
家中想置办些家具,听朋友介绍说苏州蠡(li第二声)口的家具比较出名,因为工作在苏州,也去那边看过,简直...,走断双腿都逛不完,更何况还疲于逛街的。
也浏览过家具城的官网,本着在一定的预算范围之类挑选最合适的,作为一个程序猿,一颗不安分的心,决定自己爬虫下网站,列出个excel表格,也方便给父母辈们查看,顺带再练习下爬虫的。
同样后期实地再去购买时,也可以带上这份表格进行参考。
关于爬虫的文章还有另外两篇实战的:
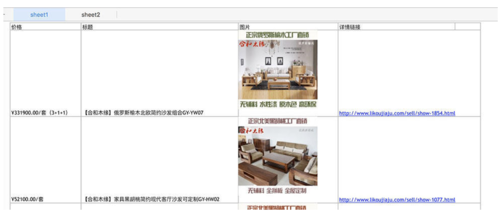
excel表格:
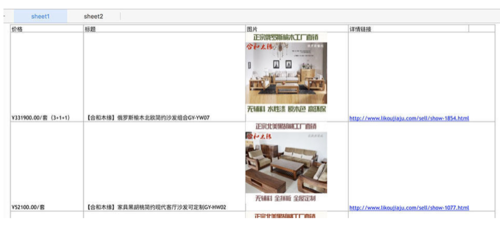
image
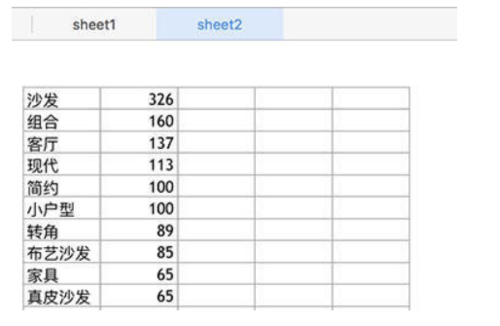
词频统计:
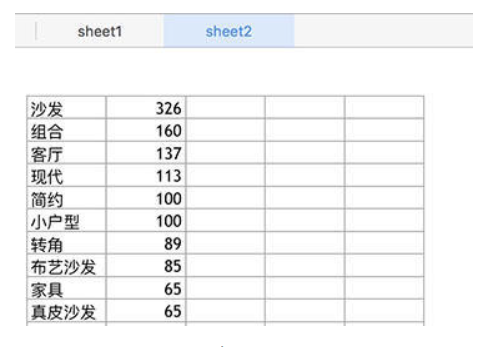
image
爬虫分析
打开官网 http://www.likoujiaju.com/ ,可以看到分类,这里以「沙发」来举例。
总共8页的数据,第一页的网址里 sell/list-66.html,第二页的sell/list-66-2.html,所以sell/list-66-1.html也就是第一页数据了,这样就更方便遍历网址来获取数据了。
同时这里使用BeautifulSoup解析数据,F12查找标题、价格、图片对应的标签。
def get_data(): # 定义一个列表存储数据
furniture = [] # 用于存放家具名,后续用于生成词频
title_all = ""
# 分页数据获取
for num in range(1, 9):
url = "http://www.likoujiaju.com/sell/list-66-%d.html" % num
response = requests.get(url)
content = BeautifulSoup(response.content, "lxml") # 找到数据所在的div块
sm_offer = content.find("div", class_="sm-offer")
lis = sm_offer.ul.find_all("li") # 遍历每一条数据
for li in lis:
# 价格
price_span = li.find("span", class_="sm-offer-priceNum")
price = price_span.get_text() # 名称
title_div = li.find("div", class_="sm-offer-title")
title = title_div.a.get_text()
title_all = title_all + title + " "
# 图片
photo_div = li.find("div", class_="sm-offer-photo")
photo = photo_div.a.img.get("src") # 详情链接
href = photo_div.a.get("href") # 数组里每一项是元祖
furniture.append((price, title, photo, href)) # 排序
furniture.sort(key=take_price, reverse=True) # 生成excel
create_excel(furniture, title_all)爬取到的价格是string类型的,且有些价格并不明确的,所以这里需要对价格进行处理并排序,用到的list的sort(key=take_price)方法,其中key=take_price指定的方法,使用指定的方法去进行比较排序。
# 传参是列表的每一个元素,这里即元祖def take_price(enum): # 取元祖的第一个参数--价格,处理价格得到数值类型进行比较
price = enum[0] if "面议" in price: # 面议的话就设为0
return 0
start = price.index("¥") end = price.index("/")
new_price = price[start + 1:end] return float(new_price)再对列表进行排序操作,reverse=True降序排列
furniture.sort(key=take_price, reverse=True)
生成表格
这里采用的xlsxwriter库,便于图片的插入,安装pip install xlsxwriter
主要用到的方法:xlsxwriter.Workbook("")创建excel表格。add_worksheet("")创建工作表。write(row, col, *args) 根据行、列坐标将数据写入单元格。set_row(row, height) 设置行高。set_column(first_col, last_col, width) 设置列宽,first_col 指定开始列位置,last_col 指定结束列位置。insert_image(row, col, image[, options]) 用于插入图片到指定的单元格
创建两个表,一个用于存放爬取的数据,一个用于存放词频。
# 创建exceldef create_excel(furniture, title_all):
# 创建excel表格
file = xlsxwriter.Workbook("furniture.xlsx") # 创建工作表1
sheet1 = file.add_worksheet("sheet1") # 定义表头
headers = ["价格", "标题", "图片", "详情链接"] # 写表头
for i, header in enumerate(headers): # 第一行为表头
sheet1.write(0, i, header) # 设置列宽
sheet1.set_column(0, 0, 24)
sheet1.set_column(1, 1, 54)
sheet1.set_column(2, 2, 34)
sheet1.set_column(3, 3, 40) for row in range(len(furniture)): # 行
# 设置行高
sheet1.set_row(row + 1, 180) for col in range(len(headers)): # 列
# col=2是当前列为图片,通过url去读取图片展示
if col == 2:
url = furniture[row][col]
image_data = BytesIO(urlopen(url).read())
sheet1.insert_image(row + 1, 2, url, {"image_data": image_data}) else:
sheet1.write(row + 1, col, furniture[row][col]) # 创建工作表2,用于存放词频
sheet2 = file.add_worksheet("sheet2") # 生成词频
word_count(title_all, sheet2) # 关闭表格
file.close()目录下会生成 furniture.xlsx 表格
image
生成词频
利用jieba分词对家具名进行分词处理,用字典保存各个名词的数量,写入到excel。
# 生成词频def word_count(title_all, sheet):
word_dict = {} # 结巴分词
word = jieba.cut(title_all)
word_str = ",".join(word) # 处理掉特殊的字符
new_word = re.sub("[ 【】-]", "", word_str) # 对字符串进行分割出列表
word_list = new_word.split(",") for item in word_list: if item not in word_dict:
word_dict[item] = 1
else:
word_dict[item] += 1
# 对字典进行排序,按照数目排序
val = sorted(word_dict.items(), key=lambda x: x[1], reverse=True) # 写入excel
for row in range(len(val)): for col in range(0, 2):
sheet.write(row, col, val[row][col])词频统计,实地去购买的时候,也可以根据相应的词汇去咨询卖家~
image
这篇文章用到的爬虫方面的知识还是比较基础的,excel表格的生成也是xlsxwriter库的使用,制作成表格也方便父母辈查看。当然,爬虫的数据还可以用在许多地方。
详细代码见
github地址:https://github.com/taixiang/furniture
作者:程序猿tx
链接:https://www.jianshu.com/p/e1563b78268a
共同学习,写下你的评论
评论加载中...
作者其他优质文章


