
没吃过猪肉,但得看过猪跑。虽然我们暂时对深度学习及神经网路的基本原理知之甚少,但获得深刻理性认识必须建立在足够的感性认知之上,就像掌握游泳技巧的前提是把自己泡到水里。因此我们在研究分析神经网络的技术原理时,先用代码构建一个实用的智能系统,通过运行后看结果的方式,我们就能快速建立起对深度学习相关技术的感知,这为我们后续建立扎实的理论体系奠定坚实的基础。
神经网络系统的开发一般都使用python语言,我们也不例外,我们的手写数字识别系统将使用python来开发,首先要做的是在机器上安装开发环境,也就是Anacoda。安装好了后,我们需要继续安装开发神经网络最常用的开发框架,这里我们选择Keras,打开控制台,输入下面命令行:
install -c conda-forge keras
这样我们就能自动在Anacoda开发环境里嵌入Keras框架,上面命令运行后如图所示:
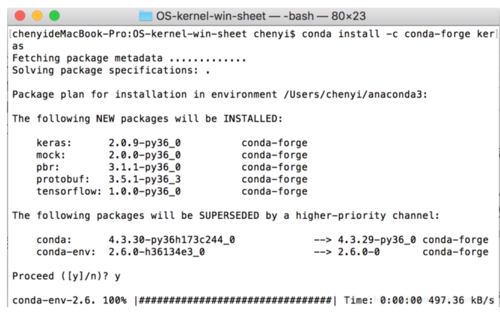
这里写图片描述
我们需要注意的是,要选择Linux系列系统来进行开发,Kares框架对windows的支持不是很好。完成上面开发环境的设置后,我们尽可以着手代码的编写。
首先我们先引入用于训练神经网络的数据集,代码如下:
from keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data() print(train_images.shape)
这段代码将训练数据和检测数据加载到内存中,train_images是用于训练系统的手写数字图片,train_labels是用于标志图片的信息,test_images是用于检测系统训练效果的图片,test_labels是test_images图片对应的数字标签。代码运行后,情况如下:
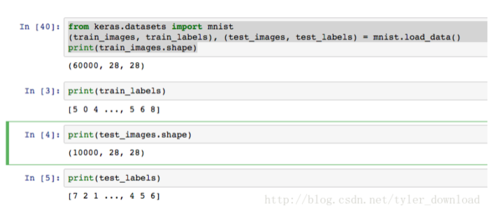
这里写图片描述
第一行打印结果表明,train_images是一个含有60000个元素的数组,数组中的元素是一个二维数组,二维数组的行和列都是28.也就是说,一个首先数字图片的像素大小是28*28。我们打印出来的train_lables数组表明,第一张手写数字图片的内容是数字5,第二种图片是数字0,以此类推。
print(test_images.shape)的结果表示,用于检验系统效果的图片有10000张,print(test_labels)输出结果表明,用于检测的第一张图片内容是数字7,第二张是数字2,依次类推。
接下来我们把用于测试的第一张图片打印出来看看,代码如下:
digit = test_images[0]import matplotlib.pyplot as plt plt.imshow(digit, cmap=plt.cm.binary) plt.show()
上面代码执行后的结果为:
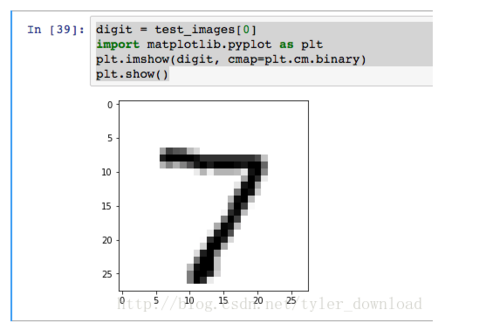
这里写图片描述
通过我们人眼识别可以看出,图片里面黑色图案表示的确实是一个数字7,我们需要做的就是让计算机也能把它识别出来。接下来我们要使用Keras迅速搭建一个有效识别图案的神经网络,代码如下:
from keras import modelsfrom keras import layers network = models.Sequential() network.add(layers.Dense(512, activation='relu', input_shape=(28*28,))) network.add(layers.Dense(10, activation='softmax'))
我们先将代码相关组件从keras框架里引入,代码里的layers表示的就是神经网络中的一个数据处理层。models.Sequential() 表示我们要把每一个数据处理层串联起来,就好像用一根线把一排珠子串起来一样。神经网络的数据处理层之间的组合方式有多种,串联是其中一种,也是最常用的一种。
layers.Dense(...)就是构造一个数据处理层。input_shape(28*28,)表示当前处理层接收的数据格式必须是长和宽都是28的二维数组,后面的“,“表示数组里面的每一个元素到底包含多少个数字都没有关系,例如:
[ [1,2], [3,4], [5,6], [7,8] ]
表示的就是一个2*2的二维数组,只不过数组的每个元素是一个含有两个数组的一维数组。代码构造了两个数据处理层,接下来我们需要把数据处理层连接起来,并设置网络的其他部分,回想上一节我们提到的神经网络模型:
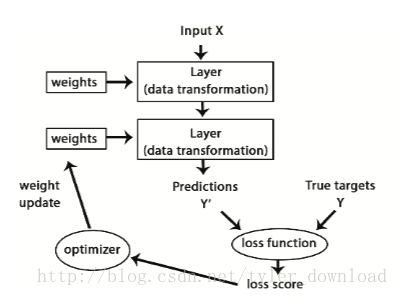
这里写图片描述
前面代码完成了上图中,上半部分含有四个矩形的部分,接着我们要完成下半部分,代码如下:
network.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
代码中的输入参数optimizer, loss都对应着上图中相关组件,metrics的含义我们以后再深究。上面代码完成后,整个神经网络就建立好了,接下来我们需要把数据喂给它,以便对它进行训练,在输入数据前,我们需要把数据做一个处理,相关代码如下:
train_images = train_images.reshape((60000, 28*28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28*28))
test_images = test_images.astype('float32') / 25其中reshape(60000, 28*28) 的意思是,train_images数组原来含有60000个元素,每个元素是一个28行,28列的二维数组,现在把每个二维数组转变为一个含有28*28个元素的一维数组。由于数字图案是一个灰度图,图片中每个像素点值的大小范围在0到255之间,代码train_images.astype("float32")/255 把每个像素点的值从范围0-255转变为范围在0-1之间的浮点值。
接着我们把图片对应的标记也做一个更该,目前所有图片的数字图案对应的是0到9,例如test_images[0]对应的是数字7的手写图案,那么其对应的标记test_labels[0]的值就是7,我们需要把数值7变成一个含有10个元素的数组,然后在低7个元素设置为1,其他元素设置为0,例如test_lables[0] 的值由7转变为数组[0,0,0,0,0,0,0,1,0,0,], 实现这个功能的代码如下:
from keras.utils import to_categorical
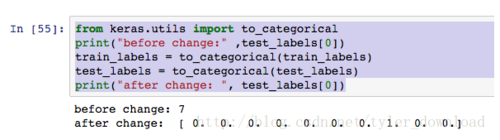
print("before change:" ,test_labels[0])
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
print("after change: ", test_labels[0])上面代码执行后效果如下:
这里写图片描述
数据格式处理完毕后,我们就把数据输入网络进行训练,这里我们只需要一行代码:
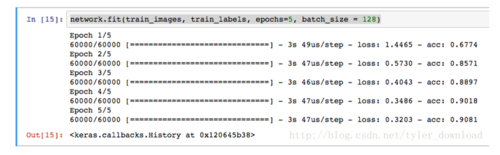
network.fit(train_images, train_labels, epochs=5, batch_size = 128)
上面代码参数需要解析一下,train_images是用于训练的手写数字图片,train_labels对应的是图片的标记,batch_size 的意思是,每次网络从输入的图片数组中随机选取128个作为一组进行计算,每次计算的循环是五次,这些概念我们后面讲解原理时,会详细解释。这句代码运行结果如下:
这里写图片描述
网络经过训练后,我们就可以把测试数据输入,检验网络学习后的图片识别效果了,代码如下:
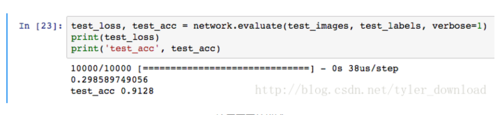
test_loss, test_acc = network.evaluate(test_images, test_labels, verbose=1)print(test_loss)
print('test_acc', test_acc)代码运行的结果如下:
这里写图片描述
运行结果的意思是,用训练后的神经网络判断test_images中的一万张手写数字图案,网络能够正确识别的比率是0.9128,也就是说网络对给定测试图案识别的正确率是91.28%,这个比率不算太高,里面有若干原因,一是神经网络需要运行在GPU上,而我的个人电脑只有CPU没有GPU,由于硬件的原因影响了识别效果,而是网络训练的强度不够大,后面我们讲解原理时,会体验到网络是如何改进自己的识别效率的。
最后,我们输入一张手写数字图片到网络中,看看它的识别效果,代码如下:
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
digit = test_images[1]
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()
test_images = test_images.reshape((10000, 28*28))
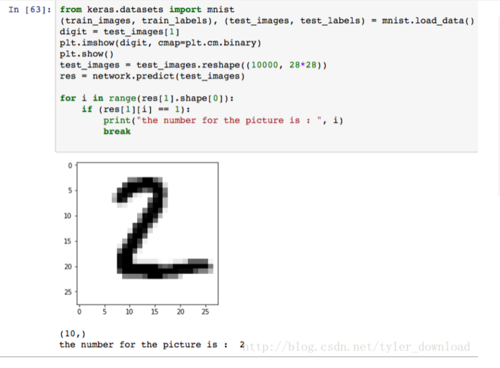
res = network.predict(test_images)for i in range(res[1].shape[0]): if (res[1][i] == 1):
print("the number for the picture is : ", i) break我们把数据重新加载以便,调用神经网络对象的predict接口,将要检测的图片数据传入,接口执行后,会把网络的识别结果返回,上面代码完成后,运行效果如下:
这里写图片描述
我们将识别的第二张图片显示出来,通过肉眼判断它应该是数字2,神经网络识别后给出的结果也是数字2,可见网络经过训练后,具备了足够强的图像识别能力。在没有深度学习算法前,实现这种功能的算法叫OCR,也就是光字符识别,算法的实现异常复杂,而且效果也是很好,而有了深度学习后,不到百行代码就能更好的完成相应功能,这就是深度学习的强大威力。
作者:望月从良
链接:https://www.jianshu.com/p/86256837a5c2
共同学习,写下你的评论
评论加载中...
作者其他优质文章



