
概要:了解了爬虫的基础知识后,接下来我们来使用框架来写爬虫,用框架会使我们写爬虫更加简单,接下来我们来了解一下,pyspider框架的使用,了解了该框架,妈妈再也不用担心我们的学习了。
前期准备:
1、安装pyspider:pip3 install pyspider
2、安装Phantomjs:在官网下载解压后,并将pathtomjs.exe拖进安装python路径下的Scripts下即可。
下载地址:https://phantomjs.org/dowmload.html
官方API地址:http://www.pyspider.cn/book/pyspider/self.crawl-16.html
2、用法(这里只简要介绍,更多请看官方文档):
1、首先启动pyspider
在黑窗口中输入pyspider all 即可看到如下。
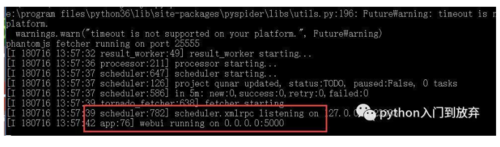
提醒我们在http://localhost:5000端口打开即可。(注意不要关闭!)
打开后点击右边的Create创建项目,Project Name是项目名称,
Start URL(s)是你要爬取的地址点击Create就可以创建一个项目。
2、了解pyspider的格式和过程
创建之后我们会看到如下:
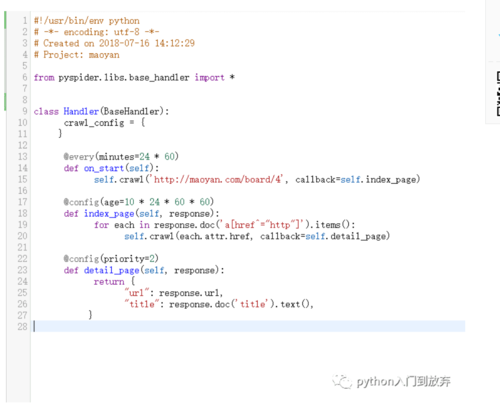
Handler方法是pysqider的主类,继承BaseHandler,所有的功能,只需要一个Handler就可以解决。
crawl_config = {}表示全局的配置,比如可以之前学的那样,定义一个headers
@every(minutes=24 * 60)every属性表示爬取的时间间隔,minutes=24*60即是一天的意思,也就是说一天爬取一次。
on_start方法:是爬取的入口,通过调用crawl方法来发送请求,
callback=self.index_page:callback表示回调函数,也就是说将请求的结果交给index_page来处理。
@config(age=10 * 24 * 60 * 60)是设置任务的有效时间为10天,也就是说在10天内不会重复执行。
index_page函数:就是进行处理的函数,参数response,表示请求页面的返回内容。
接下来的内容相必大家也看得懂,通过pyquery解析器(pyspider可以直接使用该解析器)获取所有的链接。并依次去请求。然后调用detail_page来处理,得到我们想要的东西。
@config(priority=2)priority表示爬取的优先级,没有设置默认为0,数字越大,可优先调用。
crawl的其他参数:
exetime:表示该任务一个小时候执行
self.crawl('http://maoyan.com/board/4', callback=self.detail_page,exetime=time.time()+60*60)
retries:可以设置重复次数,默认为3
auto_recrawl:设置为True时,当任务过期,即age的时间到了之后,再次执行。
method:即HTTP的请求方式默认为get
params:以字典的形式添加get的请求参数
self.crawl('http://maoyan.com/board/4', callback=self.detail_page,params={'a':'123','b':'456'})
data:post的表单数据,同样是以字典的形式
files:上传文件
self.crawl('http://maoyan.com/board/4', callback=self.detail_page,method='post',files={filename:'xxx'})
user_agent:即User-Agent
headers:即请求头信息
cookies:字典形式
connect_timeout:初始化的最长等待时间,默认20秒
timeout:抓取页面的最长等待时间
proxy:爬取时的代理,字典形式
fetch_type:设置成js即可看到javascript渲染的页面,需要安装Phantomjs
js_script:同样,也可以执行自己写的js脚本。如:
self.crawl('http://maoyan.com/board/4', callback=self.detail_page,js_script='''
function(){
alert('123')
}
''')
js_run_at:和上面运行js脚本一起使用,可以设置运行脚本的位置在开头还是结尾
load_images:在加载javascript时,是否加载图片,默认为否
save:在不同方法之间传递参数:
def on_start(self):
self.crawl('http://maoyan.com/board/4', callback=self.index_page,save={'a':'1'})
def index_page(self,response):
return response.save['a']
3、保存之后的项目是这样的
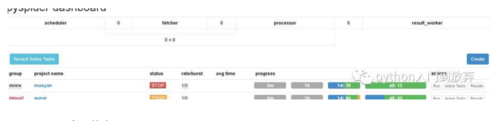
status表示状态:
TODO:表示项目刚刚被创建的状态
STOP:表示停止
CHECKING:正在运行的项目被修改的状态
DEBUG/RUNNING:都是运行,DEBUG可以说是测试版本。
PAUSE:出现多次错误。
如何删除项目?
将group修改成delete,staus修改成STOP,24小时后系统自动删除
actions:
run表示运行
active tasks 查看请求
results 查看结果
tate/burst:
1/3表示1秒发送一个请求,3个进程
progress:表示爬取的进度。
4、完。
(你也可以根据自己的需要,添加自己的方法。后续会有用pyspider爬取的例子。)
作者:初新晓
链接:https://www.jianshu.com/p/bfae053441e6
共同学习,写下你的评论
评论加载中...
作者其他优质文章


