
第一篇我们做了一个简单的页面广度优先来抓取url,很显然缺点有很多,第一:数据结构都是基于内存的,第二:单线程抓取
速度太慢,在实际开发中肯定不会这么做的,起码得要有序列化到硬盘的机制,对于整个爬虫架构来说,构建好爬虫队列相当重要。
先上一幅我自己构思的架构图,不是很完善,算是一个雏形吧。

一:TODO队列和Visited集合
在众多的nosql数据库中,mongodb还是很不错的,这里也就选择它了,做集群,做分片轻而易举。
二:中央处理器
群架,斗殴都是有带头的,那中央处理器就可以干这样的事情,它的任务很简单,
第一: 启动时,根据我们定义好的规则将种子页面分发到各个执行服务器。
第二: 定时轮询”TODO——MongoDB“,将读取的新Url根据规则分发到对应的执行服务器中。
三:分发服务器
中央处理器将url分发到了执行服务器的内存中,分发服务器可以开启10个线程依次读取队列来获取url,然后解析url,
第一:如果url是外链,直接剔除。
第二:如果url不是本机负责抓取的,就放到”TODO——MongoDB“中。
第三:如果是本机负责的,将新提取的url放入本机内存队列中。
四:代码实现
首先下载mongodb http://www.mongodb.org/downloads,简单起见就在一个database里面建两个collection。迫不及
待了,我要爬一个美女网站,http://www.800meinv.com ,申明一下,并非推广网站,看下”中央处理器“的实现。

1 namespace CrawlerCPU 2 { 3 /* 根据规格,一个服务爬取3个导航页(由 中央处理器 统一管理) 4 * 第一个服务:日韩时装,港台时装 5 * 第二个服务:,欧美时装,明星穿衣,显瘦搭配 6 * 第三个服务:少女搭配,职场搭配,裙装搭配 7 */ 8 public class Program 9 {10 static Dictionary<string, string> dicMapping = new Dictionary<string, string>();11 12 static void Main(string[] args)13 {14 //初始Url的分发15 foreach (var key in ConfigurationManager.AppSettings)16 {17 var factory = new ChannelFactory<ICrawlerService>(new NetTcpBinding(), new EndpointAddress(key.ToString()))18 .CreateChannel();19 20 var urls = ConfigurationManager.AppSettings[key.ToString()]21 .Split(new char[] { ';' }, StringSplitOptions.RemoveEmptyEntries)22 .ToList();23 24 factory.AddRange(urls);25 26 //将网址和“WCF分发地址“建立Mapping映射27 foreach (var item in urls)28 dicMapping.Add(item, key.ToString());29 }30 31 Console.WriteLine("爬虫 中央处理器开启,正在监视TODO列表!");32 33 //开启定时监视MongoDB34 Timer timer = new Timer();35 36 timer.Interval = 1000 * 10; //10s轮询一次37 timer.Elapsed += new ElapsedEventHandler(timer_Elapsed);38 timer.Start();39 40 Console.Read();41 }42 43 static void timer_Elapsed(object sender, ElapsedEventArgs e)44 {45 //获取mongodb里面的数据46 MongodbHelper<Message> mongodb = new MongodbHelper<Message>("todo");47 48 //根据url的类型分发到相应的服务器中去处理49 var urls = mongodb.List(100);50 51 if (urls == null || urls.Count == 0)52 return;53 54 foreach (var item in dicMapping.Keys)55 {56 foreach (var url in urls)57 {58 //寻找正确的 wcf 分发地址59 if (url.Url.StartsWith(item))60 {61 var factory = new ChannelFactory<ICrawlerService>(new NetTcpBinding(),62 new EndpointAddress(dicMapping[item]))63 .CreateChannel();64 65 //向正确的地方分发地址66 factory.Add(url.Url);67 68 break;69 }70 }71 }72 73 //删除mongodb中的TODO表中指定数据74 mongodb.Remove(urls);75 }76 }77 }
接下来,我们开启WCF服务,当然我们可以做10份,20份的copy,核心代码如下:
1 /// <summary> 2 /// 开始执行任务 3 /// </summary> 4 public static void Start() 5 { 6 while (true) 7 { 8 //监视工作线程,如果某个线程已经跑完数据,则重新分配任务给该线程 9 for (int j = 0; j < 10; j++)10 {11 if (tasks[j] == null || tasks[j].IsCompleted || tasks[j].IsCanceled || tasks[j].IsFaulted)12 {13 //如果队列还有数据14 if (todoQueue.Count > 0)15 {16 string currentUrl = string.Empty;17 18 todoQueue.TryDequeue(out currentUrl);19 20 Console.WriteLine("当前队列的个数为:{0}", todoQueue.Count);21 22 tasks[j] = Task.Factory.StartNew((obj) =>23 {24 DownLoad(obj.ToString());25 26 }, currentUrl);27 }28 }29 }30 }31 }
然后我们把”分发服务器“和”中央处理器“开启:
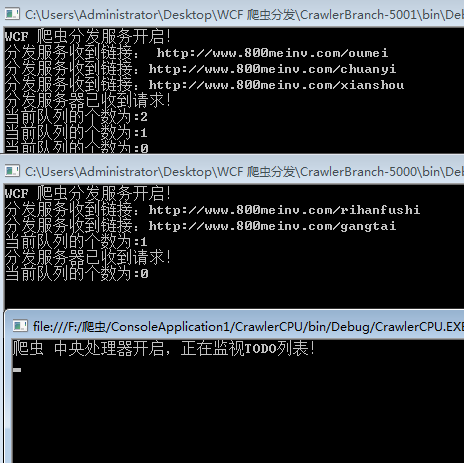
好了,稍等会,我们就会看到,数据已经哗啦啦的往mongodb里面跑了。

五:不足点
有的时候会出现某些机器非常free,而某些机器非常busy,这时就要实现双工通讯了,当执行服务器的内存队列到达
一个量级的时候就应该通知中央处理器,要么减缓对该执行服务器的任务分发,要么将任务分给其他的执行服务器。
最后是工程代码,有什么好的建议可以提出来,大家可以一起研究研究:ConsoleApplication1.rar
共同学习,写下你的评论
评论加载中...
作者其他优质文章



