
场景描述
从全文检索或者缓存中获取ID,根据ID查询数据库获取基础信息,进行页面展示
SQL:select * from table where id in(id1,id2,id3...id40)
此种场景的常规方案是将id对应的基础信息在redis中缓存一份,mysql只是做为后端存储。我们做如下测试就是尝试mysql是否可应对这种查询场景。然而根本原因是DBA告诉我,现在MySQL性能已经极其厉害。
数据量说明
1.8亿条数据
使用Oneproxy分为200个数据表(200个表在同一台机器)
因为id是随机的,查询时oneproxy会将查询分散到所有后端MySql
性能指标
并发数
每次查询的响应时间
MySql服务器
腾讯云提供的MySQL服务
mysql的具体配置不在这里列举,即下面的性能报告只是特定场景下的性能分析,不代表mysql的“真实”性能。本文核心是提供一种测试方法,而不是单纯的提供一份数据报告 。
测试程序简介
基础:php、swoole协程
使用协程控制程序的并发数,每个协程中执行一次查询。当一次查询完成,管道通知开始新的查询。
程序代码
mysql_test.php
<?phpini_set('memory_limit', '1280M'); //协程会耗费较多的内存define('MAX_MYSQLPOOL_NUM', $argv['1']); //mysql最大连接数,即并发数define('TESTCOUNT', $argv['2']); //一共的测试次数$mysqlconf = [ 'host' => '127.0.0.1', 'port' => 3307, 'user' => 'root', 'password' => '123456', 'database' => '', 'timeout' => 10];
Swoole\Coroutine::create(function () use ($mysqlconf) {
$stime = microtime(true); //程序开始时间
$pool = new MysqlPool($mysqlconf);
$chan = new chan(MAX_MYSQLPOOL_NUM); //并发数,协程间使用channel通信
for($i = 1; $i< TESTCOUNT + MAX_MYSQLPOOL_NUM; $i++) {
$chan->push('x');
Swoole\Coroutine::create(function() use($pool, $chan, $i) { //测试的业务逻辑开始
$conn = $pool->get(); if($conn) {
$sql = "select /* parallel */ * from table where id in (".implode(',', getRandpid()).')';
$time1 = microtime(true);
$conn->query($sql);
$time2 = microtime(true); if($i % intval(TESTCOUNT / 10) == 0) { //输出执行的进度
echo "\n finish $i / ".TESTCOUNT;
}
$pool->put($conn, (($time2 - $time1) * 1000)); //每次查询耗时就不单独做实例,直接修改连接池类做简单统计
} else { echo "\n connect mysql fail,跳过SQL";
} //业务逻辑结束
$chan->pop();
});
}
$etime = microtime(true); echo "\n ============执行结果============="; echo "\n 并发数量: ".MAX_MYSQLPOOL_NUM; echo "\n 查询次数: ".TESTCOUNT; echo "\n 执行总耗时: ".intval($etime - $stime)."秒\n";
echo "\n QPS (查询次数/总耗时) :". intval((TESTCOUNT / ($etime - $stime))); echo "\n 每次查询耗时平均值:".intval($pool->alltime / TESTCOUNT) ."ms"; echo "\n ============end=============\n"; die;
});//数据库连接池,https://wiki.swoole.com/wiki/page/852.htmlclass MysqlPool{ protected $pool; private $mysqlconf; public $alltime; public function __construct($mysqlconf)
{ $this->pool = new SplQueue(); $this->mysqlconf = $mysqlconf; $this->alltime = 0;
} public function put($mysql, $time = 0)
{ $this->pool->push($mysql); $this->alltime += $time;
} public function get()
{ //有空闲连接
if (count($this->pool) > 0) { return $this->pool->pop();
}
$mysql = new Swoole\Coroutine\Mysql();
$res = $mysql->connect($this->mysqlconf); if ($res == false) { echo "\n connect error info: ".$mysql->error."\n"; return false;
} else { return $mysql;
}
}
}//随机生成的数字function getRandpid(){ for ($i = 0; $i < 40; ++$i) {
$ret[] = rand(1, 185724600);
} return $ret;
}测试1:直接连接mysql,查询单表的性能
测试代码:修改以上代码
1:修改mysql配置为直接连接mysql,而不是oneproxy。即端口从3307改为3306
2:“业务逻辑”部分中的SQL改为:
$sql = "select * from table_10 where id in (".implode(',', getRandpid()).')';测试指令:
php mysql_test.php 1 1000 //并发为1,查询1000次php mysql_test.php 10 1000 //并发为10,查询1000次php mysql_test.php 50 10000 //并发为50,查询10000次... php mysql_test.php 500 100000 //并发为500,查询100000次
测试结果:

数据库单表测试
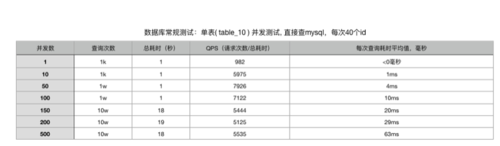
结果分析:
根据主键查询单表,mysql的性能基本可以满足正常业务的需求
测试2
说明
查询oneproxy。因为查询id是随机的,每查一次oneproxy,对应查询的是40个mysql的表。
即,当oneproxy的并发数为1,mysql的对应并发数是40测试代码:
以上提供的代码即为此种情况的代码,无须修改。测试指令:
php mysql_test.php 1 1000 //并发为1,查询1000次php mysql_test.php 10 1000 //并发为10,查询1000次php mysql_test.php 50 10000 //并发为50,查询10000次... php mysql_test.php 100 10000 //并发为100,查询10000次
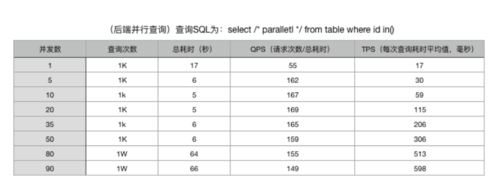
测试结果:
oneproxy并行查询
结果分析:
1:OneProxy做为mysql的代理,对查询性能基本0消耗。
当oneproxy的查询并发为5时,对应mysql的查询并发为200。测试2的结果,并发为5,每次查询耗时30ms。测试1,mysql并发200,每次查询耗时29ms。可得到结论,oneproxy对性能0消耗。2:每次查询耗时太高,很小流量的业务才能使用此方案。
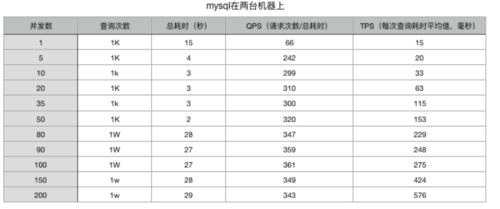
测试3:后端mysql表分散到多台机器
分到两台,测试结果:
image.png
分析:
mysql分到两台机器。同样并发数时,每次查询耗时能缩短一倍。推测:
mysql表分到更多的机器,每次查询耗时能达到测试1的结果,可满足正常的业务需求。
最后,关注性能的同时,也要关注系统的稳定性、开发者的易用性、易维护性。
作者:Dorm_Script
链接:https://www.jianshu.com/p/557044d9ee87
共同学习,写下你的评论
评论加载中...
作者其他优质文章


