
探索传统 JavaScript 基准测试
一些分析显示,在第一个循环中传递给 e.m_tree.Query 的无辜的内部函数花费了大量的时间:
function(t) { if (t == m) return true; if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O; var x = e.m_pairBuffer[e.m_pairCount];
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
++e.m_pairCount; return true}更准确地说,时间并不是开销在这个函数本身,而是由此触发的操作和内置库函数。结果,我们花费了基准调用的总体执行时间的 4-7% 在 Compare` 运行时函数上,它实现了抽象关系比较的一般情况。
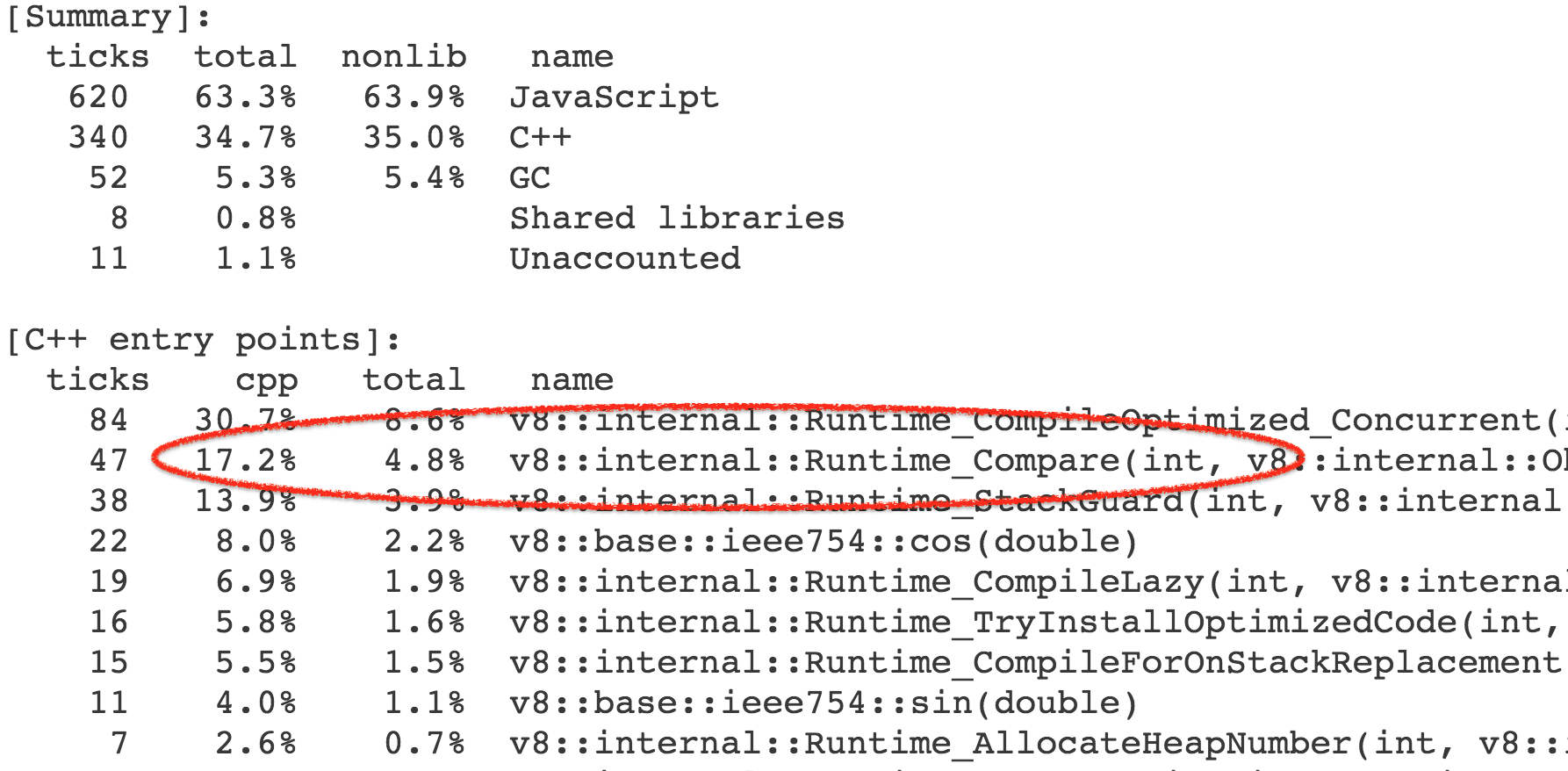
几乎所有对运行时函数的调用都来自 CompareICStub,它用于内部函数中的两个关系比较:
x.proxyA = t < m ? t : m; x.proxyB = t >= m ? t : m;
所以这两行无辜的代码要负起 99% 的时间开销的责任!这怎么来的?好吧,与 JavaScript 中的许多东西一样,抽象关系比较 的直观用法不一定是正确的。在这个函数中,t 和 m 都是 L 的实例,它是这个应用的一个中心类,但不会覆盖 Symbol.toPrimitive、“toString”、“valueOf” 或 Symbol.toStringTag 属性,它们与抽象关系比较相关。所以如果你写 t < m 会发生什么呢?
调用 ToPrimitive(
t,hint Number)。运行 OrdinaryToPrimitive(
t,"number"),因为这里没有Symbol.toPrimitive。执行
t.valueOf(),这会获得t自身的值,因为它调用了默认的 Object.prototype.valueOf。接着执行
t.toString(),这会生成"[object Object]",因为调用了默认的 Object.prototype.toString,并且没有找到L的 Symbol.toStringTag。调用 ToPrimitive(
m,hint Number)。运行 OrdinaryToPrimitive(
m,"number"),因为这里没有Symbol.toPrimitive。执行
m.valueOf(),这会获得m自身的值,因为它调用了默认的 Object.prototype.valueOf。接着执行
m.toString(),这会生成"[object Object]",因为调用了默认的 Object.prototype.toString,并且没有找到L的 Symbol.toStringTag。执行比较
"[object Object]" < "[object Object]",结果是false。
至于 t >= m 亦复如是,它总会输出 true。所以这里是一个漏洞——使用抽象关系比较这种方法没有意义。而利用它的方法是使编译器常数折叠,即给基准打补丁:
--- octane-box2d.js.ORIG 2016-12-16 07:28:58.442977631 +0100+++ octane-box2d.js 2016-12-16 07:29:05.615028272 +0100@@ -2021,8 +2021,8 @@ if (t == m) return true; if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O; var x = e.m_pairBuffer[e.m_pairCount];- x.proxyA = t < m ? t : m;- x.proxyB = t >= m ? t : m;+ x.proxyA = m;+ x.proxyB = t; ++e.m_pairCount; return true },
因为这样做会跳过比较以达到 13% 的惊人的性能提升,并且所有的属性查找和内置函数的调用都会被它触发。
$ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIGScore (Box2D): 48063$ ~/Projects/v8/out/Release/d8 octane-box2d.jsScore (Box2D): 55359$
那么我们是怎么做呢?事实证明,我们已经有一种用于跟踪比较对象的形状的机制,比较发生于 CompareIC,即所谓的已知接收器映射跟踪(其中的映射是 V8 的对象形状+原型),不过这是有限的抽象和严格相等比较。但是我可以很容易地扩展跟踪,并且收集反馈进行抽象的关系比较:
$ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js[...SNIP...] [CompareIC in ~+557 at octane-box2d.js:2024 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#LT @ 0x1d5a860493a1] [CompareIC in ~+649 at octane-box2d.js:2025 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#GTE @ 0x1d5a860496e1] [...SNIP...] $
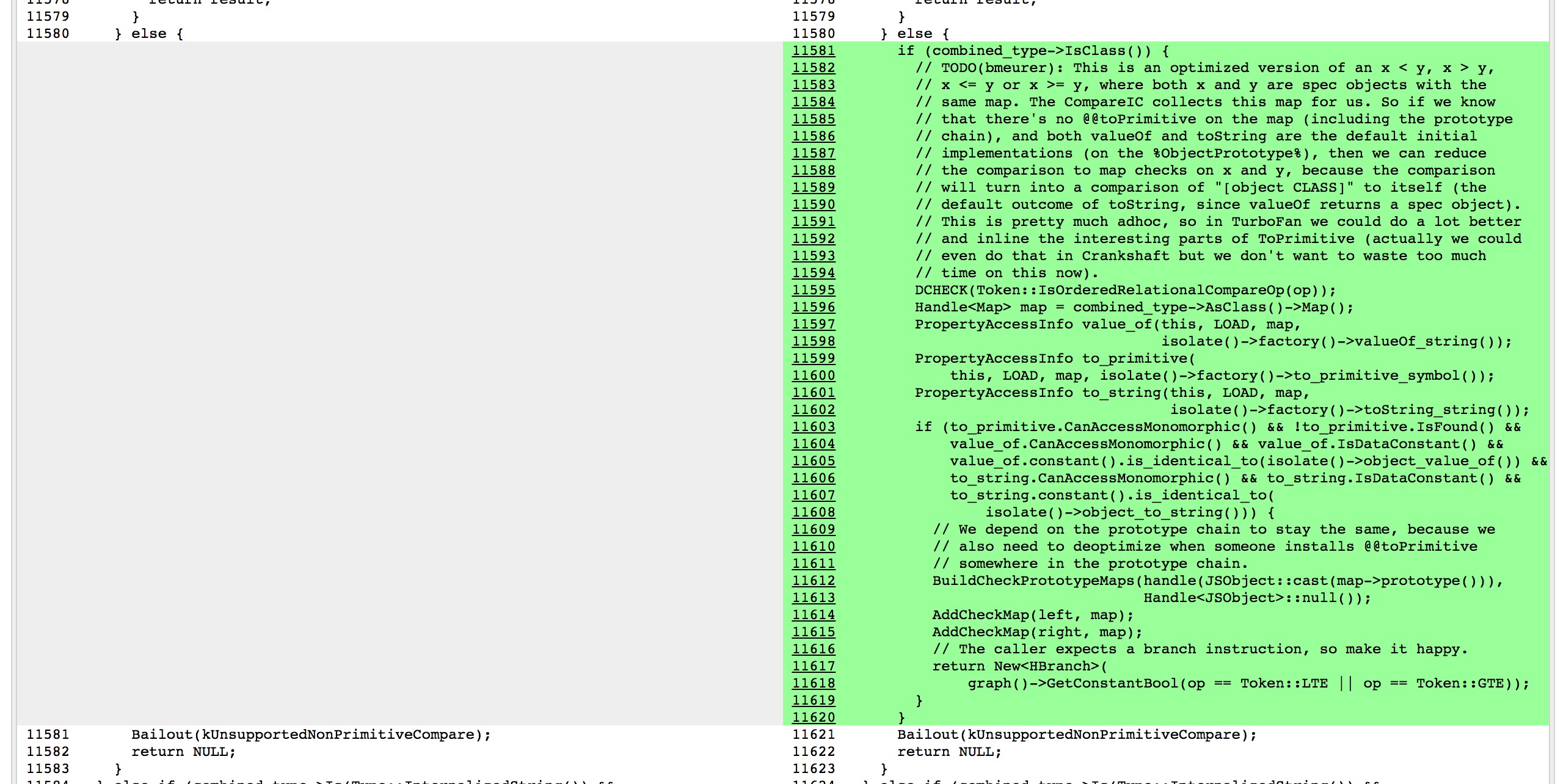
这里基准代码中使用的 CompareIC 告诉我们,对于我们正在查看的函数中的 LT(小于)和 GTE(大于或等于)比较,到目前为止这只能看到 RECEIVERs(接收器,V8 的 JavaScript 对象),并且所有这些接收器具有相同的映射 0x1d5a860493a1,其对应于 L 实例的映射。因此,在优化的代码中,只要我们知道比较的两侧映射的结果都为 0x1d5a860493a1,并且没人混淆 L 的原型链(即 Symbol.toPrimitive、"valueOf" 和 "toString" 这些方法都是默认的,并且没人赋予过 Symbol.toStringTag 的访问权限),我们可以将这些操作分别常量折叠为 false 和 true。剩下的故事都是关于 Crankshaft 的黑魔法,有很多一部分都是由于初始化的时候忘记正确地检查 Symbol.toStringTag 属性:
最后,性能在这个特定的基准上有了质的飞跃:
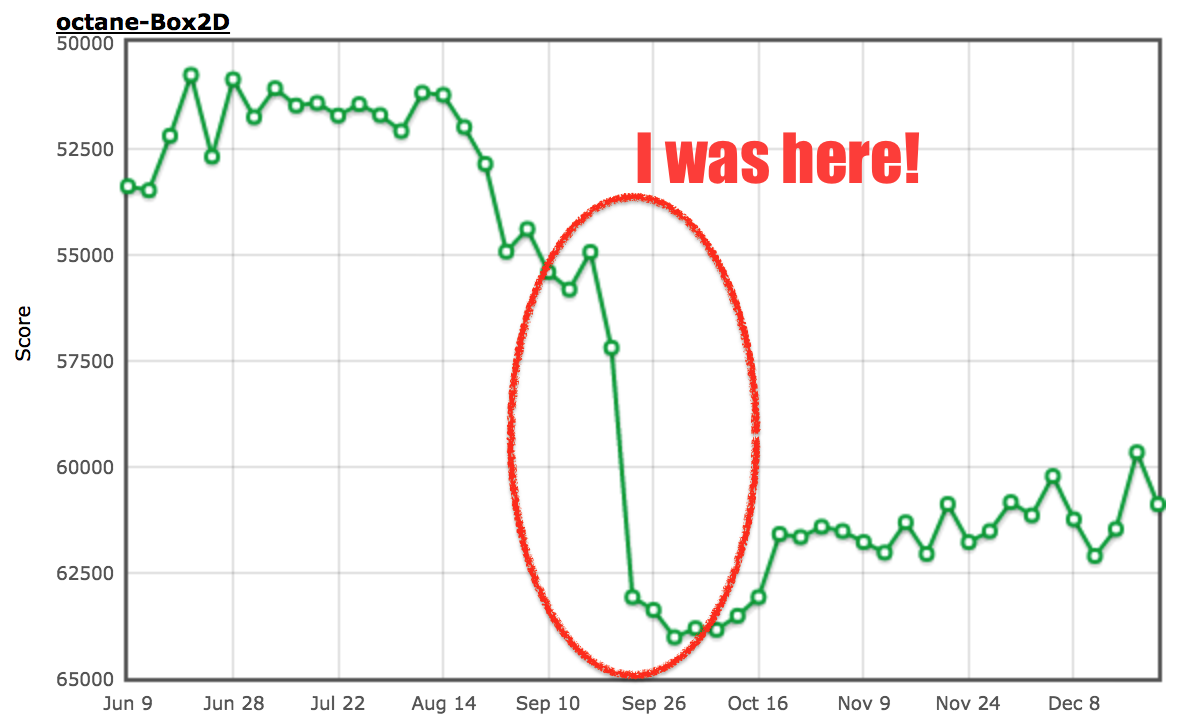
我要声明一下,当时我并不相信这个特定的行为总是指向源代码中的漏洞,所以我甚至期望外部代码经常会遇到这种情况,同时也因为我假设 JavaScript 开发人员不会总是关心这些种类的潜在错误。但是,我大错特错了,在此我马上悔改!我不得不承认,这个特殊的优化纯粹是一个基准测试的东西,并不会有助于任何真实代码(除非代码是为了从这个优化中获益而写,不过以后你可以在代码中直接写入 true 或 false,而不用再总是使用常量关系比较)。你可能想知道我们为什么在打补丁后又马上回滚了一下。这是我们整个团队投入到 ES2015 实施的非常时期,这才是真正的恶魔之舞,我们需要在没有严格的回归测试的情况下将所有新特性(ES2015 就是个怪兽)纳入传统基准。
关于 Box2D 点到为止了,让我们看看 Mandreel 基准。Mandreel 是一个用来将 C/C++ 代码编译成 JavaScript 的编译器,它并没有用上新一代的 Emscripten 编译器所使用,并且已经被弃用(或多或少已经从互联网消失了)大约三年的 JavaScript 子集 asm.js。然而,Octane 仍然有一个通过 Mandreel 编译的子弹物理引擎。MandreelLatency 测试十分有趣,它测试 Mandreel 基准与频繁的时间测量检测点。有一种说法是,由于 Mandreel 强制使用虚拟机编译器,此测试提供了由编译器引入的延迟的指示,并且测量检测点之间的长时间停顿降低了最终得分。这听起来似乎合情合理,确实有一定的意义。然而,像往常一样,供应商找到了在这个基准上作弊的方法。
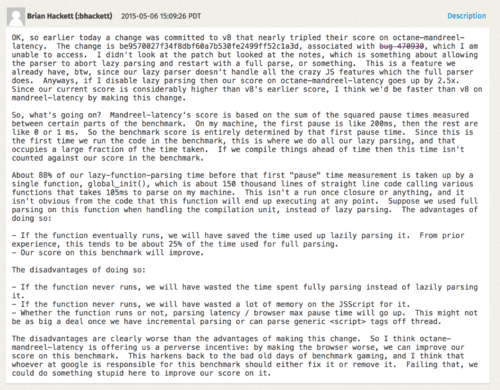
Mandreel 自带一个重型初始化函数 global_init,光是解析这个函数并为其生成基线代码就花费了不可思议的时间。因为引擎通常在脚本中多次解析各种函数,一个所谓的预解析步骤用来发现脚本内的函数。然后作为函数第一次被调用完整的解析步骤以生成基线代码(或者说字节码)。这在 V8 中被称为懒解析。V8 有一些启发式检测函数,当预解析浪费时间的时候可以立刻调用,不过对于 Mandreel 基准的 global_init 函数就不太清楚了,于是我们将经历这个大家伙“预解析+解析+编译”的长时间停顿。所以我们添加了一个额外的启发式函数以避免 global_init 函数的预解析。
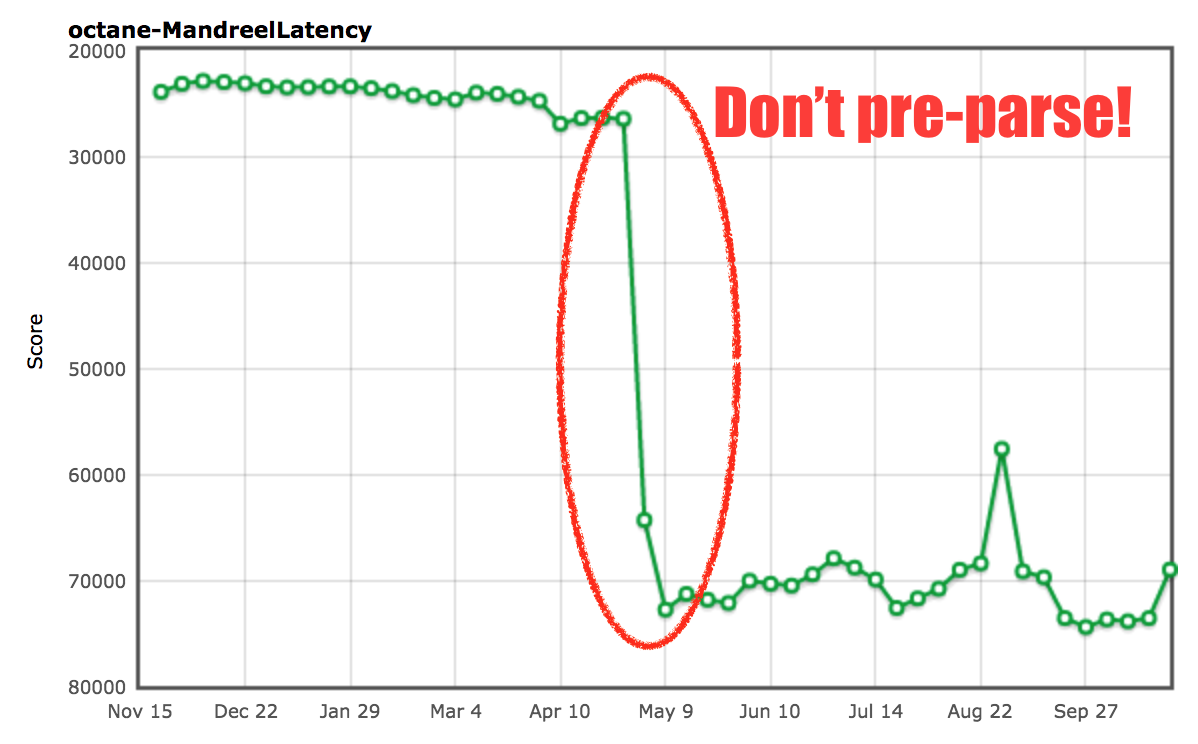
由此可见,在检测 global_init 和避免昂贵的预解析步骤我们几乎提升了 2 倍。我们不太确定这是否会对真实用例产生负面影响,不过保证你在预解析大函数的时候将会受益匪浅(因为它们不会立即执行)。
让我们来看看另一个稍有争议的基准测试:splay.js 测试,一个用于处理伸展树splay tree(二叉查找树的一种)和练习自动内存管理子系统(也被称为垃圾回收器)的数据操作基准。它自带一个延迟测试,这会引导 Splay 代码通过频繁的测量检测点,检测点之间的长时间停顿表明垃圾回收器的延迟很高。此测试测量延迟暂停的频率,将它们分类到桶中,并以较低的分数惩罚频繁的长暂停。这听起来很棒!没有 GC 停顿,没有垃圾。纸上谈兵到此为止。让我们看看这个基准,以下是整个伸展树业务的核心:

这是伸展树结构的核心构造,尽管你可能想看完整的基准,不过这基本上是 SplayLatency 得分的重要来源。怎么回事?实际上,该基准测试是建立巨大的伸展树,尽可能保留所有节点,从而还原它原本的空间。使用像 V8 这样的代数垃圾回收器,如果程序违反了代数假设,会导致极端的时间停顿,从本质上看,将所有东西从新空间撤回到旧空间的开销是非常昂贵的。在旧配置中运行 V8 可以清楚地展示这个问题:
$ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js [20872:0x7f26f24c70d0] 10 ms: Scavenge 2.7 (6.0) -> 2.7 (7.0) MB, 1.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 12 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.7 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 14 ms: Scavenge 3.7 (8.0) -> 3.6 (10.0) MB, 0.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 18 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.5 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 22 ms: Scavenge 5.7 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 28 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.3 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 35 ms: Scavenge 9.6 (17.0) -> 9.6 (28.0) MB, 6.9 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 49 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.2 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 65 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.3 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 93 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 17.6 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 126 ms: Scavenge 33.4 (53.5) -> 33.3 (68.0) MB, 31.5 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 151 ms: Scavenge 47.9 (68.0) -> 47.6 (69.5) MB, 15.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 183 ms: Scavenge 49.2 (69.5) -> 49.2 (84.0) MB, 30.9 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 210 ms: Scavenge 63.5 (84.0) -> 62.4 (85.0) MB, 14.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 241 ms: Scavenge 64.7 (85.0) -> 64.6 (99.0) MB, 28.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 268 ms: Scavenge 78.2 (99.0) -> 77.6 (101.0) MB, 16.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 298 ms: Scavenge 80.4 (101.0) -> 80.3 (114.5) MB, 28.2 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 324 ms: Scavenge 93.5 (114.5) -> 92.9 (117.0) MB, 16.4 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 354 ms: Scavenge 96.2 (117.0) -> 96.0 (130.0) MB, 27.6 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 383 ms: Scavenge 108.8 (130.0) -> 108.2 (133.0) MB, 16.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 413 ms: Scavenge 111.9 (133.0) -> 111.7 (145.5) MB, 27.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 440 ms: Scavenge 124.1 (145.5) -> 123.5 (149.0) MB, 17.4 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 473 ms: Scavenge 127.6 (149.0) -> 127.4 (161.0) MB, 29.5 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 502 ms: Scavenge 139.4 (161.0) -> 138.8 (165.0) MB, 18.7 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 534 ms: Scavenge 143.3 (165.0) -> 143.1 (176.5) MB, 28.5 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 561 ms: Scavenge 154.7 (176.5) -> 154.2 (181.0) MB, 19.0 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 594 ms: Scavenge 158.9 (181.0) -> 158.7 (192.0) MB, 29.2 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 622 ms: Scavenge 170.0 (192.5) -> 169.5 (197.0) MB, 19.5 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 655 ms: Scavenge 174.6 (197.0) -> 174.3 (208.0) MB, 28.7 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 683 ms: Scavenge 185.4 (208.0) -> 184.9 (212.5) MB, 19.4 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 715 ms: Scavenge 190.2 (213.0) -> 190.0 (223.5) MB, 27.7 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 743 ms: Scavenge 200.7 (223.5) -> 200.3 (228.5) MB, 19.7 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 774 ms: Scavenge 205.8 (228.5) -> 205.6 (239.0) MB, 27.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 802 ms: Scavenge 216.1 (239.0) -> 215.7 (244.5) MB, 19.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 833 ms: Scavenge 221.4 (244.5) -> 221.2 (254.5) MB, 26.2 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 861 ms: Scavenge 231.5 (255.0) -> 231.1 (260.5) MB, 19.9 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 892 ms: Scavenge 237.0 (260.5) -> 236.7 (270.5) MB, 26.3 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 920 ms: Scavenge 246.9 (270.5) -> 246.5 (276.0) MB, 20.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 951 ms: Scavenge 252.6 (276.0) -> 252.3 (286.0) MB, 25.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 979 ms: Scavenge 262.3 (286.0) -> 261.9 (292.0) MB, 20.3 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1014 ms: Scavenge 268.2 (292.0) -> 267.9 (301.5) MB, 29.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1046 ms: Scavenge 277.7 (302.0) -> 277.3 (308.0) MB, 22.4 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1077 ms: Scavenge 283.8 (308.0) -> 283.5 (317.5) MB, 25.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1105 ms: Scavenge 293.1 (317.5) -> 292.7 (323.5) MB, 20.7 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1135 ms: Scavenge 299.3 (323.5) -> 299.0 (333.0) MB, 24.9 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1164 ms: Scavenge 308.6 (333.0) -> 308.1 (339.5) MB, 20.9 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1194 ms: Scavenge 314.9 (339.5) -> 314.6 (349.0) MB, 25.0 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1222 ms: Scavenge 324.0 (349.0) -> 323.6 (355.5) MB, 21.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1253 ms: Scavenge 330.4 (355.5) -> 330.1 (364.5) MB, 25.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1282 ms: Scavenge 339.4 (364.5) -> 339.0 (371.0) MB, 22.2 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1315 ms: Scavenge 346.0 (371.0) -> 345.6 (380.0) MB, 25.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1413 ms: Mark-sweep 349.9 (380.0) -> 54.2 (305.0) MB, 5.8 / 0.0 ms (+ 87.5 ms in 73 steps since start of marking, biggest step 8.2 ms, walltime since start of marking 131 ms) finalize incremental marking via stack guard GC in old space requested [20872:0x7f26f24c70d0] 1457 ms: Scavenge 65.8 (305.0) -> 65.1 (305.0) MB, 31.0 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1489 ms: Scavenge 69.9 (305.0) -> 69.7 (305.0) MB, 27.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1523 ms: Scavenge 80.9 (305.0) -> 80.4 (305.0) MB, 22.9 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1553 ms: Scavenge 85.5 (305.0) -> 85.3 (305.0) MB, 24.2 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1581 ms: Scavenge 96.3 (305.0) -> 95.7 (305.0) MB, 18.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1616 ms: Scavenge 101.1 (305.0) -> 100.9 (305.0) MB, 29.2 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1648 ms: Scavenge 111.6 (305.0) -> 111.1 (305.0) MB, 22.5 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1678 ms: Scavenge 116.7 (305.0) -> 116.5 (305.0) MB, 25.0 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1709 ms: Scavenge 127.0 (305.0) -> 126.5 (305.0) MB, 20.7 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1738 ms: Scavenge 132.3 (305.0) -> 132.1 (305.0) MB, 23.9 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1767 ms: Scavenge 142.4 (305.0) -> 141.9 (305.0) MB, 19.6 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1796 ms: Scavenge 147.9 (305.0) -> 147.7 (305.0) MB, 23.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1825 ms: Scavenge 157.8 (305.0) -> 157.3 (305.0) MB, 19.9 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1853 ms: Scavenge 163.5 (305.0) -> 163.2 (305.0) MB, 22.2 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1881 ms: Scavenge 173.2 (305.0) -> 172.7 (305.0) MB, 19.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1910 ms: Scavenge 179.1 (305.0) -> 178.8 (305.0) MB, 23.0 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1944 ms: Scavenge 188.6 (305.0) -> 188.1 (305.0) MB, 25.1 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 1979 ms: Scavenge 194.7 (305.0) -> 194.4 (305.0) MB, 28.4 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 2011 ms: Scavenge 204.0 (305.0) -> 203.6 (305.0) MB, 23.4 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 2041 ms: Scavenge 210.2 (305.0) -> 209.9 (305.0) MB, 23.8 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 2074 ms: Scavenge 219.4 (305.0) -> 219.0 (305.0) MB, 24.5 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 2105 ms: Scavenge 225.8 (305.0) -> 225.4 (305.0) MB, 24.7 / 0.0 ms allocation failure [20872:0x7f26f24c70d0] 2138 ms: Scavenge 234.8 (305.0) -> 234.4 (305.0) MB, 23.1 / 0.0 ms allocation failure [...SNIP...] $
因此这里关键的发现是直接在旧空间中分配伸展树节点可基本避免在周围复制对象的所有开销,并且将次要 GC 周期的数量减少到最小(从而减少 GC 引起的停顿时间)。我们想出了一种称为分配场所预占allocation site pretenuring的机制,当运行到基线代码时,将尝试动态收集分配场所的反馈,以决定在此分配的对象的确切部分是否存在,如果是,则优化代码以直接在旧空间分配对象——即预占对象。
$ out/Release/d8 --trace-gc octane-splay.js [20885:0x7ff4d7c220a0] 8 ms: Scavenge 2.7 (6.0) -> 2.6 (7.0) MB, 1.2 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 10 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.6 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 11 ms: Scavenge 3.6 (8.0) -> 3.6 (10.0) MB, 0.9 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 17 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.9 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 20 ms: Scavenge 5.6 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 26 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.5 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 34 ms: Scavenge 9.6 (17.0) -> 9.5 (28.0) MB, 6.8 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 48 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.6 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 64 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.2 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 96 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 19.6 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 153 ms: Scavenge 61.3 (81.5) -> 57.4 (93.5) MB, 27.9 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 432 ms: Scavenge 339.3 (364.5) -> 326.6 (364.5) MB, 12.7 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 666 ms: Scavenge 563.7 (592.5) -> 553.3 (595.5) MB, 20.5 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 825 ms: Mark-sweep 603.9 (644.0) -> 96.0 (528.0) MB, 4.0 / 0.0 ms (+ 92.5 ms in 51 steps since start of marking, biggest step 4.6 ms, walltime since start of marking 160 ms) finalize incremental marking via stack guard GC in old space requested [20885:0x7ff4d7c220a0] 1068 ms: Scavenge 374.8 (528.0) -> 362.6 (528.0) MB, 19.1 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 1304 ms: Mark-sweep 460.1 (528.0) -> 102.5 (444.5) MB, 10.3 / 0.0 ms (+ 117.1 ms in 59 steps since start of marking, biggest step 7.3 ms, walltime since start of marking 200 ms) finalize incremental marking via stack guard GC in old space requested [20885:0x7ff4d7c220a0] 1587 ms: Scavenge 374.2 (444.5) -> 361.6 (444.5) MB, 13.6 / 0.0 ms allocation failure [20885:0x7ff4d7c220a0] 1828 ms: Mark-sweep 485.2 (520.0) -> 101.5 (519.5) MB, 3.4 / 0.0 ms (+ 102.8 ms in 58 steps since start of marking, biggest step 4.5 ms, walltime since start of marking 183 ms) finalize incremental marking via stack guard GC in old space requested [20885:0x7ff4d7c220a0] 2028 ms: Scavenge 371.4 (519.5) -> 358.5 (519.5) MB, 12.1 / 0.0 ms allocation failure [...SNIP...] $
事实上,这完全解决了 SplayLatency 基准的问题,并提高我们的得分至超过 250%!
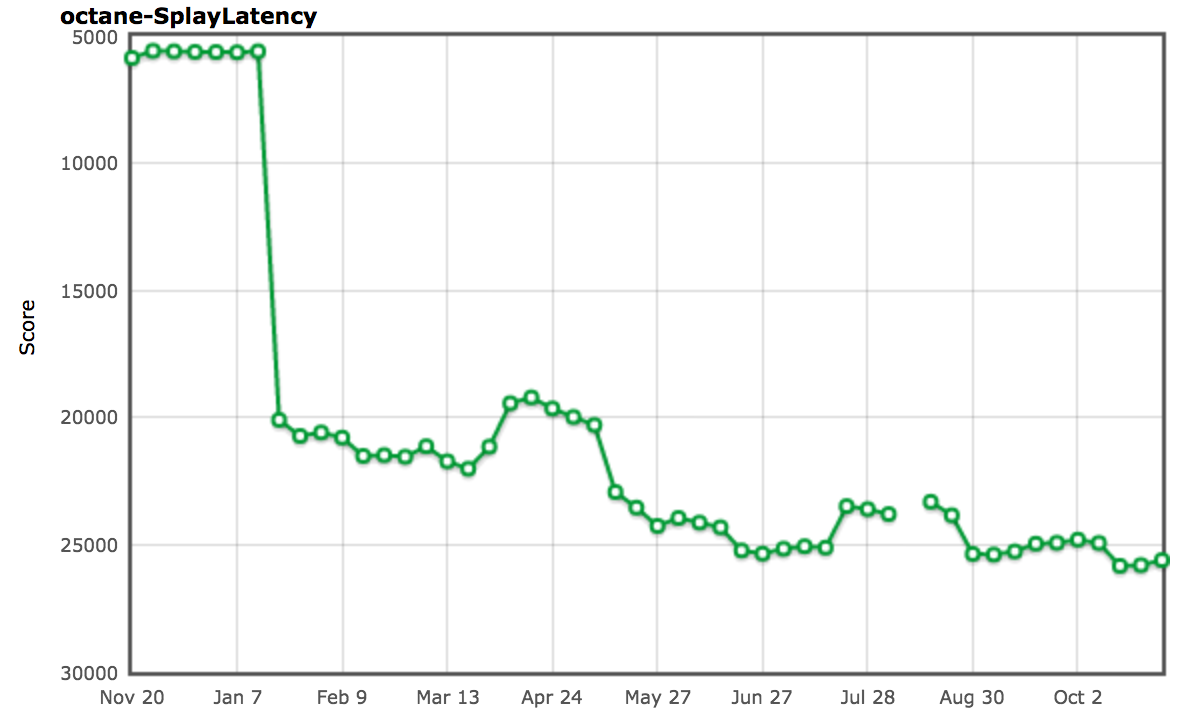
正如 SIGPLAN 论文 中所提及的,我们有充分的理由相信,分配场所预占机制可能真的赢得了真实世界应用的欢心,并真正期待看到改进和扩展后的机制,那时将不仅仅是对象和数组字面量。但是不久后我们意识到分配场所预占机制对真实世界应用产生了相当严重的负面影响。我们实际上听到很多负面报道,包括 Ember.js 开发者和用户的唇枪舌战,虽然不仅是因为分配场所预占机制,不过它是事故的罪魁祸首。
分配场所预占机制的基本问题数之不尽,这在今天的应用中非常常见(主要是由于框架,同时还有其它原因),假设你的对象工厂最初是用于创建构成你的对象模型和视图的长周期对象的,它将你的工厂方法中的分配场所转换为永久状态,并且从工厂分配的所有内容都立即转到旧空间。现在初始设置完成后,你的应用开始工作,作为其中的一部分,从工厂分配临时对象会污染旧空间,最终导致开销昂贵的垃圾回收周期以及其它负面的副作用,例如过早触发增量标记。
我们开始重新考虑基准驱动的工作,并开始寻找现实场景驱动的替代方案,这导致了 Orinoco 的诞生,它的目标是逐步改进垃圾回收器;这个努力的一部分是一个称为“统一堆unified heap”的项目,如果页面中所有内容基本都存在,它将尝试避免复制对象。也就是说站在更高的层面看:如果新空间充满活动对象,只需将所有新空间页面标记为属于旧空间,然后从空白页面创建一个新空间。这可能不会在 SplayLatency 基准测试中得到相同的分数,但是这对于真实用例更友好,它可以自动适配具体的用例。我们还考虑并发标记concurrent marking,将标记工作卸载到单独的线程,从而进一步减少增量标记对延迟和吞吐量的负面影响。
轻松一刻

喘口气。
好吧,我想这足以强调我的观点了。我可以继续指出更多的例子,其中 Octane 驱动的改进后来变成了一个坏主意,也许改天我会接着写下去。但是今天就到此为止了吧。
结论
我希望现在应该清楚为什么基准测试通常是一个好主意,但是只对某个特定的级别有用,一旦你跨越了有用竞争useful competition的界限,你就会开始浪费你们工程师的时间,甚至开始损害到你的真实世界的性能!如果我们认真考虑 web 的性能,我们需要根据真实世界的性能来测评浏览器,而不是它们玩弄一个四年前的基准的能力。我们需要开始教育(技术)媒体,可能这没用,但至少请忽略他们。
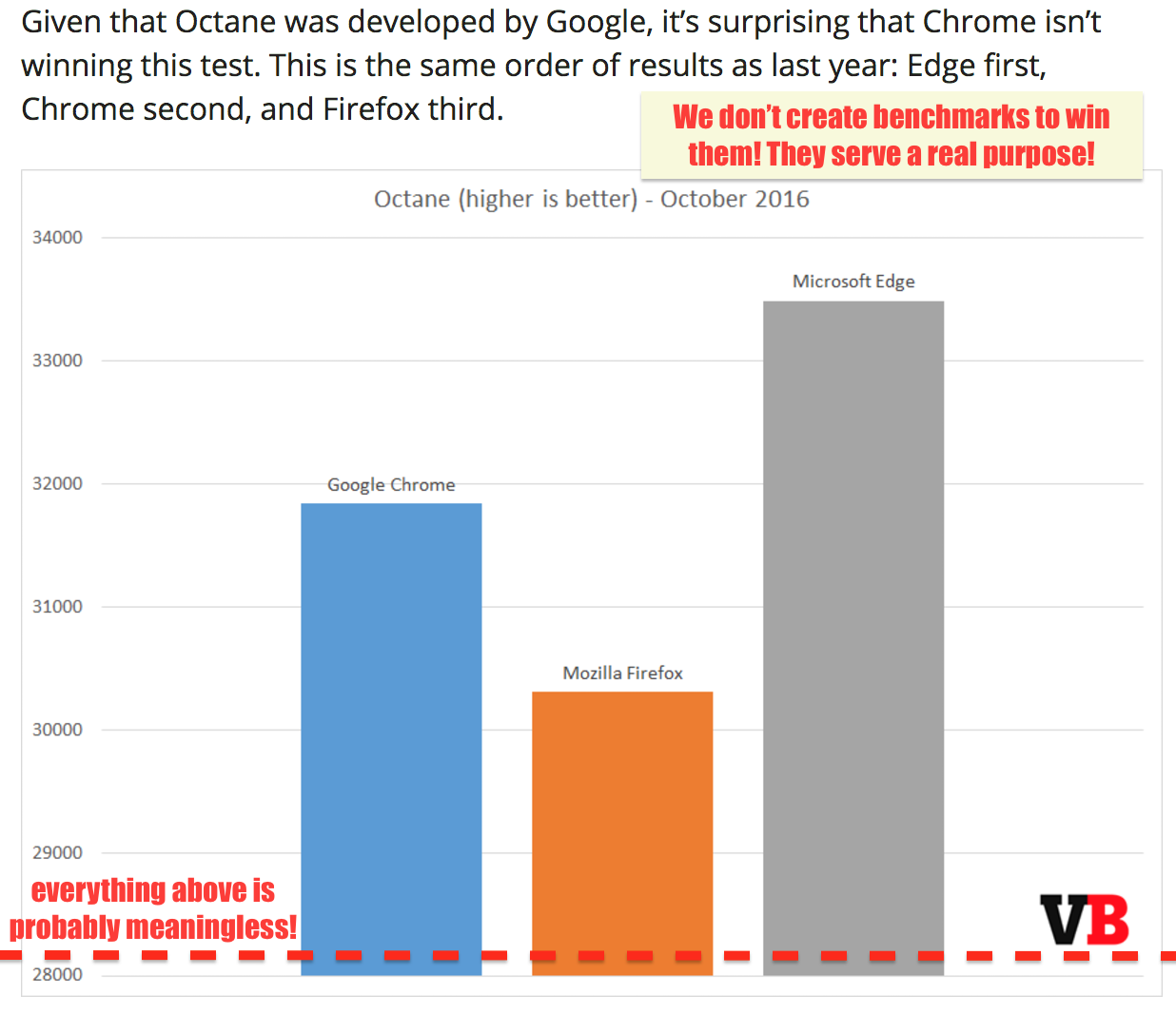
没人害怕竞争,但是玩弄可能已经坏掉的基准不像是在合理使用工程时间。我们可以尽更大的努力,并把 JavaScript 提高到更高的水平。让我们开展有意义的性能测试,以便为最终用户和开发者带来有意思的领域竞争。此外,让我们再对运行在 Node.js( V8 或 ChakraCore)中的服务器端和工具端代码做一些有意义的改进!

结束语:不要用传统的 JavaScript 基准来比较手机。这是真正最没用的事情,因为 JavaScript 的性能通常取决于软件,而不一定是硬件,并且 Chrome 每 6 周发布一个新版本,所以你在三月份的测试结果到了四月份就已经毫不相关了。如果为手机中的浏览器做个排名不可避免,那么至少请使用一个现代健全的浏览器基准来测试,至少这个基准要知道人们会用浏览器来干什么,比如 Speedometer 基准。
感谢你花时间阅读!
作者简介:
我是 Benedikt Meurer,住在 Ottobrunn(德国巴伐利亚州慕尼黑东南部的一个市镇)的一名软件工程师。我于 2007 年在锡根大学获得应用计算机科学与电气工程的文凭,打那以后的 5 年里我在编译器和软件分析领域担任研究员(2007 至 2008 年间还研究过微系统设计)。2013 年我加入了谷歌的慕尼黑办公室,我的工作目标主要是 V8 JavaScript 引擎,目前是 JavaScript 执行性能优化团队的一名技术领导。
译文出处:https://www.zcfy.cc/article/the-truth-about-traditional-javascript-benchmarks
via: http://benediktmeurer.de/2016/12/16/the-truth-about-traditional-javascript-benchmarks
作者:Benedikt Meurer 译者:OneNewLife 校对:OneNewLife, wxy
共同学习,写下你的评论
评论加载中...
作者其他优质文章



