
Attention机制在时序模型中的应用,已经被证明能够提升模型的性能。本文参考《Attentive pooling Networks》,该论文以时序模型输出状态设计Attention为基线(QA_LSTM_ATTENTION),提出了一种同时对问题和答案进行特征加权的Attention设计方案。本文实现了论文中基于LSTM网络结构的Attention设计,即AP-BILSTM。
传统的Attention机制被应用于特征抽取器之后,例如QA_LSTM_ATTENTION。由于RNN算法用于处理时序特征的特点,隐含状态迭代更新,因此t时刻的状态包含了从开始到t时刻的所有信息。但是该attention设计仅仅只是通过问题对答案进行特征加权,而忽略了答案对问题的影响,本文考虑到可以同时将attention应用到问题和答案,从而提高算法的准确率,即attentive pooling。
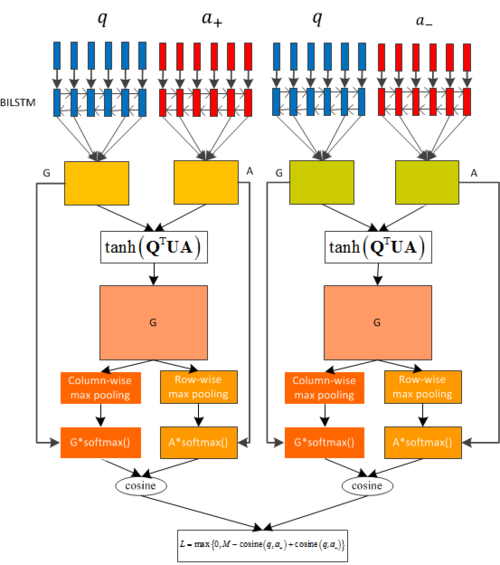
AP-BILSTM算法
AP-BILSTM算法的设计是将问题和答案经过BILSTM抽取特征,然后通过问题和答案的特征计算soft alignment,该矩阵包含了问题和答案相互作用的重要性得分,对该矩阵的列取最大,即可得到答案对问题的重要性得分,而对该矩阵行取最大,即可得到问题对答案的重要性得分。
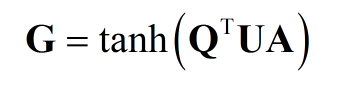
AP-BILSTM算法实验步骤
1:本次实验采用insuranceQA数据,你可以在这里获得。实验之前首先对问题和答案按字切词,然后采用word2vec对问题和答案进行预训练(这里采用按字切词的方式避免的切词的麻烦,并且同样能获得较高的准确率)。
2:由于本次实验采用固定长度的LSTM,因此需要对问题和答案进行截断(过长)或补充(过短)。
3:实验建模Input。本次实验采用问答三元组的形式进行建模(q,a+,a-),q代表问题,a+代表正向答案,a-代表负向答案。insuranceQA里的训练数据已经包含了问题和正向答案,因此需要对负向答案进行选择,实验时我们采用随机的方式对负向答案进行选择,组合成(q,a+,a-)的形式。
4:将问题和答案进行Embedding(batch_size, sequence_len, embedding_size)表示。

5:对问题和答案采用BILSTM模型计算特征Q(sequence_len, batch_size, rnn_size)、 A。
6:通过Q和A计算邻接矩阵G,其中矩阵U是模型学习的参数矩阵。

7:计算问题和答案的attention权重向量,并由该权重向量得到最终的问题和答案的特征。

8:根据问题和答案最终计算的特征,计算目标函数(cosine_similary)。

参数设置:
1:、这里优化函数采用论文中使用的SGD(采用adam优化函数时效果会差大概1个点)。
2、学习速率为0.1。
3:、训练100轮,大概需要5个小时的时间。
4、margin这里采用0.2,其它参数也试过0.15、0.25效果一般。
5、这里训练没有采用dropout和l2约束,之前试过dropout和l2对实验效果没有提升,这里就没有采用了。
6、batch_size为64。
7、这里问题长度截断为30个字,答案长度截断为100个字。
8、rnn_size为400(继续调大没有明显的效果提升,而且导致训练速度减慢)
9、字预训练采用100维。
实验结果对比:
AP-BILSTM:0.665
AP-BILSTM-maxpooling:0.682
AP-BIGRU:0.677
这里尝试了两种不同pooling方式,从结果来看maxpooling会稍微好点,但是整体相差不大。rnn_size都为300时,采用GRU网络结果替换LSTM,实验效果有一定的提升,但是增大rnn_size到400时,GRU网络效果下降,而BILSTM有小幅度的提升。
参考文献
如果有任何问题欢迎发送邮件到lirainbow0@163.com。
作者:lirainbow0
链接:https://www.jianshu.com/p/2b3a7d0a397e
共同学习,写下你的评论
评论加载中...
作者其他优质文章



