情交给了ContextImpl去处理.
ContextImpl里面也几乎什么都没有做, 内部直接向AMS发起了一个异步请求用于发送广播.
调用AMS#broadcastIntent()方法,继续调用broadcastIntentLocked()方法。
在broadcastIntentLocked()内部, 会根据intent-filter查找出匹配的广播接收者并经过一系列的条件过滤. 最终会将满足条件的广播接收者添加到BroadcastQueue中, 接着BroadcastQueue就会将广播发送给相应广播接收者.
BroadcastQueue#scheduleBroadcastsLocked()方法内并没有立即发送广播, 而是发送了一个BROADCAST_INTENT_MSG类型的消息, BroadcastQueue收到消息后会调用processNextBroadcast()方法。
无序广播存储在mParallelBroadcasts中, 系统会遍历这个集合并将其中的广播发送给他们所有的接收者, 具体的发送过程是通过deliverToRegisteredReceiverLocked()方法实现. deliverToRegisteredReceiverLocked()负责将一个广播发送给一个特定的接收者, 它的内部调用了performReceiverLocked方法来完成具体发送过程.
performReceiverLocked()方法调用的ApplicationThread#scheduleRegisteredReceiver()实现比较简单, 它通过InnerReceiver来实现广播的接收
scheduleRegisteredReceiver()方法中,receiver.performReceive()中的receiver对应着IIntentReceiver类型的接口. 而具体的实现就是ReceiverDispatcher$InnerReceiver. 这两个嵌套的内部类是所属在LoadedApk中的。
又调用了LoadedApk$ReceiverDispatcher#performReceive()的方法.在performReceiver()这个方法中, 会创建一个Args对象并通过mActivityThread的post方法执行args中的逻辑. 而这些类的本质关系就是:
Args: 实现类Runnable
mActivityThread: 是一个Handler, 就是ActivityThread中的mH. mH就是ActivityThread$H. 这个内部类H以前说过.
实现Runnable接口的Args中BroadcastReceiver#onReceive()方法被执行了, 也就是说应用已经接收到了广播, 同时onReceive()方法是在广播接收者的主线程中被调用的.
android 3.1开始就增添了两个标记为. 分别是FLAG_INCLUDE_STOPPED_PACKAGES, FLAG_EXCLUDE_STOPPED_PACKAGES. 用来控制广播是否要对处于停止的应用起作用.
FLAG_INCLUDE_STOPPED_PACKAGES: 包含停止应用, 广播会发送给已停止的应用.
FLAG_EXCLUDE_STOPPED_PACKAGES: 不包含已停止应用, 广播不会发送给已停止的应用
在android 3.1开始, 系统就为所有广播默认添加了FLAG_EXCLUDE_STOPPED_PACKAGES标识。 当这两个标记共存的时候以FLAG_INCLUDE_STOPPED_PACKAGES(非默认项为主).
应用处于停止分为两种
应用安装后未运行
被手动或者其他应用强停
开机广播同样受到了这个标志位的影响. 从Android 3.1开始处于停止状态的应用同样无法接受到开机广播, 而在android 3.1之前处于停止的状态也是可以接收到开机广播的.
9.5 ContentProvider的工作机制
ContentProvider是一种内容共享型组件, 它通过Binder向其他组件乃至其他应用提供数据. 当ContentProvider所在的进程启动时, ContentProvider会同时启动并发布到AMS中. 要注意:这个时候ContentProvider的onCreate()方法是先于Application的onCreate()执行的,这一点在四大组件是少有的现象
当一个应用启动时,入口方法是ActivityThread的main方法,其中创建ActivityThread的实例并创建主线程的消息队列;
ActivityThread的attach方法中会远程调用ActivityManagerService的attachApplication,并将ApplicationThread提供给AMS,ApplicationThread主要用于ActivityThread和AMS之间的通信;
ActivityManagerService的attachApplication会调用ApplicationThread的bindApplication方法,这个方法会通过H切换到ActivityThread中去执行,即调用handleBindApplication方法;
handleBindApplication方法会创建Application对象并加载ContentProvider,注意是先加载ContentProvider,然后调用Application的onCreate方法。
ContentProvider启动后, 外界就可以通过它所提供的增删改查这四个接口来操作ContentProvider中的数据源, 这四个方法都是通过Binder来调用的, 外界无法直接访问ContentProvider, 它只能通过AMS根据URI来获取到对应的ContentProvider的Binder接口IContentProvider, 然后再通过IContentProvider来访问ContentProvider中的数据源.
ContentProvider的android:multiprocess属性决定它是否是单实例,默认值是false,也就是默认是单实例。当设置为true时,每个调用者的进程中都存在一个ContentProvider对象。
当调用ContentProvider的insert、delete、update、query方法中的任何一个时,如果ContentProvider所在的进程没有启动的话,那么就会触发ContentProvider的创建,并伴随着ContentProvider所在进程的启动。
以query调用为
首先会获取IContentProvider对象, 不管是通过acquireUnstableProvider()方法还是直接通过acquireProvider()方法, 他们的本质都是一样的, 最终都是通过acquireProvider方法来获取ContentProvider.
ApplicationContentResolver#acquireProvider()方法并没有处理任何逻辑, 它直接调用了ActivityThread#acquireProvider()
从ActivityThread中查找是否已经存在了ContentProvider了, 如果存在那么就直接返回. ActivityThread中通过mProviderMap来存储已经启动的ContentProvider对象, 这个集合的存储类型ArrayMap mProviderMap. 如果目前ContentProvider没有启动, 那么就发送一个进程间请求给AMS让其启动项目目标ContentProvider, 最后再通过installProvider()方法来修改引用计数.
AMS是如何启动ContentProvider的呢?首先会启动ContentProvider所在的进程, 然后再启动ContentProvider. 启动进程是由AMS#startProcessLocked()方法来完成, 其内部主要是通过Process#start()方法来完成一个新进程的启动, 新进程启动后其入口方法为ActivityThread#main()方法。
ActivityThread#main()是一个静态方法, 在它的内部首先会创建ActivityThread实例并调用attach()方法来进行一系列初始化, 接着就开始进行消息循环. ActivityThread#attach()方法会将Application对象通过AMS#attachApplication方法跨进程传递给AMS, 最终AMS会完成ContentProvider的创建过程.
AMS#attachApplication()方法调用了attachApplication(), 然后又调用了ApplicationThread#bindApplication(), 这个过程也属于进程通信.bindApplication()方法会发送一个BIND_APPLICATION类型的消息给mH, 这是一个Handler, 它收到消息后会调用ActivityThread#handleBindApplication()方法.
ActivityThread#handlerBindApplication()则完成了Application的创建以及ContentProvider 可以分为如下四个步骤:
创建ContentProvider和Instrumentation
创建Application对象
启动当前进程的ContentProvider并调用onCreate()方法. 主要内部实现是installContentProvider()完成了ContentProvider的启动工作, 首先会遍历当前进程的ProviderInfo的列表并一一调用installProvider()方法来启动他们, 接着将已经启动的ContentProvider发布到AMS中, AMS会把他们存储在ProviderMap中, 这样一来外部调用者就可以直接从AMS中获取到ContentProvider. installProvider()内部通过类加载器创建的ContentProvider实例并在方法中调用了attachInfo(), 在这内部调用了ContentProvider#onCreate()
调用Application#onCreate()
经过了上述的四个步骤, ContentProvider已经启动成功, 并且其所在的进程的Application也已经成功, 这意味着ContentProvider所在的进程已经完成了整个的启动过程, 然后其他应用就可以通过AMS来访问这个ContentProvider了.
当拿到了ContentProvider以后, 就可以通过它所提供的接口方法来访问它. 这里要注意: 这里的ContentProvider并不是原始的ContentProvider. 而是ContentProvider的Binder类型对象IContentProvider, 而IContentProvider的具体实现是ContentProviderNative和ContentProvider.Transport. 后者继承了前者.
如果还用query方法来解释流程: 那么最开始其他应用通过AMS获取到ContentProvider的Binder对象就是IContentProvider. 而IContentProvider的实际实现者是ContentProvider.Transport. 因此实际上外部应用调用的时候本质上会以进程间通信的方式调用ContentProvider.Transport的query()方法。
10 Android的消息机制
Android的消息机制主要是指Handler的运行机制。从开发的角度来说,Handler是Android消息机制的上层接口。Handler的运行需要底层的 MessageQueue 和 Looper 的支撑。
MessageQueue是一个消息队列,内部存储了一组消息,以队列的形式对外提供插入和删除的工作,内部采用单链表的数据结构来存储消息列表。
Lopper会以无限循环的形式去查找是否有新消息,如果有就处理消息,否则就一直等待着。
ThreadLocal并不是线程,它的作用是在每个线程中存储数据。Handler通过ThreadLocal可以获取每个线程中的Looper。
线程是默认没有Looper的,使用Handler就必须为线程创建Looper。我们经常提到的主线程,也叫UI线程,它就是ActivityThread,被创建时就会初始化Looper。
10.1 Android的消息机制概述
Handler的主要作用是将某个任务切换到Handler所在的线程中去执行。为什么Android要提供这个功能呢?这是因为Android规定访问UI只能通过主线程,如果子线程访问UI,程序可能会导致ANR。那我们耗时操作在子线程执行完毕后,我们需要将一些更新UI的操作切换到主线程当中去。所以系统就提供了Handler。
系统为什么不允许在子线程中去访问UI呢? 因为Android的UI控件不是线程安全的,多线程并发访问可能会导致UI控件处于不可预期的状态,为什么不加锁?因为加锁机制会让UI访问逻辑变得复杂;其次锁机制会降低UI访问的效率,因为锁机制会阻塞某些线程的执行。所以Android采用了高效的单线程模型来处理UI操作。
Handler创建时会采用当前线程的Looper来构建内部的消息循环系统,如果当前线程没有Looper就会报错。Handler可以通过post方法发送一个Runnable到消息队列中,也可以通过send方法发送一个消息到消息队列中,其实post方法最终也是通过send方法来完成。
MessageQueue的enqueueMessage方法最终将这个消息放到消息队列中,当Looper发现有新消息到来时,处理这个消息,最终消息中的Runnable或者Handler的handleMessage方法就会被调用,注意Looper是运行Handler所在的线程中的,这样一来业务逻辑就切换到了Handler所在的线程中去执行了。
10.2 Android的消息机制分析
10.2.1 ThreadLocal的工作原理
ThreadLocal是一个线程内部的数据存储类,通过它可以在指定线程中存储数据,数据存储后,只有在指定线程中可以获取到存储的数据,对于其他线程来说无法获得数据。
在某些特殊的场景下,ThreadLocal可以轻松实现一些很复杂的功能。Looper、ActivityThread以及AMS都用到了ThreadLocal。当某些数据是以线程为作用域并且不同线程具有不同的数据副本的时候,就可以考虑采用ThreadLocal。
对于Handler来说,它需要获取当前线程的Looper,而Looper的作用于就是线程并且不同的线程具有不同的Looper,通过ThreadLocal可以轻松实现线程中的存取。
ThreadLocal的另一个使用场景是可以让监听器作为线程内的全局对象而存在,在线程内部只要通过get方法就可以获取到监听器。如果不采用ThreadLocal,只能采用函数参数调用和静态变量的方式。而第一种方式在调用栈很深时很糟糕,第二种方式不具有扩展性,比如同时多个线程执行。
虽然在不同线程访问同一个ThreadLocal对象,但是获得的值却是不同的。不同线程访问同一个ThreadLoacl的get方法,ThreadLocal的get方法会从各自的线程中取出一个数组,然后再从数组中根据当前ThreadLocal的索引去查找对应的Value值。
ThreadLocal的set方法:
public void set(T value) {
Thread currentThread = Thread.currentThread();
//通过values方法获取当前线程中的ThreadLoacl数据——localValues
Values values = values(currentThread);
if (values == null) {
values = initializeValues(currentThread);
}
values.put(this, value);
}在 localValues 内部有一个数组: private Object[] table ,ThreadLocal的值就存在这个数组中。
ThreadLocal的值在table数组中的存储位置总是ThreadLocal的reference字段所标识的对象的下一个位置。
ThreadLocal的get方法:
public T get() {
// Optimized for the fast path.
Thread currentThread = Thread.currentThread();
Values values = values(currentThread);//找到localValues对象
if (values != null) {
Object[] table = values.table;
int index = hash & values.mask;
if (this.reference == table[index]) {//找到ThreadLocal的reference对象在table数组中的位置
return (T) table[index + 1];//reference字段所标识的对象的下一个位置就是ThreadLocal的值
}
} else {
values = initializeValues(currentThread);
}
return (T) values.getAfterMiss(this);
}从ThreadLocal的set/get方法可以看出,它们所操作的对象都是当前线程的localValues对象的table数组,因此在不同线程中访问同一个ThreadLocal的set/get方法,它们ThreadLocal的读/写操作仅限于各自线程的内部。理解ThreadLocal的实现方式有助于理解Looper的工作原理。
10.2.2 消息队列的工作原理
消息队列指的是MessageQueue,主要包含两个操作:插入和读取。读取操作本身会伴随着删除操作。
MessageQueue内部通过一个单链表的数据结构来维护消息列表,这种数据结构在插入和删除上的性能比较有优势。
插入和读取对应的方法分别是:enqueueMessage和next方法。
enqueueMessage()的源码实现主要操作就是单链表的插入操作
next()的源码实现也是从单链表中取出一个元素的操作,next()方法是一个无线循环的方法,如果消息队列中没有消息,那么next方法会一直阻塞在这里。当有新消息到来时,next()方法会返回这条消息并将其从单链表中移除。
10.2.3 Looper的工作原理
Looper在Android的消息机制中扮演着消息循环的角色,具体来说就是它会不停地从MessageQueue中查看是否有新消息,如果有新消息就会立即处理,否则就一直阻塞在那里。
通过Looper.prepare()方法即可为当前线程创建一个Looper,再通过Looper.loop()开启消息循环。prepareMainLooper()方法主要给主线程也就是ActivityThread创建Looper使用的,本质也是通过prepare方法实现的。
Looper提供quit和quitSafely来退出一个Looper,区别在于quit会直接退出Looper,而quitSafely会把消息队列中已有的消息处理完毕后才安全地退出。 Looper退出后,这时候通过Handler发送的消息会失败,Handler的send方法会返回false。
在子线程中,如果手动为其创建了Looper,在所有事情做完后,应该调用Looper的quit方法来终止消息循环,否则这个子线程就会一直处于等待状态;而如果退出了Looper以后,这个线程就会立刻终止,因此建议不需要的时候终止Looper。
loop()方法会调用MessageQueue的next()方法来获取新消息,而next是是一个阻塞操作,但没有信息时,next方法会一直阻塞在那里,这也导致loop方法一直阻塞在那里。如果MessageQueue的next方法返回了新消息,Looper就会处理这条消息:msg.target.dispatchMessage(msg),这里的msg.target是发送这条消息的Handler对象,这样Handler发送的消息最终又交给Handler来处理了。
10.2.4 Handler的工作原理
Handler的工作主要包含消息的发送和接收过程。通过post的一系列方法和send的一系列方法来实现。
Handler发送过程仅仅是向消息队列中插入了一条消息。MessageQueue的next方法就会返回这条消息给Looper,Looper拿到这条消息就开始处理,最终消息会交给Handler的dispatchMessage()来处理,这时Handler就进入了处理消息的阶段。
handler处理消息的过程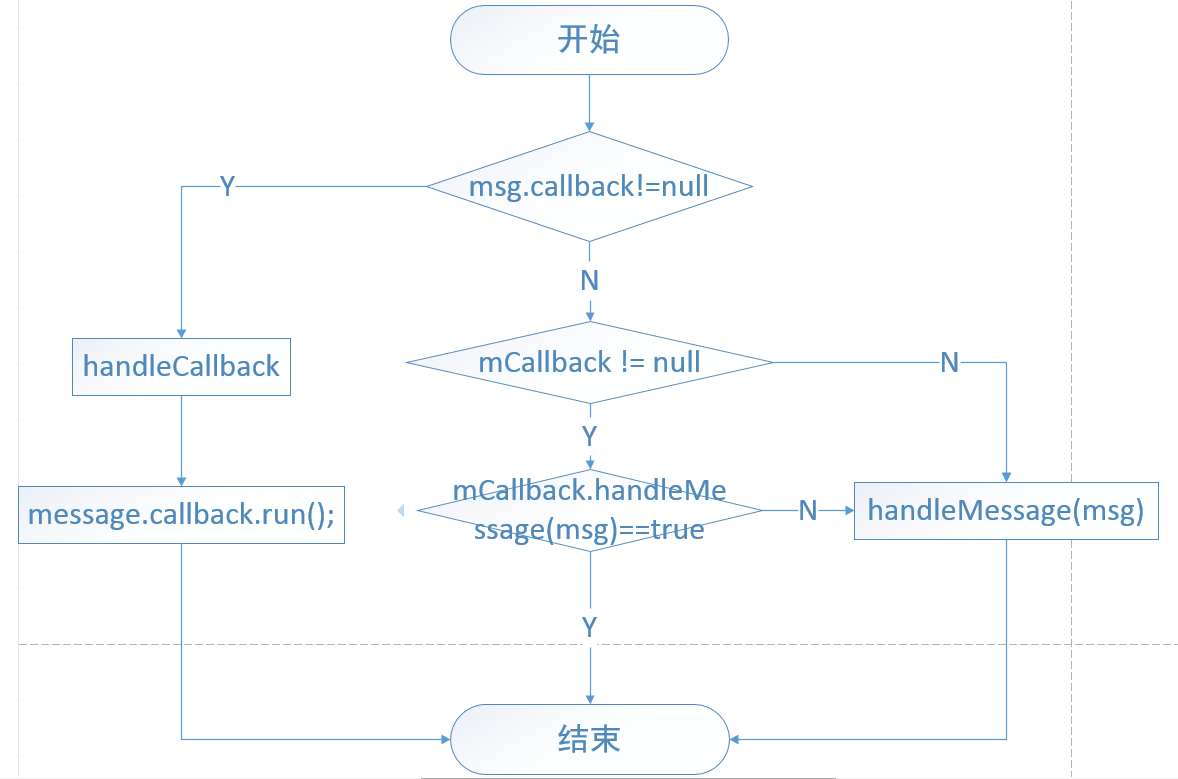
Handler的构造方法
派生Handler的子类
通过Callback
Handler handler = new Handler(callback)
其中,callback接口定义如下public interface Callback{ public boolean handleMessage(Message msg); }通过Looper
public Handler(Looper looper){ this(looper,null,false); }
10.3 主线程的消息循环
Android的主线程就是ActivityThread,主线程的入口方法为main(String[] args),在main方法中系统会通过Looper.prepareMainLooper()来创建主线程的Looper以及MessageQueue,并通过Looper.loop()来开启主线程的消息循环。
ActivityThread通过ApplicationThread和AMS进行进程间通信,AMS以进程间通信的方式完成ActivityThread的请求后会回调ApplicationThread中的Binder方法,然后ApplicationThread会向H发送消息,H收到消息后会将ApplicationThread中的逻辑切换到ActivityTread中去执行,即切换到主线程中去执行。四大组件的启动过程基本上都是这个流程。
Looper.loop(),这里是一个死循环,如果主线程的Looper终止,则应用程序会抛出异常。那么问题来了,既然主线程卡在这里了,(1)那Activity为什么还能启动;(2)点击一个按钮仍然可以响应?
问题1:startActivity的时候,会向AMS(ActivityManagerService)发一个跨进程请求(AMS运行在系统进程中),之后AMS启动对应的Activity;AMS也需要调用App中Activity的生命周期方法(不同进程不可直接调用),AMS会发送跨进程请求,然后由App的ActivityThread中的ApplicationThread会来处理,ApplicationThread会通过主线程线程的Handler将执行逻辑切换到主线程。重点来了,主线程的Handler把消息添加到了MessageQueue,Looper.loop会拿到该消息,并在主线程中执行。这就解释了为什么主线程的Looper是个死循环,而Activity还能启动,因为四大组件的生命周期都是以消息的形式通过UI线程的Handler发送,由UI线程的Looper执行的。
问题2:和问题1原理一样,点击一个按钮最终都是由系统发消息来进行的,都经过了Looper.loop()处理。 问题2详细分析请看原书作者的Android中MotionEvent的来源和ViewRootImpl。
11 Android的线程和线程池
在Android系统,线程主要分为主线程和子线程,主线程处理和界面相关的事情,而子线程一般用于执行耗时操作。AsyncTask底层是线程池;IntentService/HandlerThread底层是线程;
在Android中,线程的形态有很多种:
AsyncTask封装了线程池和Handler。
HandlerThread是具有消息循环的线程,内部可以使用handler
IntentService是一种Service,内部采用HandlerThread来执行任务,当任务执行完毕后IntentService会自动退出。由于它是一种Service,所以不容易被系统杀死
操作系统中,线程是操作系统调度的最小单元,同时线程又是一种受限的系统资源,其创建和销毁都会有相应的开销。同时当系统存在大量线程时,系统会通过时间片轮转的方式调度每个线程,因此线程不可能做到绝对的并发,除非线程数量小于等于CPU的核心数。
频繁创建销毁线程不明智,使用线程池是正确的做法。线程池会缓存一定数量的线程,通过线程池就可以避免因为频繁创建和销毁线程所带来的系统开销。
11.1 主线程和子线程
主线程主要处理界面交互逻辑,由于用户随时会和界面交互,所以主线程在任何时候都需要有较高响应速度,则不能执行耗时的任务;
android3.0开始,网络访问将会失败并抛出NetworkOnMainThreadException这个异常,这样做是为了避免主线程由于被耗时操作所阻塞从而现ANR现象
11.2 Android中的线程形态
11.2.1 AsyncTask
AsyncTask是一种轻量级的异步任务类, 他可以在线程池中执行后台任务, 然后把执行的进度和最终的结果传递给主线程并在主线程更新UI. 从实现上来说. AsyncTask封装了Thread和Handler, 通过AsyncTask可以更加方便地执行后台任务,但是AsyncTask并不适合进行特别耗时的后台任务,对于特别耗时的任务来说, 建议使用线程池。
AsyncTask就是一个抽象的泛型类. 这三个泛型的意义
Params:参数的类型
Progress:后台任务的执行进度的类型
Result:后台任务的返回结果的类型
如果不需要传递具体的参数, 那么这三个泛型参数可以用Void来代替.
四个方法 :
onPreExecute()
在主线程执行, 在异步任务执行之前, 此方法会被调用, 一般可以用于做一些准备工作doInBackground()
在线程池中执行, 此方法用于执行异步任务, 参数params表示异步任务的输入参数. 在此方法中可以通过publishProgress()方法来更新任务的进度, publishProgress()方法会调用onProgressUpdate()方法. 另外此方法需要返回计算结果给onPostExecute()onProgressUpdate()
在主线程执行,在异步任务执行之后, 此方法会被调用, 其中result参数是后台任务的返回值, 即doInBackground()的返回值.onPostExecute()
在主线程执行, 在异步任务执行之后, 此方法会被调用, 其中result参数是后台任务的返回值, 即doInBackground的返回值.
除了上述的四种方法,还有onCancelled(), 它同样在主线程执行, 当异步任务被取消时, onCancelled()方法会被调用, 这个时候onPostExecute()则不会被调用.
AsyncTask在使用过程中有一些条件限制
AsyncTask的类必须在主线程被加载, 这就意味着第一次访问AsyncTask必须发生在主线程, 这个问题不是绝对, 因为在Android 4.1及以上的版本已经被系统自动完成. 在Android 5.0的源码中, 可以看到ActivityThread#main()会调用AsyncTask#init()方法.
AsyncTask的对象必须在主线程中创建.
execute方法必须在UI线程调用.
不要在程序中直接调用onPreExecute(), onPostExecute(), doInBackground和onProgressUpdate()
一个AsyncTask对象只能执行一次, 即只能调用一次execute()方法, 否则会报运行时异常.
在Android 1.6之前, AsyncTask是串行执行任务的; Android 1.6的时候AsyncTask开始采用线程池里处理并行任务; 但是Android 3.0开始, 为了避免AsyncTask带来的并发错误, AsyncTask又采用了一个线程来串行的执行任务. 尽管如此在3.0以后, 仍然可以通过AsyncTask#executeOnExecutor()方法来并行执行任务.
11.2.2 AsyncTask的工作原理
AsyncTask中有两个线程池(SerialExecutor和THREAD_POOL_EXECUTOR)和一个Handler(InternalHandler), 其中线程池SerialExecutor用于任务的排列, 而线程池THREAD_POOL_EXECUTOR用于真正的执行任务, 而InternalHandler用于将执行环境从线程切换到主线程, 其本质仍然是线程的调用过程.
AsyncTask的排队过程:首先系统会把AsyncTask#Params参数封装成FutureTask对象, FutureTask是一个并发类, 在这里充当了Runnable的作用. 接着这个FutureTask会交给SerialExecutor#execute()方法去处理. 这个方法首先会把FutureTask对象插入到任务队列mTasks中, 如果这个时候没有正在活动AsyncTask任务, 那么就会调用SerialExecutor#scheduleNext()方法来执行下一个AsyncTask任务. 同时当一个AsyncTask任务执行完后, AsyncTask会继续执行其他任务直到所有的任务都执行完毕为止, 从这一点可以看出, 在默认情况下, AsyncTask是串行执行的
11.2.3 HandlerThread
HandlerThread继承了Thread, 它是一种可以使用Handler的Thread, 它的实现也很简单, 就是run方法中通过Looper.prepare()来创建消息队列, 并通过Looper.loop()来开启消息循环, 这样在实际的使用中就允许在HandlerThread中创建Handler.
从HandlerThread的实现来看, 它和普通的Thread有显著的不同之处. 普通的Thread主要用于在run方法中执行一个耗时任务; 而HandlerThread在内部创建了消息队列, 外界需要通过Handler的消息方式来通知HandlerThread执行一个具体的任务. HandlerThread是一个很有用的类, 在Android中一个具体使用场景就是IntentService.
由于HandlerThread#run()是一个无线循环方法, 因此当明确不需要再使用HandlerThread时, 最好通过quit()或者quitSafely()方法来终止线程的执行.
11.2.4 IntentService
IntentSercie是一种特殊的Service,继承了Service并且是抽象类,任务执行完成后会自动停止,优先级远高于普通线程,适合执行一些高优先级的后台任务; IntentService封装了HandlerThread和Handler
onCreate方法自动创建一个HandlerThread
用它的Looper构造了一个Handler对象mServiceHandler,这样通过mServiceHandler发送的消息都会在HandlerThread执行;
IntentServiced的onHandlerIntent方法是一个抽象方法,需要在子类实现,onHandlerIntent方法执行后,stopSelt(int startId)就会停止服务,如果存在多个后台任务,执行完最后一个stopSelf(int startId)才会停止服务。
11.3 Android线程池
优点:
重用线程池的线程,减少线程创建和销毁带来的性能开销
控制线程池的最大并发数,避免大量线程互相抢系统资源导致阻塞
提供定时执行和间隔循环执行功能
Android中的线程池的概念来源于Java中的Executor, Executor是一个接口, 真正的线程池的实现为ThreadPoolExecutor.Android的线程池 大部分都是通 过Executor提供的工厂方法创建的。 ThreadPoolExecutor提供了一系列参数来配制线程池, 通过不同的参数可以创建不同的线程池. 而从功能的特性来分的话可以分成四类.
11.3.1 ThreadPoolExecutor
ThreadPoolExecutor是线程池的真正实现, 它的构造方法提供了一系列参数来配置线程池, 这些参数将会直接影响到线程池的功能特性.
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}corePoolSize: 线程池的核心线程数, 默认情况下, 核心线程会在线程池中一直存活, 即使都处于闲置状态. 如果将ThreadPoolExecutor#allowCoreThreadTimeOut属性设置为true, 那么闲置的核心线程在等待新任务到来时会有超时的策略, 这个时间间隔由keepAliveTime属性来决定. 当等待时间超过了keepAliveTime设定的值那么核心线程将会终止.
maximumPoolSize: 线程池所能容纳的最大线程数, 当活动线程数达到这个数值之后, 后续的任务将会被阻塞.
keepAliveTime: 非核心线程闲置的超时时长, 超过这个时长, 非核心线程就会被回收. allowCoreThreadTimeOut这个属性为true的时候, 这个属性同样会作用于核心线程.
unit: 用于指定keepAliveTime参数的时间单位, 这是一个枚举, 常用的有TimeUtil.MILLISECONDS(毫秒), TimeUtil.SECONDS(秒)以及TimeUtil.MINUTES(分)
workQueue: 线程池中的任务队列, 通过线程池的execute方法提交的Runnable对象会存储在这个参数中.
threadFactory: 线程工厂, 为线程池提供创建新线程的功能. ThreadFactory是一个接口.
ThreadPoolExecutor执行任务大致遵循如下规则:
如果线程池中的线程数量未达到核心线程的数量, 那么会直接启动一个核心线程来执行任务.
如果线程池中的线程数量已经达到或者超过核心线程的数量, 那么任务会被插入到任务队列中排队等待执行.
如果在步骤2中无法将任务插入到任务队列中, 这通常是因为任务队列已满, 这个时候如果线程数量未达到线程池的规定的最大值, 那么会立刻启动一个非核心线程来执行任务.
如果步骤3中的线程数量已经达到最大值的时候, 那么会拒绝执行此任务,ThreadPoolExecutor会调用RejectedExecution方法来通知调用者.
AsyncTask的THREAD_POOL_EXECUTOR线程池配置:
核心线程数等于CPU核心数+1
线程池最大线程数为CPU核心数的2倍+1
核心线程无超时机制,非核心线程的闲置超时时间为1秒
任务队列容量是128
11.3.2 线程池的分类
FixedThreadPool
通过Executor#newFixedThreadPool()方法来创建. 它是一种线程数量固定的线程池, 当线程处于空闲状态时, 它们并不会被回收, 除非线程池关闭了. 当所有的线程都处于活动状态时, 新任务都会处于等待状态, 直到有线程空闲出来. 由于FixedThreadPool只有核心线程并且这些核心线程不会被回收, 这意味着它能够更加快速地响应外界的请求.
CachedThreadPool
通过Executor#newCachedThreadPool()方法来创建. 它是一种线程数量不定的线程池, 它只有非核心线程, 并且其最大值线程数为Integer.MAX_VALUE. 这就可以认为这个最大线程数为任意大了. 当线程池中的线程都处于活动的时候, 线程池会创建新的线程来处理新任务, 否则就会利用空闲的线程来处理新任务. 线程池中的空闲线程都有超时机制, 这个超时时长为60S, 超过这个时间那么空闲线程就会被回收.
和FixedThreadPool不同的是, CachedThreadPool的任务队列其实相当于一个空集合, 这将导致任何任务都会立即被执行, 因为在这种场景下SynchronousQueue是无法插入任务的. SynchronousQueue是一个非常特殊的队列, 在很多情况下可以把它简单理解为一个无法存储元素的队列. 在实际使用中很少使用.这类线程比较适合执行大量的耗时较少的任务
ScheduledThreadPool
通过Executor#newScheduledThreadPool()方法来创建. 它的核心线程数量是固定的, 而非核心线程数是没有限制的, 并且当非核心线程闲置时会立刻被回收掉. 这类线程池用于执行定时任务和具有固定周期的重复任务
SingleThreadExecutor
通过Executor#newSingleThreadPool()方法来创建. 这类线程池内部只有一个核心线程, 它确保所有的任务都在同一个线程中按顺序执行. 这类线程池意义在于统一所有的外界任务到一个线程中, 这使得在这些任务之间不需要处理线程同步的问题
12 Bitmap的加载和Cache
主要介绍:
如何高效地加载一个Bitmap
Android中常用的缓存策略
如何优化列表的卡顿
12.1 Bitmap的高效加载
先来简单介绍一下如何加载一个Bitmap, Bitmap在android中指的是一张图片, 可以是png格式也可以是jpg等其他常见的图片格式.
那么如何加载一个图片?首先BitmapFactory类提供了四种方法: decodeFile(), decodeResource(), decodeStream(), decodeByteArray(). 分别用于从文件系统, 资源文件, 输入流以及字节数组加载出一个Bitmap对象. 其中decodeFile和decodeResource又间接调用了decodeStream()方法, 这四类方法最终是在Android的底层实现的, 对应着BitmapFactory类的几个native方法.
高效加载的Bitmap的核心思想:采用BitmapFactory.Options来加载所需尺寸的图片. 比如说一个ImageView控件的大小为300300. 而图片的大小为800800. 这个时候如果直接加载那么就比较浪费资源, 需要更多的内存空间来加载图片, 这不是很必要的. 这里我们就可以先把图片按一定的采样率来缩小图片在进行加载. 不仅降低了内存占用,还在一定程度上避免了OOM异常. 也提高了加载bitmap时的性能.
而通过Options参数来缩放图片: 主要是用到了inSampleSize参数, 即采样率.
如果是inSampleSize=1那么和原图大小一样,
如果是inSampleSize=2那么宽高都为原图1/2, 而像素为原图的1/4, 占用的内存大小也为原图的1/4
如果是inSampleSize=3那么宽高都为原图1/3, 而像素为原图的1/9, 占用的内存大小也为原图的1/9
以此类推…..
要知道Android中加载图片具体在内存中的占有的大小是根据图片的像素决定的, 而与图片的实际占用空间大小没有关系.而且如果要加载mipmap下的图片, 还会根据不同的分辨率下的文件夹进行不同的放大缩小.
列举现在有一张图片像素为:10241024, 如果采用ARGB8888(四个颜色通道每个占有一个字节,相当于1点像素占用4个字节的空间)的格式来存储.(这里不考虑不同的资源文件下情况分析) 那么图片的占有大小就是102410244那现在这张图片在内存中占用4MB.
如果针对刚才的图片进行inSampleSize=2, 那么最后占用内存大小为512512*4, 也就是1MB
采样率的数值必须是大于1的整数是才会有缩放效果, 并且采样率同时作用于宽/高, 这将导致缩放后的图片以这个采样率的2次方递减, 即内存占用缩放大小为1/(inSampleSize的二次方). 如果小于1那么相当于=1的时候. 在官方文档中指出, inSampleSize的取值应该总是为2的指数, 比如1,2,4,8,16,32…如果外界传递inSampleSize不为2的指数, 那么系统会向下取整并选择一个最接近的2的指数来代替. 比如如果inSampleSize=3,那么系统会选择2来代替. 但是这条规则并不作用于所有的android版本, 所以可以当成一个开发建议
整理一下开发中代码流程:
将BitmapFactory.Options的inJustDecodeBounds参数设置为true并加载图片.
从BitmapFactory.Options取出图片的原始宽高信息, 他们对应于outWidth和outHeight参数
根据采样率的规则并结合目标View的所需大小计算出采样率inSampleSize
将BitmapFactory.Options的inJustDecodeBounds参数设为false, 然后重新加载.
inJustDecodeBounds这个参数的作用就是在加载图片的时候是否只是加载图片宽高信息而不把图片全部加载到内存. 所以这个操作是个轻量级的.
通过这些步骤就可以整理出以下的工具加载图片类调用decodeFixedSizeForResource()即可.
public class MyBitmapLoadUtil {
/**
* 对一个Resources的资源文件进行指定长宽来加载进内存, 并把这个bitmap对象返回
*
* @param res 资源文件对象
* @param resId 要操作的图片id
* @param reqWidth 最终想要得到bitmap的宽度
* @param reqHeight 最终想要得到bitmap的高度
* @return 返回采样之后的bitmap对象
*/
public static Bitmap decodeFixedSizeForResource(Resources res, int resId, int reqWidth, int reqHeight){
// 首先先指定加载的模式 为只是获取资源文件的大小
BitmapFactory.Options options = new BitmapFactory.Options();
options.inJustDecodeBounds = true;
BitmapFactory.decodeResource(res, resId, options);
//Calculate Size 计算要设置的采样率 并把值设置到option上
options.inSampleSize = calculateInSampleSize(options, reqWidth, reqHeight);
// 关闭只加载属性模式, 并重新加载的时候传入自定义的options对象
options.inJustDecodeBounds = false;
return BitmapFactory.decodeResource(res, resId, options);
}
/**
* 一个计算工具类的方法, 传入图片的属性对象和 想要实现的目标大小. 通过计算得到采样值
*/
private static int calculateInSampleSize(BitmapFactory.Options options, int reqWidth, int reqHeight) {
//Raw height and width of image
//原始图片的宽高属性
final int height = options.outHeight;
final int width = options.outWidth;
int inSampleSize = 1;
// 如果想要实现的宽高比原始图片的宽高小那么就可以计算出采样率, 否则不需要改变采样率
if (reqWidth < height || reqHeight < width){
int halfWidth = width/2;
int halfHeight = height/2;
// 判断原始长宽的一半是否比目标大小小, 如果小那么增大采样率2倍, 直到出现修改后原始值会比目标值大的时候
while((halfHeight/inSampleSize) >= reqHeight && (halfWidth/inSampleSize) >= reqWidth){
inSampleSize *= 2;
}
}
return inSampleSize;
}
}12.2 Android中的缓存策略
当程序第一次从网络上加载图片后,将其缓存在存储设备中,下次使用这张图片的时候就不用再从网络从获取了。很多时候为了提高应用的用户体验,往往还会把图片在内存中再缓存一份,因为从内存中加载图片比存储设备中快。一般情况会把图片存一份到内存中,一份到存储设备中,如果内存中没找到就去存储设备中找,还没有找到就从网络上下载。
缓存策略包含缓存的添加、获取和删除操作。不管是内存还是存储设备,缓存大小都是有限制的。如何删除旧的缓存并添加新的缓存,就对应缓存算法。
目前常用的一种缓存算法是LRU(Least Recently Used), 最近最少使用算法. 核心思想: 当缓存存满时, 会优先淘汰那些近期最少使用的缓存对象. 采用LRU算法的缓存有两种: LruCache和DiskLruCache,LruCache用于实现内存缓存, DiskLruCache则充当了存储设备缓存, 当组合使用后就可以实现一个类似ImageLoader这样的类库.
12.2.1 LruCache
LruCache是Android 3.1所提供的一个缓存类, 通过support-v4兼容包可以兼容到早期的Android版本
LruCache是一个泛型类, 它内部采用了一个LinkedHashMap以强引用的方式存储外界的缓存对象, 其提供了get和put方法来完成缓存的获取和添加的操作. 当缓存满了时, LruCache会移除较早使用的缓存对象, 然后在添加新的缓存对象. 普及一下各种引用的区别:
强引用: 直接的对象引用
软引用: 当一个对象只有软引用存在时, 系统内存不足时此对象会被gc回收
弱引用: 当一个对象只有弱引用存在时, 对象会随下一次gc时被回收
LruCache是线程安全的。
LruCache 典型初始化过程:
int maxMemory = (int) (Runtime.getRuntime().maxMemory() / 1024);
int cacheSize = maxMemory / 8;
mMemoryCache = new LruCache<String, Bitmap>(cacheSize) {
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getRowBytes() * value.getHeight() / 1024;
}
};这里只需要提供缓存的总容量大小(一般为进程可用内存的1/8)并重写 sizeOf 方法即可.sizeOf方法作用是计算缓存对象的大小。这里大小的单位需要和总容量的单位(这里是kb)一致,因此除以1024。一些特殊情况下,需要重写LruCache的entryRemoved方法,LruCache移除旧缓存时会调用entryRemoved方法,因此可以在entryRemoved中完成一些资源回收工作(如果需要的话)。
还有获取和添加方法,都比较简单:
mMemoryCache.get(key) mMemoryCache.put(key,bitmap)
通过remove方法可以删除一个指定的对象。
从Android 3.1开始,LruCache称为Android源码的一部分。
12.2.2 DiskLruCache
DiskLruCache用于实现磁盘缓存,DiskLruCache得到了Android官方文档推荐,但它不属于Android SDK的一部分,源码在这里。
DiskLruCache的创建
DiskLruCache并不能通过构造方法来创建, 他提供了open()方法用于创建自身, 如下所示
public static DiskLruCache open(File directory, int appVersion, int valueCount, long maxSize)
File directory: 表示磁盘缓存在文件系统中的存储路径. 可以选择SD卡上的缓存目录, 具体是指/sdcard/Andriod/data/package_name/cache目录, package_name表示当前应用的包名, 当应用被卸载后, 此目录会一并删除掉. 也可以选择data目录下. 或者其他地方. 这里给出的建议:如果应用卸载后就希望删除缓存文件的话 , 那么就选择SD卡上的缓存目录, 如果希望保留缓存数据那就应该选择SD卡上的其他目录.
int appVersion: 表示应用的版本号, 一般设为1即可. 当版本号发生改变的时候DiskLruCache会清空之前所有的缓存文件, 在实际开发中这个实用性不大.
int valueCount: 表示单个节点所对应的数据的个数, 一般设为1.
long maxSize: 表示缓存的总大小, 比如50MB, 当缓存大小超出这个设定值后, DiskLruCache会清除一些缓存而保证总大小不大于这个设定值.
//初始化DiskLruCache,包括一些参数的设置
public void initDiskLruCache
{
//配置固定参数
// 缓存空间大小
private static final long DISK_CACHE_SIZE = 1024 * 1024 * 50;
//下载图片时的缓存大小
private static final long IO_BUFFER_SIZE = 1024 * 8;
// 缓存空间索引,用于Editor和Snapshot,设置成0表示Entry下面的第一个文件
private static final int DISK_CACHE_INDEX = 0;
//设置缓存目录
File diskLruCache = getDiskCacheDir(mContext, "bitmap");
if(!diskLruCache.exists())
diskLruCache.mkdirs();
//创建DiskLruCache对象,当然是在空间足够的情况下
if(getUsableSpace(diskLruCache) > DISK_CACHE_SIZE)
{
try
{
mDiskLruCache = DiskLruCache.open(diskLruCache,
getAppVersion(mContext), 1, DISK_CACHE_SIZE);
mIsDiskLruCache = true;
}catch(IOException e)
{
e.printStackTrace();
}
}
}
//上面的初始化过程总共用了3个方法
//设置缓存目录
public File getDiskCacheDir(Context context, String uniqueName) {
String cachePath;
if (Environment.MEDIA_MOUNTED.equals(Environment
.getExternalStorageState())
|| !Environment.isExternalStorageRemovable()) {
cachePath = context.getExternalCacheDir().getPath();
} else {
cachePath = context.getCacheDir().getPath();
}
return new File(cachePath + File.separator + uniqueName);
}
// 获取可用的存储大小
@TargetApi(VERSION_CODES.GINGERBREAD)
private long getUsableSpace(File path) {
if (Build.VERSION.SDK_INT >= VERSION_CODES.GINGERBREAD)
return path.getUsableSpace();
final StatFs stats = new StatFs(path.getPath());
return (long) stats.getBlockSize() * (long) stats.getAvailableBlocks();
}
//获取应用版本号,注意不同的版本号会清空缓存
public int getAppVersion(Context context) {
try {
PackageInfo info = context.getPackageManager().getPackageInfo(
context.getPackageName(), 0);
return info.versionCode;
} catch (NameNotFoundException e) {
e.printStackTrace();
}
return 1;
}DiskLruCache的缓存添加
DiskLruCache的缓存添加的操作是通过Editor完成的, Editor表示一个缓存对象的编辑对象.
如果还是缓存图片为例子, 每一张图片都通过图片的url为key, 这里由于url可能会有特殊字符所以采用url的md5值作为key. 根据这个key就可以通过edit()来获取Editor对象, 如果这个缓存对象正在被编辑, 那么edit()就会返回null. 即DiskLruCache不允许同时编辑一个缓存对象.
当用.edit(key)获得了Editor对象之后. 通过editor.newOutputStream(0)就可以得到一个文件输出流. 由于之前open()方法设置了一个节点只能有一个数据. 所以在获得输出流的时候传入常量0即可.
有了文件输出流, 可以当网络下载图片时, 图片就可以通过这个文件输出流写入到文件系统上.最后,要通过Editor中commit()来提交写操作, 如果下载中发生异常, 那么使用Editor中abort()来回退整个操作.
DiskLruCache的缓存查找
和缓存的添加过程类似, 缓存查找过程也需要将url转换成key, 然后通过DiskLruCache#get()方法可以得到一个Snapshot对象, 接着在通过Snapshot对象即可得到缓存的文件输入流, 有了文件输入流, 自然就可以得到Bitmap对象. 为了避免加载图片出现OOM所以采用压缩的方式. 在前面对BitmapFactory.Options的使用说明了. 但是这中方法对FileInputStream的缩放存在问题. 原因是FileInputStream是一种有序的文件流, 而两次decodeStream调用会影响文件的位置属性, 这样在第二次decodeStream的时候得到的会是null. 针对这一个问题, 可以通过文件流来得到它所对应的文件描述符, 然后通过BitmapFactory.decodeFileDescription()来加载一张缩放后的图片.
/**
* 磁盘缓存的读取
* @param url
* @param reqWidth
* @param reqHeight
* @return
*/
private Bitmap loadBitmapFromDiskCache(String url, int reqWidth, int reqHeight) throws IOException
{
if(Looper.myLooper() == Looper.getMainLooper())
Log.w(TAG, "it's not recommented load bitmap from UI Thread");
if(mDiskLruCache == null)
return null;
Bitmap bitmap = null;
String key = hashKeyForDisk(url);
Snapshot snapshot = mDiskLruCache.get(key);
if(snapshot != null)
{
FileInputStream fileInputStream = (FileInputStream) snapshot.getInputStream(DISK_CACHE_INDEX);
FileDescriptor fd = fileInputStream.getFD();
bitmap = mImageResizer.decodeSampleBitmapFromFileDescriptor(fd, reqWidth, reqHeight);
if(bitmap != null)
addBitmapToMemoryCache(key, bitmap);
}
return bitmap;
}12.2.3 ImageLoader的实现
一个好的ImageLoader应该具备以下几点:
图片的压缩
网络拉取
内存缓存
磁盘缓存
图片的同步加载
图片的异步加载
图片压缩功能
ImageResizer
内存缓存和磁盘缓存
ImageLoader
同步加载和异步加载的接口设计
ImageLoader 173行
异步加载过程:
bindBitmap先尝试从内存缓存读取图片,如果没有会在线程池中调用loadBitmap方法。获取成功将图片封装为LoadResult对象通过mMainHandler向UI线程发送消息。选择线程池和Handler来提供并发能力和异步能力。
为了解决View复用导致的列表错位问题,在给ImageView设置图片之前都会检查它的url有没有发生改变,如果改变就不再给它设置图片。(76行)
12.3 ImageLoader的使用
12.3.1 照片墙效果
实现照片墙效果,如果图片都需要是正方形;这样做很快,自定义一个ImageView,重写onMeasure方法。
@Override
protected void onMeasure(int widthMeasureSpec,int heightMeasureSpec){
super.onMeasure(widthMeasureSpec,widthMeasureSpec);//将原来的参数heightMeasureSpec换成widthMeasureSpec
}12.3.2 优化列表的卡顿现象
不要在getView中执行耗时操作,不要在getView中直接加载图片。
控制异步任务的执行频率:如果用户刻意频繁上下滑动,getView方法会不停调用,从而产生大量的异步任务。可以考虑在列表滑动停止加载图片;给ListView或者GridView设置 setOnScrollListener 并在 OnScrollListener 的 onScrollStateChanged 方法中判断列表是否处于滑动状态,如果是的话就停止加载图片。
大部分情况下,可以使用硬件加速解决莫名卡顿问题,通过设置 android:hardwareAccelerated=”true” 即可为Activity开启硬件加速。
13 综合技术
本章主要讲解:
CrashHandler来监视App的crash信息
通过Google的multiDex方案解决Android方法数超过65536的问题
Android动态加载dex
反编译
13.1 使用CrashHandler来获取应用的crash信息
如何检测崩溃并了解详细的crash信息? 首先需实现一个uncaughtExceptionHandler对象,在它的uncaughtException方法中获取异常信息并将其存储到SD卡或者上传到服务器中,然后调用Thread的setDefaultUncaughtExceptionHandler为当前进程的所有线程设置异常处理器。
在Application初始化的时候为线程设置CrashHandler,这样之后,Crash就会通过我们自己的异常处理器来处理异常了。
public class BaseApplication extends Application {
@Override
public void onCreate() {
super.onCreate();
CrashHandler crashHandler = CrashHandler.getInstance();
crashHandler.init(this);
}
}13.2 使用multidex来解决方法数越界
Android中单个dex文件所能包含的最大方法数为65536, 这包含了FrameWork, 依赖的jar包以及应用本身的代码中的所有方法. 会爆出:
com.android.dex.DexIndexOverflowException: method ID not in[0, 0xffff] :65536
可能在一些低版本的手机, 即使没有超过方法数的上限却还是出现错误
E/dalvikvm: Optimization failed E/installd: dexopt failed on '/data/dalvik-cache/.....'
这个现象, 首先dexpot是一个程序, 应用在安装时, 系统会通过dexopt来优化dex文件, 在优化过程中dexopt采用一个固定大小的缓冲区来存储应用中所有方法消息, 这个缓冲区就是linearAlloc. LinearAlloc缓冲区在新版本的Android系统中大小为8MB或者16MB. 在Android 2.2和2.3中却只有5MB. 这是如果方法过多, 即使方法数没有超过65535也有可能会因为存储空间失败而无法安装.
解决方案
插件化: 是一套重量级的技术方案, 通过将一个dex拆分成两个或者多个dex,可以在一定程度上解决方法数的越界问题. 但是还有兼容性问题需要考虑, 所以需要权衡是否需要使用这个方案.
multidex: 这是Google在2014年提出的解决方案.在Android5.0之前需要引入Google提供的android-support-multidex.jar;从5.0开始系统默认支持了multidex,它可以从apk文件中加载多个dex文件。
使用步骤:
修改对应工程目录下的build.gradle文件,在defaultConfig中添加multiDexEnabled
true这个配置项。在build.gradle的dependencies中添加multidex的依赖:compile
‘com.android.support:multidex:#1.0.0’代码中加入支持multidex功能。
第一种方案,在manifest文件中指定Application为MultiDexApplication。
第二种方案,让应用的Application继承MultiDexApplication。
第三种方案,重写 attachBaseContext 方法,这个方法比onCreate还要先执行。
public class BaseApplication extends Application { @Override protected void attachBaseContext(Context base) { super.attachBaseContext(base); MultiDex.install(this); } }
采用上面的配置项后,如果这个应用方法数没有越界,那么Gradle是不会生成多个dex文件的,当方法数越界后,Gradle就会在apk中打包2个或多个dex文件。当需要指定主dex文件中所包含的类,这时候就需要通过—multi-dex-list来选项来实现这个功能。
//在对应工程目录下的build.gradle文件,加入
afterEvaluate {
println "afterEvaluate"
tasks.matching {
it.name.startsWith('dex')
}.each { dx ->
def listFile = project.rootDir.absolutePath + '/app/maindexlist.txt'
println "root dir:" + project.rootDir.absolutePath
println "dex task found: " + dx.name
if (dx.additionalParameters == null) {
dx.additionalParameters = []
}
dx.additionalParameters += '--multi-dex'
dx.additionalParameters += '--main-dex-list=' + listFile
dx.additionalParameters += '--minimal-main-dex'
}
}maindexlist.txt
com/ryg/multidextest/TestApplication.class com/ryg/multidextest/MainActivity.class // multidex 这9个类必须在主Dex中 android/support/multidex/MultiDex.class android/support/multidex/MultiDexApplication.class android/support/multidex/MultiDexExtractor.class android/support/multidex/MultiDexExtractor$1.class android/support/multidex/MultiDex$V4.class android/support/multidex/MultiDex$V14.class android/support/multidex/MultiDex$V19.class android/support/multidex/ZipUtil.class android/support/multidex/ZipUtil$CentralDirectory.class
需要注意multidex的jar中的9个类必须要打包到主dex中,因为Application的attachBaseContext方法中需要用到MultiDex.install(this)需要用到MultiDex。
Multidex的缺点:
启动速度会降低,由于应用启动时会加载额外的dex文件,这将导致应用的启动速度降低,甚至产生ANR现象。
因为Dalvik linearAlloc的bug,可以导致使用multidex的应用无法在Android4.0之前的手机上运行,需要做大量兼容性测试。
13.3 Android动态加载技术
动态加载也叫插件化. 当项目越来越大的时候, 可以通过插件化来减轻应用的内存和CPU占用. 还可以实现热插拔, 即可以在不发布新版本的情况下更新某些模块.
学习一下作者的插件化开源框架:dynamic-load-apk
各种插件化方案都需要解决3个基础性问题
宿主和插件的概念:宿主是指普通的apk, 而插件一般指经过处理的dex或者apk. 在主流的插件化框架中多采用经过处理的apk来作为插件, 处理方式往往和编译以及打包环节有关, 另外很多插件化框架都需要用到代理Activity的概念, 插件Activity的启动大多数是借助一个代理Activity来实现.
资源访问
插件中凡是以R开头的资源文件都不能访问。
Activity的工作主要是通过ContextImpl完成的,Activity中有一个mBase的成员变量,它的类型就是ContextImpl。Context有两个获取资源的抽象方法getAsssets()和getResources();只要实现这两个方法就可以解决资源问题。
protected void loadResources() {
try {
AssetManager assetManager = AssetManager.class.newInstance();
Method addAssetPath = assetManager.getClass().getMethod("addAssetPath", String.class);
addAssetPath.invoke(assetManager, mDexPath);
mAssetManager = assetManager;
} catch (Exception e) {
e.printStackTrace();
}
Resources superRes = super.getResources();
mResources = new Resources(mAssetManager, superRes.getDisplayMetrics(),
superRes.getConfiguration());
mTheme = mResources.newTheme();
mTheme.setTo(super.getTheme());
}从loadResources()的实现看出,加载资源的方法是反射,通过调用AssetManager的addAssetPath方法,我们可以将一个apk中的资源加载到Resources对象中。传递的路径可以是zip或资源目录,因此直接将apk的路径传给它,资源就加载到AssetManager了。然后再通过AssetManager创建一个新的Resources对象,通过这个对象就可以访问插件apk中的资源了。
接着在代理Activity中实现getAssets()和getResources()。关于代理Activity参考作者的插件化开源框架。
@Override
public AssetManager getAssets() {
return mAssetManager == null ? super.getAssets() : mAssetManager;
}
@Override
public Resources getResources() {
return mResources == null ? super.getResources() : mResources;
}Activity的生命周期管理
为什么会有这个问题,其实很好理解,apk被宿主程序调起以后,apk中的activity其实就是一个普通的对象,不具有activity的性质,因为系统启动activity是要做很多初始化工作的,而我们在应用层通过反射去启动activity是很难完成系统所做的初始化工作的,所以activity的大部分特性都无法使用包括activity的生命周期管理,这就需要我们自己去管理。
ClassLoader的管理
为了避免多个ClassLoader加载了同一个类所引发的类型转换错误。将不同插件的ClassLoader存储在一个HashMap中。
13.4 反编译初步
使用dex2jar和jd-gui反编译apk
使用apktool对apk进行二次打包
以上网上资料特别多,不赘述。
14 JNI与NDK编程
Java JNI本意为Java Native Interface(java本地接口), 是为方便java调用C或者C++等本地代码所封装的一层接口. 由于Java的跨平台性导致本地交互能力的不好, 一些和操作系统相关的特性Java无法完成, 于是Java提供了JNI专门用于和本地代码交互.
NDK是android所提供的一个工具合集, 通过NDK可以在Android中更加方便地通过JNI来访问本地代码. NDK还提供了交叉编译工具, 开发人员只需要简单的修改mk文件就可以生成特定的CPU平台的动态库. 好处如下:
代码的保护。由于apk的java层代码很容易被反编译,而C/C++库反编译难度较大。
可以方便地使用C/C++开源库。
便于移植,用C/C++写的库可以方便在其他平台上再次使用
提供程序在某些特定情形下的执行效率,但是并不能明显提升Android程序的性能。
14.1 JNI的开发流程
在Java中声明natvie方法
创建一个类
生命了两个native方法:get和set(String)。这是需要在JNI实现的方法。JniTest头部有一个加载动态库的过程, 加载so库名称填入的虽然是jni-test, 但是so库全名称应该是libjni-test.so,这是加载so库的规范。
编辑Java源文件得到class文件, 然后通过javah命令导出JNI头文件
在包的的根路径, 进行命令操作
javac com/szysky/note/androiddevseek_14/JNITest.java javah com.szysky.note.androiddevseek_14.JNITest
执行之后会在, 操作的路径下生成一个com_szysky_note_androiddevseek_14_JNITest.h头文件, 这个就是第二步生成的东西.
函数名:格式遵循:Java包名类名方法名包名之间的.分割全部替换成分割.
参数: jstring是代表String类型参数. 具体的类型关系后面会说明.
JNIEnv *: 表示一个指向JNI环境的指针, 可以通过它来访问JNI提供的方法.
jobject: 表示java对象中的this.
JNIEXPORT和JNICALL: 这是JNI种所定义的宏, 可以在jni.h这个头文件查到
#ifdef __cplusplus
extern "C" {
#endif而这个宏定义是必须的, 作用是指定extern”C”内部的函数采用C语言的命名风格来编译. 如果设定那么当JNI采用C++来实现时, 由于C/C++编译过程对函数的命名风格不同, 这将导致JNI在链接时无法根据函数名找到具体的函数, 那么JNI调用肯定会失效.
用C/C++实现natvie方法
JNI方法是指的Java中声明的native方法, 这里可以选择c++和c来实现. 过程都是类似的. 只有少量的区别, 这里两种都实现一下.
在工程的主目录创建一个子目录, 名称任意, 然后将之前通过javah命令生成的.h头文件复制到创建的目录下, 接着创建test.cpp和test.c两个文件,实现如下:
test.app
#include "com_szysky_note_androiddevseek_14_JNITest.h"
#include <stdio.h>
JNIEXPORT jstring JNICALL Java_com_szysky_note_androiddevseek_114_JNITest_get(JNIEnv *env, jobject thiz){
printf("执行在c++文件中 get方法\n");
return env->NewStringUTF("Hello from JNI .");
}
JNIEXPORT void JNICALL Java_com_szysky_note_androiddevseek_114_JNITest_get(JNIEnv *env, jobject thiz, jstring string){
printf("执行在c++文件中 set方法\n");
char* str = (char*) env->GetStringUTFChars(string, NULL);
printf("\n, str");
env->ReleaseStringUTFChars(string, str);
}test.c
#include "com_szysky_note_androiddevseek_14_JNITest.h"
#include <stdio.h>
JNIEXPORT jstring JNICALL Java_com_szysky_note_androiddevseek_114_JNITest_get(JNIEnv *env, jobject thiz){
printf("执行在c文件中 get方法\n");
return (*env)->NewStringUTF("Hello from JNI .");
JNIEXPORT void JNICALL Java_com_szysky_note_androiddevseek_114_JNITest_get(JNIEnv *env, jobject thiz, jstring string){
printf("执行在c文件中 set方法\n");
char* str = (char*) (*env)->GetStringUTFChars(env, string, NULL);
printf("%s\n, str");
(*env)->ReleaseStringUTFChars(env, string, str);
}}其实C\C++在实现上很相似, 但是对于env的操作方式有所不同.
C++: env->ReleaseStringUTFChars(string, str); C: (*env)->ReleaseStringUTFChars(env, string, str);
编译so库并在java中调用
so库的编译这里采用gcc. 命令cd到放置刚才生成c/c++的目录下.
使用如下命令:
gcc -shared -I /user/lib/jvm/java-7-openjdk-amd64/include -fPIC test.cpp -o libjni-test.so gcc -shared -I /user/lib/jvm/java-7-openjdk-amd64/include -fPIC test.c -o libjni-test.so
/user/lib/jvm/java-7-openjdk-amd64是本地jdk的安装路径,libjni-test.so是生产的so库的名字。Java中通过:System.loadLibrary("jni-test")加载,其中lib和.so不需要指出。
切换到主目录,通过Java指令执行Java程序:java -Djava.library.path=jni com.ryg.JniTest。其中-Djava.library.path=jni指明了so库的路径。
14.2 NDK的开发流程
下载并配置NDK
下载好NDK开发包,并且配置好NDK的全局变量。
创建一个Android项目,并声明所需的native方法
public static native String getStringFromC();
实现Android项目中所声明的native方法
生成C/C++的头文件
i. 打开控制台,用cd命令切换到当前项目当前目录
ii. 使用javah命令生成头文件javah -classpath bin\classes;C:\MOX\AndroidSDK\platforms\android-23\android.jar -d jni cn.hudp.hellondk.MainActivity
说明:bin\classes 为项目的class文件的相对路径 ; C:\MOX\AndroidSDK\platforms\android-23\android.jar 为android.jar的全路径,因为我们的的Activity使用到了Android SDK,所以生成头文件时需要他; -d jni就是生成的头文件输出到项目的jni文件夹下; 最后跟的cn.hudp.hellondk.MainActivity是native方法所在的类的包名和类名。
编写修改对应的android.mk文件( mk文件是NDK开发所用到的配置文件)
# Copyright (C) 2009 The Android Open Source Project # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # L OCAL_PATH := $(call my-dir) include $(CLEAR_VARS) ## 对应Java部分 System.loadLibrary(String libName) 的libname LOCAL_MODULE := hello ## 对应c/c++的实现文件名 LOCAL_SRC_FILES := hello.c include $(BUILD_SHARED_LIBRARY)
编写Application.mk,来指定需生成的平台对应的动态库,这里是全平台支持,也可以特殊指定。目前常见的架构平台有armeabi、x86和mips。其中移动设备主要是armeabi,因此大部分apk中只包含armeabi的so库。
APP_ABI := all
切换到jni目录的父目录,然后通过ndk-build命令编译产生so库
ndk-build 命令会默认指定jni目录为本地源码的目录
将编译好的so库放到Android项目中的 app/src/main/jniLbis 目录下,或者通过如下app的gradle设置新的存放so库的目录:
android{
……
sourceSets.main{
jniLibs.srcDir 'src/main/jni_libs'
}
}还可以通过 defaultConfig 区域添加NDK选项
android{
……
defaultConfig{
……
ndk{
moduleName "jni-test"
}
}
}还可以在 productFlavors 设置动态打包不同平台CPU对应的so库进apk( 缩小APK体积)
gradle
android{
……
productFlavors{
arm{
ndk{
adiFilter "armeabi"
}
}
x86{
ndk{
adiFilter "x86"
}
}
}
} `在Android中调用
public class MainActivity extends Activity {
public static native String getStringFromC();
static{//在静态代码块中调用所需要的so文件,参数对应.so文件所对应的LOCAL_MODULE;
System.loadLibrary("hello");
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//在需要的地方调用native方法
Toast.makeText(getApplicationContext(), get(), Toast.LENGTH_LONG).show();
}
}14.3 JNI的数据类型和类型签名
JNI的数据类型包含两种: 基本类型和引用类型.
基本类型主要有jboolean, jchar, jint等, 和Java中的数据类型对应如下:
| JNI类型 | Java类型 | 描述 |
|---|---|---|
| jboolean | boolean | 无符号8位整型 |
| jbyte | byte | 无符号8位整型 |
| jchar | char | 无符号16位整型 |
| jshort | short | 有符号16位整型 |
| jint | int | 32位整型 |
| jlong | long | 64位整型 |
| jfloat | float | 32位浮点型 |
| jdouble | double | 64位浮点型 |
| void | void | 无类型 |
JNI中的引用类型主要有类, 对象和数组. 他们和Java中的引用类型的对应关系如下:
| JNI类型 | Java类型 | 描述 |
|---|---|---|
| jobject | Object | Object类型 |
| jclass | Class | Class类型 |
| jstring | String | String类型 |
| jobjeckArray | Object[] | 对象数组 |
| jbooleanArray | boolean[] | boolean数组 |
| jbyteArray | byte[] | byte数组 |
| jcharArray | char[] | char数组 |
| jshortArray | short[] | short数组 |
| jintArray | int[] | int数组 |
| jlongArray | long[] | long数组 |
| jfloatArray | float[] | float数组 |
| jdoubleArray | double[] | double数组 |
| jthrowable | Throwable | Throwable |
JNI的类型签名标识了一个特定的Java类型, 这个类型既可以是类也可以是方法, 也可以是数据类型.
类的签名比较简单, 它采用L+包名+类型+;的形式, 只需要将其中的.替换为/即可. 例如java.lang.String, 它的签名为Ljava/lang/String;, 末尾的;也是一部分.
基本数据类型的签名采用一系列大写字母来表示, 如下:
| Java类型 | 签名 | Java类型 | 签名 | Java类型 | 签名 |
|---|---|---|---|---|---|
| boolean | Z | byte | B | char | C |
| short | S | int | I | long | J |
| float | F | double | D | void | V |
基本数据类型的签名基本都是单词的首字母, 但是boolean除外因为B已经被byte占用, 而long的表示也被Java类签名占用. 所以不同.
而对象和数组, 对象的签名就是对象所属的类签名, 数组的签名[+类型签名例如byte数组. 首先类型为byte,所以签名为B然后因为是数组那么最终形成的签名就是[B.例如如下各种对应:
char[] [C float[] [F double[] [D long[] [J String[] [Ljava/lang/String; Object[] [Ljava/lang/Object;
如果是多维数组那么就根据数组的维度多少来决定[的多少, 例如int[][]那么就是[[I
方法的签名为(参数类型签名)+返回值类型签名。
方法boolean fun(int a, double b, int[] c). 参数类型的签名是连在一起, 那么按照方法的签名规则就是(ID[I)Z
方法:void fun(int a, String s, int[] c), 那么签名就是(ILjava/lang/String;[I)V
方法:int fun(), 对应签名()I
方法:int fun(float f), 对应签名(F)I
14.4 JNI调用Java方法的流程
JNI调用java方法的流程是先通过类名找到类, 然后在根据方法名找到方法的id, 最后就可以调用这个方法了. 如果是调用Java的非静态方法, 那么需要构造出类的对象后才可以调用它。
演示一下调用静态的方法
首先在java中声明要被调用的静态方法. 这里触发的时机是一个按钮的点击,自行添加
static{ System.loadLibrary("jni-test"); } /** * 定义一个静态方法 , 提供给JNI调用 */ public static void methodCalledByJni(String fromJni){ Log.e("susu", "我是从JNI被调用的消息, JNI返回的值是:"+fromJni ); } // 定义调用本地方法, 好让本地方法回调java中的方法 public native void callJNIConvertJavaMethod(); @Override public void onClick(View view) { switch (view.getId()){ case R.id.btn_jni2java: // 调用JNI的方法 callJNIConvertJavaMethod(); break; } }在JNI的test.cpp中添加一个c的函数用来处理调用java的逻辑, 并提供一个方法供java代码调起来触发. 一共两个方法。
// 定义调用java中的方法的函数 void callJavaMethod( JNIEnv *env, jobject thiz){ // 先找到要调用的类 jclass clazz = env -> FindClass("com/szysky/note/androiddevseek_14/MainActivity"); if (clazz == NULL){ printf("找不到要调用方法的所属类"); return; } // 获取java方法id // 参数二是调用的方法名, 参数三是方法的签名 jmethodID id = env -> GetStaticMethodID(clazz, "methodCalledByJni", "(Ljava/lang/String;)V"); if (id == NULL){ printf("找不到要调用方法"); return; } jstring msg = env->NewStringUTF("我是在c中生成的字符串"); // 开始调用java中的静态方法 env -> CallStaticVoidMethod(clazz, id, msg); } void Java_com_szysky_note_androiddevseek_114_MainActivity_callJNIConvertJavaMethod(JNIEnv *env, jobject thiz){ printf("调用c代码成功, 马上回调java中的代码"); callJavaMethod(env, thiz); }稍微说明一下, 程序首先根据类名com/szysky/note/androiddevseek_14/MainActivity找到类, 然后在根据方法名methodCalledByJni找到方法, 并传入方法对应签名(Ljava/lang/String;), 最后通过JNIEnv对象的CallStaticVoidMethod()方法来完成最终调用。
最后只要在Java_com_szysky_note_androiddevseek_114_MainActivity_callJNIConvertJavaMethod方法中调用callJavaMethod方法即可.
流程就是–> 按钮触发了点击的onClikc –> 然后Java中会调用JNI的callJNIConvertJavaMethod() –> JNI的callJNIConvertJavaMethod()方法内部会调用具体实现回调Java中的方法callJavaMethod() –> 方法最终通过CallStaticVoidMethod()调用了Java中的methodCalledByJni()来接收一个参数并打印一个log。
生成so库的文件保存在git中的app/src/main/backup目录下一个两个版本代码, 第一个就是第二小节中的NDK开发代码, 第二个就是第四小节的代码就是目前的. 而so库是最新的, 包含了所有的JNI代码生成的库文件。
JNI调用Java的过程和Java中方法的定义有很大关联, 针对不同类型的java方法, JNIEnv提供了不同的接口去调用, 更为细节的部分要去开发中或者去网站去了解更多.
15 Android性能优化
Android设备作为一种移动设备,不管是内存还是CPU的性能都受到了一定的限制,也意味着Android程序不可能无限制的使用内存和CPU资源,过多的使用内存容易导致OOM,过多的使用CPU资源容易导致手机变得卡顿甚至无响应(ANR)。这也对开发人员提出了更高的要求。 本章主要介绍一些有效的性能优化方法。主要包括布局优化、绘制优化、内存泄漏优化、响应速度优化、ListView优化、Bitmap优化、线程优化等;同时还介绍了ANR日志的分析方法。
Google官方的Android性能优化典范专题短视频课程是学习Android性能优化极佳的课程,目前已更新到第五季; youku地址
15.1 Android的性能优化方法
15.1.1 布局优化
布局优化的思想就是尽量减少布局文件的层级,这样绘制界面时工作量就少了,那么程序的性能自然就高了。
删除无用的控件和层级
有选择的使用性能较低的ViewGroup,如果布局中既可以使用Linearlayout也可以使用RelativeLayout,那就是用LinearLayout,因为RelativeLayout功能比较复杂,它的布局过程需要花费更多的CPU时间。
有时候通过LinearLayou无法实现产品效果,需要通过嵌套来完成,这种情况还是推荐使用RelativeLayout,因为ViewGroup的嵌套相当于增加了布局的层级,同样降低程序性能。采用标签、标签和ViewStub
include标签
标签用于布局重用,可以将一个指定的布局文件加载到当前布局文件中。只支持android:layout开头的属性,当然android:id这个属性是个特例;如果指定了android:layout这种属性,那么要求android:layoutwidth和android:layout_height必须存在,否则android:layout属性无法生效。如果指定了id属性,同时被包含的布局文件的根元素也指定了id属性,会以指定的这个id属性为准。merge标签
标签一般和标签一起使用从而减少布局的层级。如果当前布局是一个竖直方向的LinearLayout,这个时候被包含的布局文件也采用竖直的LinearLayout,那么显然被包含的布局文件中的这个LinearLayout是多余的,通过标签就可以去掉多余的那一层LinearLayout。ViewStub
ViewStub意义在于按需加载所需的布局文件,因为实际开发中,有很多布局文件在正常情况下是不会现实的,比如网络异常的界面,这个时候就没必要在整个界面初始化的时候将其加载进来,在需要使用的时候再加载会更好。在需要加载ViewStub布局时:((ViewStub)findViewById(R.id.stub_import)).setVisibility(View.VISIBLE); //或者 View importPanel = ((ViewStub)findViewById(R.id.stub_import)).inflate();
当ViewStub通过setVisibility或者inflate方法加载后,ViewStub就会被它内部的布局替换掉,ViewStub也就不再是整个布局结构的一部分了。
15.1.2 绘制优化
View的onDraw方法要避免执行大量的操作;
onDraw中不要创建大量的局部对象,因为onDraw方法会被频繁调用,这样就会在一瞬间产生大量的临时对象,不仅会占用过多内存还会导致系统频繁GC,降低程序执行效率。
onDraw也不要做耗时的任务,也不能执行成千上万的循环操作,尽管每次循环都很轻量级,但大量循环依然十分抢占CPU的时间片,这会造成View的绘制过程不流畅。根据Google官方给出的标准,View绘制保持在60fps是最佳的,这也就要求每帧的绘制时间不超过16ms(1000/60);所以要尽量降低onDraw方法的复杂度。
15.1.3 内存泄露优化
内存泄露是最容易犯的错误之一,内存泄露优化主要分两个方面;一方面是开发过程中避免写出有内存泄露的代码,另一方面是通过一些分析工具如LeakCanary或MAT来找出潜在的内存泄露继而解决。
静态变量导致的内存泄露
比如Activity内,一静态Conext引用了当前Activity,所以当前Activity无法释放。或者一静态变量,内部持有了当前Activity,Activity在需要释放的时候依然无法释放。单例模式导致的内存泄露
比如单例模式持有了Activity,而且也没用解注册的操作。因为单例模式的生命周期和Application保存一致,生命周期比Activity要长,这样一来就导致Activity对象无法及时被释放。属性动画导致的内存泄露
属性动画中有一类无限循环的动画,如果在Activity播放了此类动画并且没有在onDestroy中去停止动画,那么动画会一直播放下去,并且这个时候Activity的View会被动画持有,而View又持有了Activity,最终导致Activity无法释放。解决办法是在Activity的onDrstroy中调用animator.cancel()来停止动画。
15.1.4 响应速度优化和ANR日志分析
响应速度优化的核心思想就是避免在主线程中去做耗时操作,将耗时操作放在其他线程当中去执行。Activity如果5秒无法响应屏幕触摸事件或者键盘输入事件就会触发ANR,而BroadcastReceiver如果10秒还未执行完操作也会出现ANR。
当一个进程发生ANR以后系统会在/data/anr的目录下创建一个文件traces.txt,通过分析该文件就能定位出ANR的原因。
通过一个例子来了解如何去分析文件, 首先在onCreate()添加如下代码, 让主线程等待一个锁,然后点击返回5秒后会出现ANR。
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 以下代码是为了模拟一个ANR的场景来分析日志
new Thread(new Runnable() {
@Override
public void run() {
testANR();
}
}).start();
SystemClock.sleep(10);
initView();
}
/**
* 以下两个方法用来模拟出一个稍微不好发现的ANR
*/
private synchronized void testANR(){
SystemClock.sleep(3000 * 1000);
}
private synchronized void initView(){}这样会出现ANR, 然后导出/data/anr/straces.txt文件. 因为内容比较多只贴出关键部分
DALVIK THREADS (15): "main" prio=5 tid=1 Blocked | group="main" sCount=1 dsCount=0 obj=0x73db0970 self=0xf4306800 | sysTid=19949 nice=0 cgrp=apps sched=0/0 handle=0xf778d160 | state=S schedstat=( 151056979 25055334 199 ) utm=5 stm=9 core=1 HZ=100 | stack=0xff5b2000-0xff5b4000 stackSize=8MB | held mutexes= at com.szysky.note.androiddevseek_15.MainActivity.initView(MainActivity.java:0) - waiting to lock <0x2fbcb3de> (a com.szysky.note.androiddevseek_15.MainActivity) - held by thread 15 at com.szysky.note.androiddevseek_15.MainActivity.onCreate(MainActivity.java:42)
这段可以看出最后指明了ANR发生的位置在ManiActivity的42行. 并且通过上面看出initView方法正在等待一个锁<0x2fbcb3de>锁的类型是一个MainActivity对象. 并且这个锁已经被线程id为15(tid=15)的线程持有了. 接下来找一下线程15
"Thread-404" prio=5 tid=15 Sleeping | group="main" sCount=1 dsCount=0 obj=0x12c00f80 self=0xeb95bc00 | sysTid=19985 nice=0 cgrp=apps sched=0/0 handle=0xef34be80 | state=S schedstat=( 391248 0 1 ) utm=0 stm=0 core=2 HZ=100 | stack=0xe2bfe000-0xe2c00000 stackSize=1036KB | held mutexes= at java.lang.Thread.sleep!(Native method) - sleeping on <0x2e3896a7> (a java.lang.Object) at java.lang.Thread.sleep(Thread.java:1031) - locked <0x2e3896a7> (a java.lang.Object) at java.lang.Thread.sleep(Thread.java:985) at android.os.SystemClock.sleep(SystemClock.java:120) at com.szysky.note.androiddevseek_15.MainActivity.testANR(MainActivity.java:50) - locked <0x2fbcb3de> (a com.szysky.note.androiddevseek_15.MainActivity)
tid = 15 就是相关信息如上, 首行已经标出线程的状态为Sleeping, 原因在50行, 就是SystemClock.sleep(3000 * 1000);这句话. 也就是testANR(). 而最后一行也表明了持有的locked<0x2fbcb3de>就是主线程在等待的那个锁对象.
15.1.5 ListView优化和Bitmap优化
ListView/GridView优化:
采用ViewHolder避免在getView中执行耗时操作
其次通过列表的滑动状态来控制任务的执行频率,比如快速滑动时不是和开启大量异步任务
最后可以尝试开启硬件加速使得ListView的滑动更加流畅。
Bitmap优化:主要是想是根据需要对图片进行采样显示,详细请参考12章。
15.1.6 线程优化
主要思想就是采用线程池, 避免程序中存在大量的Thread. 线程池可以重用内部的线程, 避免了线程创建和销毁的性能开销. 同时线程池还能有效的控制线程的最大并发数, 避免了大量线程因互相抢占系统资源从而导致阻塞现象的发生.详细参考第11章的内容。
15.1.7 一些性能优化的小建议
避免创建过多的对象,尤其在循环、onDraw这类方法中,谨慎创建对象;
不要过多的使用枚举,枚举占用的内存空间比整形大。Android 中如何使用annotion替代Enum
常量使用static final来修饰;
使用一些Android特有的数据结构,比如 SparseArray 和 Pair 等,他们都具有更好的性能;
适当的使用软引用和弱引用;
采用内存缓存和磁盘缓存;
尽量采用静态内部类,这样可以避免非静态内部类隐式持有外部类所导致的内存泄露问题。
15.2 内存泄漏分析工具MAT
MAT全程Eclipse Memory Analyzer, 是一个内存泄漏分析工具. 下载后解压即可. 下载地址http://www.eclipse.org/mat/downloads.php. 这里仅简单说一下. 这个我没有手动去实践, 就当个记录, 因为现在Android Studio可以直接分析hprof文件.
可以手动写一个会造成内存泄漏的代码, 然后打开DDMS, 然后选中要分析的进程, 然后单击Dump HPROF file这个按钮. 等一小段会生成一个文件. 这个文件不能被MAT直接识别. 需要使用Android SDK中的工具进行格式转换一下.这个工具在platform-conv文件夹下
hprof-conv 要转换的文件名 输出的文件名文件名的签名有包名.
然后打开MAT通过菜单打开转换后的这个文件. 这里常用的就有两个
Histogram: 可以直观的看出内存中不同类型的buffer的数量和占用内存大小
Dominator Tree: 把内存中的对象按照从大到小的顺序进行排序, 并且可以分析对象之间的引用关系, 内存泄漏分析就是通过这个完成的.
分析内存泄漏的时候需要分析Dominator Tree里面的内存信息, 一般会不直接显示出来, 可以按照从大到小的顺序去排查一遍. 如果发生了了泄漏, 那么在泄漏对象处右键单击Path To GC Roots->exclude wake/soft references. 可以看到最终是什么对象导致的无法释放. 刚才的操作之所以排除软引用和弱引用是因为,大部分情况下这两种类型都可以被gc回收掉,所以基本也就不会造成内存泄漏.
同样这里也可以使用搜索功能, 假如我们手动模拟了内存泄漏, 泄漏的对象就是Activity那么我们back退出重进循环几次, 会发现其实很多个Activit对象.
15.3 提高程序的可维护性
提高可读性
命名规范
代码之间排版需留出合理的空白来区分不同的代码块
针对非常关键的代码添加注释。
代码的层级性
不要把一段业务逻辑放在一个方法或者一个类中全部实现,要把它分成几个子逻辑,然后每个子逻辑做自己的事情,这样即显得代码层级分明,这样利于提高程序的可扩展性。
程序的扩展性
由于很多时候在开发过程中无法保证已经做好的需求不在后面的版本发生更改, 因此在写程序的时候要时刻考虑到扩展的问题, 考虑如果这个逻辑以后发生了改变那么哪些需要修改, 以及怎样在以后修改的时候降低工作量, 而面向扩展编程可以让程序具有很好的扩展性.
恰当的使用设计模式可以提高代码的可维护性和可扩展性,Android程序容易遇到性能瓶颈,要控制设计的度,不能太牵强,避免过度设计。作者推荐查看《 大话设计模式》 和《 Android源码设计模式解析和实战》 这两本书来学习设计模式。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



