
深度学习的广泛运用之一就是对文本按照其内容进行分类。例如对新闻报道根据其性质进行划分是常见的应用领域。在本节,我们要把路透社自1986年以来的新闻数据按照46个不同话题进行划分。网络经过训练后,它能够分析一篇新闻稿,然后按照其报道内容,将其归入到设定好的46个话题之一。深度学习在这方面的应用属于典型的“单标签,多类别划分”的文本分类应用。
我们这里采用的数据集来自于路透社1986年以来的报道,数据中每一篇新闻稿附带一个话题标签,以用于网络训练,每一个话题至少含有10篇文章,某些报道它内容很明显属于给定话题,有些报道会模棱两可,不好确定它到底属于哪一种类的话题,我们先把数据加载到机器里,代码如下:
from keras.datasets import reuters(train_data, train_label), (test_data, test_labels) = reuters.load_data(num_words=10000)
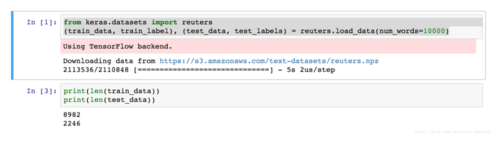
keras框架直接附带了相关数据集,通过执行上面代码就可以将数据下载下来。上面代码运行后结果如下:
这里写图片描述
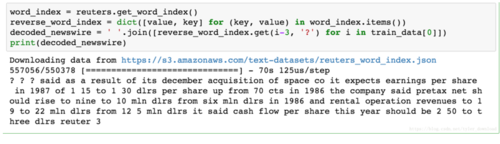
从上面运行结果看,它总共有8982条训练数据和2246条测试数据。跟我们上节数据类型一样,数据里面对应的是每个单词的频率编号,我们可以通过上一节类似的代码,将编号对应的单词从字典中抽取出来结合成一篇文章,代码如下:
word_index = reuters.get_word_index() reverse_word_index = dict([value, key] for (key, value) in word_index.items()) decoded_newswire = ' '.join([reverse_word_index.get(i-3, '?') for i in train_data[0]])print(decoded_newswire)
上面代码运行后结果如下:
这里写图片描述
如同上一节,我们必须要把训练数据转换成数据向量才能提供给网络进行训练,因此我们像上一节一样,对每条新闻创建一个长度为一万的向量,先把元素都初始为0,然后如果某个对应频率的词在文本中出现,那么我们就在向量中相应下标设置为1,代码如下:
import numpy as npdef vectorize_sequences(sequences, dimension=10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) print(x_train[0])
上面代码运行后,我们就把训练数据变成含有1或0的向量了:

这里写图片描述
其实我们可以直接调用keras框架提供的接口一次性方便简单的完成:
from keras.utils.np_utils import to_categorical one_hot_train_labels = to_categorical(train_label) one_hot_test_labels = to_categorical(test_labels)
接下来我们可以着手构建分析网络,网络的结构与上节很像,因为要解决的问题性质差不多,都是对文本进行分析。然而有一个重大不同在于,上一节我们只让网络将文本划分成两种类别,而这次我们需要将文本划分为46个类别!上一节我们构造网络时,中间层网络我们设置了16个神经元,由于现在我们需要在最外层输出46个结果,因此中间层如果只设置16个神经元那就不够用,由于输出的信息太多,如果中间层神经元数量不足,那么他就会成为信息过滤的瓶颈,因此这次我们搭建网络时,中间层网络节点扩大为6个,代码如下:
from keras import modelsfrom keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(layers.Dense(64, activation='relu'))#当结果是输出多个分类的概率时,用softmax激活函数,它将为46个分类提供不同的可能性概率值model.add(layers.Dense(46, activation='softmax'))#对于输出多个分类结果,最好的损失函数是categorical_crossentropymodel.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
像上一节一样,在网络训练时我们要设置校验数据集,因为网络并不是训练得次数越多越好,有了校验数据集,我们就知道网络在训练几次的情况下能够达到最优状态,准备校验数据集的代码如下:
x_val = x_train[:1000] partial_x_train = x_train[1000:] y_val = one_hot_train_labels[:1000] partial_y_train = one_hot_train_labels[1000:]
有了数据,就相当于有米入锅,我们可以把数据输入网络进行训练:
history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))
代码进行了20个周期的循环训练,由于数据量比上一节小,因此速度快很多,与上一节一样,网络的训练并不是越多越好,它会有一个拐点,训练次数超出后,效果会越来越差,我们把训练数据图形化,以便观察拐点从哪里开始:
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
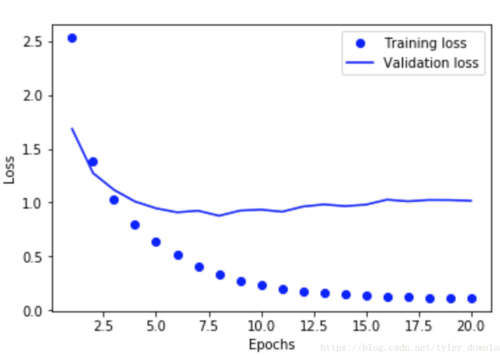
plt.show()上面代码运行后结果如下:
这里写图片描述
通过上图观察我们看到,以蓝点表示的是网络对训练数据的判断准确率,该准确率一直在不断下降,但是蓝线表示的是网络对校验数据判断的准确率,仔细观察发现,它一开始是迅速下降的,过了某个点,达到最低点后就开始上升,这个点大概是在epochs=9那里,所以我们把前面对网络训练的循环次数减少到9:
from keras import modelsfrom keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(layers.Dense(64, activation='relu'))#当结果是输出多个分类的概率时,用softmax激活函数,它将为46个分类提供不同的可能性概率值model.add(layers.Dense(46, activation='softmax'))#对于输出多个分类结果,最好的损失函数是categorical_crossentropymodel.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit(partial_x_train, partial_y_train, epochs=9, batch_size=512, validation_data=(x_val, y_val))
完成训练后,我们把结果输出看看:
results = model.evaluate(x_test, one_hot_test_labels)print(results)
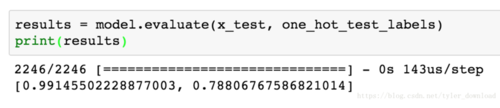
上面两句代码运行结果为:
这里写图片描述
右边0.78表示,我们网络对新闻进行话题分类的准确率达到78%,差一点到80%。我们从测试数据集中拿出一条数据,让网络进行分类,得到结果再与其对应的正确结果比较看看是否一致:
predictions = model.predict(x_test)print(predictions[0])print(np.sum(predictions[0]))print(np.argmax(predictions[0]))print(one_hot_test_labels[0])
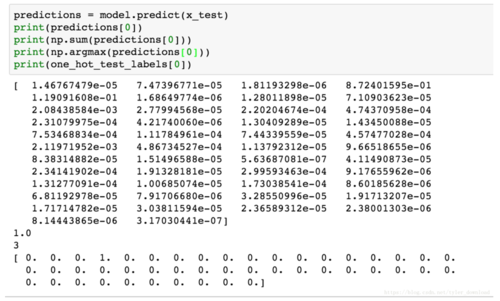
我们让网络对每一条测试数据一一进行判断,并把它对第一条数据的判断结果显示出来,最后我们打印出第一条测试数据对应的分类,最后看看网络给出去的结果与正确结果是否一致,上面代码运行后结果如下:
这里写图片描述
从上面运行结果看到,网络对第一条数据给出了属于46个分类的概率,其中下标为3的概率值最大,也就是第一条数据属于分类4的概率最大,最后打印出来的测试数据对应的正确结果来看,它也是下标为3的元素值为1,也就是说数据对应的正确分类是4,由此我们网络得到的结果是正确的。
前面提到过,由于网络最终输出结果包含46个元素,因此中间节点的神经元数目不能小于46,因为小于46,那么有关46个元素的信息就会遭到挤压,于是在层层运算后会导致信息丢失,最后致使最终结果的准确率下降,我们试试看是不是这样:
from keras import modelsfrom keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(layers.Dense(4, activation='relu'))#当结果是输出多个分类的概率时,用softmax激活函数,它将为46个分类提供不同的可能性概率值model.add(layers.Dense(46, activation='softmax'))#对于输出多个分类结果,最好的损失函数是categorical_crossentropymodel.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit(partial_x_train, partial_y_train, epochs=9, batch_size=512, validation_data=(x_val, y_val)) results = model.evaluate(x_test, one_hot_test_labels) print(results)
上面代码运行后,输出的results结果如下:
[1.4625472680649796, 0.6705253784505788]
从上面结果看到,我们代码几乎没变,致使把第二层中间层神经元数量改成4,最终结果的准确率就下降10个点,所以中间层神经元的减少导致信息压缩后,最后计算的准确度缺失。反过来你也可以试试用128个神经元的中间层看看准确率有没有提升。
到这里不知道你发现没有,神经网络在实际项目中的运用有点类似于乐高积木,你根据实际需要,通过选定参数,用几行代码配置好基本的网络结构,把训练数据改造成合适的数字向量,然后就可以输入到网络中进行训练,训练过程中记得用校验数据监测最优训练次数,防止过度拟合。
在网络的设计过程中,其背后的数学原理我们几乎无需了解,只需要凭借经验,根据项目的性质,设定网络的各项参数,最关键的其实在根据项目数据性质对网络进行调优,例如网络设置几层好,每层几个神经元,用什么样的激活函数和损失函数等等,这些操作与技术无关,取决以个人经验,属于“艺术”的范畴。
作者:望月从良
链接:https://www.jianshu.com/p/c81414c30d6b
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



