
在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,Q-Table则不再适用。
通常做法是把Q-Table的更新问题变成一个函数拟合问题,相近的状态得到相近的输出动作。通过更新参数θ使Q函数逼近最优Q值:Q(s,a;θ)≈Q′(s,a)
而深度神经网络可以自动提取复杂特征,因此,面对高维且连续的状态使用深度神经网络最合适不过了。
我们称其为深度强化学习(Deep Reinforcement Learning,DRL)
DRL是将深度学习(DL)与强化学习(RL)结合,直接从高维原始数据学习控制策略。DL与RL的结合同时也存在一些问题,比如说:
1.DL通常是监督学习;而RL只有reward返回值,而且伴随着噪声,延迟,稀疏(很多State的reward是0)等情况
2.DL的样本独立;RL前后state状态相关
3.DL目标分布固定;RL的分布一直变化
针对这些问题,我们引入卷起神经网络(CNN)和Q-Learning的思路,CNN的输入是原始数据(作为状态State),输出则是每个动作Action对应的价值评估Value Function(Q值)。从而形成了一种新的算法——DQN(Deep Q-Learning)
DQN解决以上问题的方法:
1.通过Q-Learning使用reward来构造标签
2.通过experience replay(经验池)的方法来解决相关性及非静态分布问题
3.使用一个CNN(MainNet)产生当前Q值,使用另外一个CNN(Target)产生Target Q值
一.构造标签
DQN基于Q-Learning来确定Loss Function。
Q-Learning的更新公式:
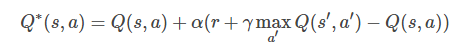
而DQN的Loss Function为
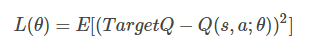
其中 θ 是网络参数,目标为
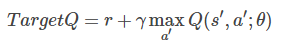
显然Loss Function是基于Q-Learning更新公式的第二项确定的,两个公式意义相同,都是使当前的Q值逼近Target Q值。
二.经验池(experience replay)
经验池的功能主要是解决相关性及非静态分布问题。具体做法是把每个时间步agent与环境交互得到的转移样本 (st,at,rt,st+1) 储存到回放记忆单元,要训练时就随机拿出一些(minibatch)来训练。(其实就是将游戏的过程打成碎片存储,训练时随机抽取就避免了相关性问题)
三.目标网络
在Nature 2015版本的DQN中提出了这个改进,使用另一个网络(这里称为TargetNet)产生Target Q值。具体地,Q(s,a;θi) 表示当前网络MainNet的输出,用来评估当前状态动作对的值函数;Q(s,a;θi−) 表示TargetNet的输出,代入上面求 TargetQ 值的公式中得到目标Q值。根据上面的Loss Function更新MainNet的参数,每经过N轮迭代,将MainNet的参数复制给TargetNet。
引入TargetNet后,再一段时间里目标Q值使保持不变的,一定程度降低了当前Q值和目标Q值的相关性,提高了算法稳定性。
总结
DQN是第一个将深度学习模型与强化学习结合在一起从而成功地直接从高维的输入学习控制策略。它基于Q-Learning构造Loss Function,通过experience replay(经验池)解决相关性及非静态分布问题;使用TargetNet解决稳定性问题。
优点:
1.算法通用性,可玩不同游戏;
2.End-to-End 训练方式;
3.可生产大量样本供监督学习。
缺点:
1.无法应用于连续动作控制;
2.只能处理只需短时记忆问题,无法处理需长时记忆问题(后续研究提出了使用LSTM等改进方法);
3.CNN不一定收敛,需精良调参。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



