
IBM SPSS Modeler Social Network Analysis,中文叫做社交网络分析,本文将一律简称 SNA。
IBM Business Analytics 能够帮助决策者提供可信任的完整的一致和准确的信息,以提高企业业绩。企业智能,预测分析,财务业绩和战略管理的完成解决方案。该方案能够提供对当前业绩的清晰直接和实用的洞察力,以及预测未来结果的能力。从而为帮助用户实现决策自动化提供强有力的支持。许多对行为建模的方法都侧重个人。它们使用有关个人的各种数据生成一个模型,并使用行为的关键指标进行预测。如果任何个人拥有的关键指标值与行为的发生相关联,则可以特殊关注该个人以防止该行为。考虑为流失建模的方法,流失表示客户终止与公司的关系。挽留客户的成本比取代他们的成本低得多,因此要实现识别存在流失风险的客户的能力。分析师通常使用一系列关键绩效指标描述客户,包括人口统计信息和每位个人客户的最近通话模式。基于这些字段的预测模型使用符合过去已流失的客户通话模式的客户通话模式中的变化,以识别增加流失风险的人员。识别为存在风险的客户则获得额外客户服务或服务选项以挽留他们。这些方法会忽略可能严重影响客户行为的社交信息。有关公司和其他人当前行动的信息通过关系流动影响人们。因此,和他人的关系允许那些人影响一个人的决定和行动。只包括个人衡量的分析则忽略了具有预测能力的重要因素。SNA 通过将关系信息处理为可包括在模型中的附加字段解决此问题。这些导出的关键绩效指标衡量个人的社交特征。将这些社交属性与基于个人的衡量结合起来,提供对个人的更好概览,因此可提高您模型的预测精度。
本文将着重介绍 SNA 的概念以及它的日常应用。从而帮助读者了解 SNA 并运用 SNA 解决企业问题。
许多对行为建模的方法都侧重个人。例如在电信行业,分析师通常使用一系列关键绩效指标描述客户,包括人口统计信息和每位个人客户的最近通话模式。基于这些个人的各种数据字段生成的一个模型,并使用关键数据字段进行预测流失风险的人员。这些方法会忽略可能严重影响客户行为的社交信息。有关公司和其他人当前行动的信息通过关系流动影响个人。因此,和他人的社交网络关系允许那些人影响个人的决定和行动。只包括个人衡量的分析则忽略了具有预测能力的重要社交网络因素。 SNA 通过将关系信息处理为可包括在模型中的附加字段解决此问题。这些导出的关键绩效指标衡量个人的社交特征。将这些社交属性与基于个人的衡量结合起来,提供对个人的更好概览,因此可提高您模型的预测精度。
| 节点 | 图标 | 描述 |
|---|---|---|
| 组分析 |  | 以一个固定字段文本文件导入通话详细记录,识别记录定义的网络中的节点组,并为组和个人生成关键绩效指标 |
| 传播分析 |  | 以一个固定字段文本文件导入通话详细记录,在记录定义的网络中传播影响,并生成关键绩效指标以汇总对个人节点传播影响的结果 |
要使用 SNA 分析网络,您需要从数据源提取相关记录和字段,格式化它们以作为输入数据。分析节点需要存储在一个单独的固定宽度文本文件中的通话详细记录。文件的每行对应一种关系,数据组织在以下列中:
发起关系的个人标识符。
作为关系目标的个人标识符。
关系的一个可选权重。
所有数据必须是数字,并且个人标识符限制为整数。可选择包括字段名,作为文件中数据的第一行。例如我们需要如下格式化数据,记录个人之间的通话,当然通话记录可能是成百万上千万,这里只展示在 SNA 分析网络中我们需要的数据源结构。
| 源 | 目标 | 权重 |
|---|---|---|
| 1001 ( A ) | 1002 ( B ) | 20 |
| 1001 ( A ) | 1003 ( C ) | 30 |
| 1001 ( A ) | 1004 ( D ) | 50 |
| 1004 ( D ) | 1005 ( E ) | 10 |
| 1004 ( D ) | 1006 ( F ) | 30 |
| 1003 ( C ) | 1007 ( G ) | 10 |
| 1006 ( F ) | 1007 ( G ) | 40 |
权重值对应于您要用于代表关系重要性的任何衡量。对于通话数据,常用权重包括通话持续时间或通话频率。如果希望分析侧重通话历史记录的子集,您必须在创建输入文件时使用该子集。例如,通过在输入文本文件中仅包括该数据,可将分析限制为过去几个月或最近对个人的通话。当然在 SNA 分析网络中,权重是可选的输入项,但是源和目标项是必须的输入项。对于以上数据,SNA 可以做组分析和传播分析。
组分析使用网络中的个人交互模式,识别类似个人的组。这些组的特征影响个人组成员的行为。同时结合组和个人衡量的预测模型的执行效果将比仅包括后者的模型更好。
这里我们把 SNA 安装后,演示流 GA demos stream.str 为例子。在 GA 节点中读入演示数据 Demo_CDR, 此数据含有两个字段,6,904,236 条通话记录,分别定义为源和目标。通过分析数据按钮,我们可以在组分析源节点窗口的“分析”选项卡提供网络中识别的组摘要概述。注意此处截取了右侧相应的图形显示框。
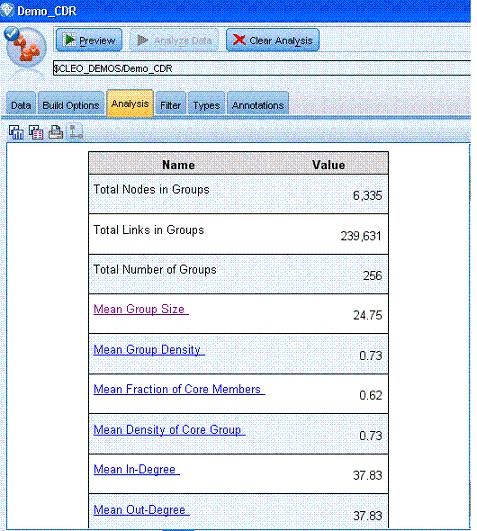
这里我们可以看到通过 SNA 的组分析节点,6,904,236 条通话记录数据中总共有 6335 个节点(用户),在这 6335 个节点(用户)间,有 239631 个联系关系。组分析节点把这 6335 节点(用户)最终划分为 256 个组。
那么组分析是如何划分组的呢 ? 这里介绍一些节的基本概念。
组成员彼此之间应该比不在组中的个人更加相似。在网络分析中,两个节点的相似性取决于它们的关系。对于网络中的任何节点,都有一组节点是该节点定向关系的目标。对于电信数据,这个组对应于特定个人所联系的所有人员。如果两位个人联系同一组人员,则将那些个人视为彼此相似。两位个人所重叠的关系目标组越多,他们就越相似。
| 源节点 | 目标节点 |
|---|---|
| A | B,C,D,E,F,G |
| B | A,C,D,E,F,G |
| C | A,D,H,I |
节点 A 和 B 有五个共用目标节点 , 另一方面,节点 A 和 C 只有一个。因此 , 节点 A 和 B 比节点 A 和 C 的社交相似性更大。具有更大社交相似性的节点,我们会把他们放在一个组中。
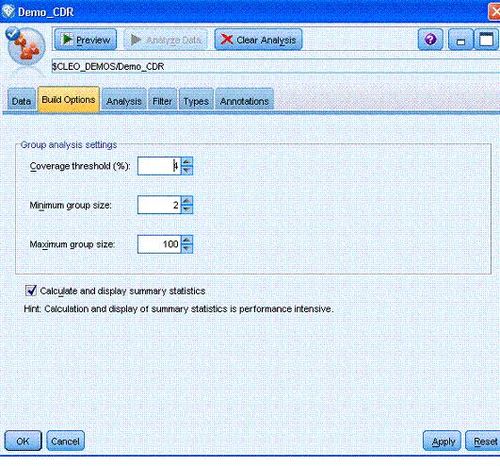
组应包括和其他组成员有高关系权重的个人,其中的权重即衡量关系中节点的相似性。因此,通过忽略网络中较弱的关系开始组标识。范围阈值通过定义要保持的最强关系分数控制此过程。例如,范围阈值 0.4 则会将最强关系的 40% 用于组标识,而忽略剩余 60% 的关系。剩余关系可能产生一些非常小或非常大的组,预测实用性有限。为防止分析中包括类似组,您可指定最小和最大组大小。分析过程会完全忽略小于最小限制的组。但大于最大限制的组则会分为可接受大小范围内更小的组。丢弃弱关系和实施大小限制后剩余的组则为核心组。
从原始网络删除关系,可能导致某些个人不存在于任何核心组中。但那些个人可能与肯定包括在组中的组成员存在关联。假设没有违反组大小限制,如果与组的核心成员有许多相对较强的关系,则会将个人添加到组。因此,最终的组包括一组核心成员,外加由于与核心关联而添加的成员。
用户可以通过定义组分析节点中的建模选项卡来定义参数范围阈值,最小限制组,最大限制组。
节点的权威分数衡量组中其他节点连接到自身的趋势。如果许多个人联系一位特定人员,可能是咨询信息或意见,则该人员拥有权威角色。组中节点的权威分数,对应于通过组网络随机重启的稳态概率,范围从 0 到 1。权威分数越接近 1,该节点在组中的权威就越大。组中拥有最高权威分数的节点则为该组的权威领导。
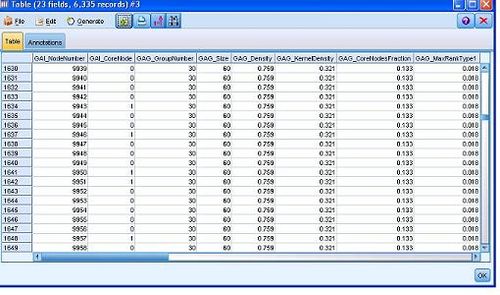
通过组分析源节点窗口的“分析”选项卡我们可以看到网络中识别的组摘要概述,那么具体哪个用户分到哪个组了呢?将组分析节点连接到一个表节点上,运行表节点,我们可以从输出表中得到节点(用户)9939(GAI_NodeNumber) 在组 30 中 (GAG_GroupNumber),该组有 60 个人(GAG_Size),用户 9930 并不是组中核心个人(GAI_CoreNode)。组节点还生成了其它很多关于个人和组的关键绩效指标,具体含义请参考产品帮助文档。
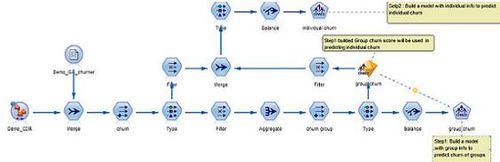
将这些社交属性与基于个人的衡量结合起来,提供对个人的更好概览,因此可提高您模型的预测精度。如下图所示,我们将处理表 2 数据的客户通话数据读入组分析节点中,进行组分析,会得到类似图三组分析的结果,将它和我们通常的客户个人信息数据结合在一起,进行进一步的分析。下图是 Modeler 中建模流图示
对于组分析,组中当许多个人联系一位特定人员,可能是咨询信息或意见,则该人员拥有更权威的权威角色。权威分数也就越接近 1。组中拥有最高权威分数的节点则为该组的权威领导。
传播过程则使用一种扩散激活方法,将节点能量从网络节点反复扩展到它们的直接近邻,接收到能量的近邻节点会被激活,并将部分能量进一步传送到其任何直接近邻,达到传播的目的。当传播完成时,拥有最大传播能量的节点则表示对发起该过程的影响最敏感。所以,如果该过程开始于一个倾向流失的节点,则传播完成时,拥有最高能量的节点其流失的风险就越大。我们就可以为这些节点提供特殊关照,以防止它们流失。
传播系数定义一个激活的节点可传送的能量比例,例如传播系数 0.80 的网络中,则意味着节点 A 将其能量的 80% 传播到作为关系目标的三个近邻,而自己保留 20%。
如果发生下面的一种情况,扩散过程则停止:
激活的节点不是任何定向关系的源。
传送的能量低于精度阈值,其为使过程能继续所传送的能量限制。
迭代数达到指定限制。
用户可以在扩散分析节点建模选项卡来定义这些参数来影响扩散结束条件。
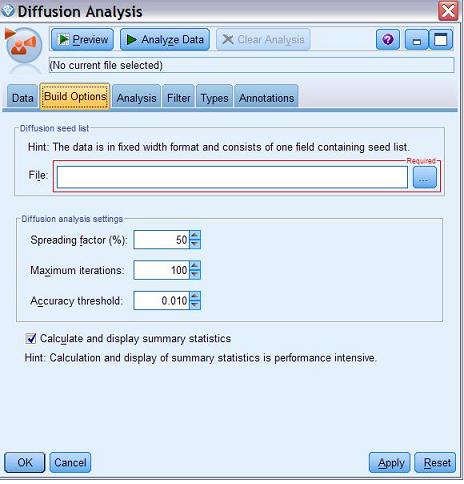
应用 Modeler 可以轻松实现对 Social Network Analysis 数据的读取并结合相应的模型建模。
由于 modeler 仅仅只是一个 application 很难解决客户的实际问题,而 SPSS 的其他产品很好的实现了集成,从而帮助客户实现完整的解决方案。
存储流文件到 CaDS 存储库
集成部署好的 CaDS, 用户可以轻松的实现业务流程中的存储,方便用户以后维护和管理。通过连接 CaDS,modeler client 提供了存储检索功能。训练好的模型以及流文件都可以存储在 CaDS 的存储库。例如存储:
图 6. 在 modeler 客户端建模并将模型部署到 CaDS 上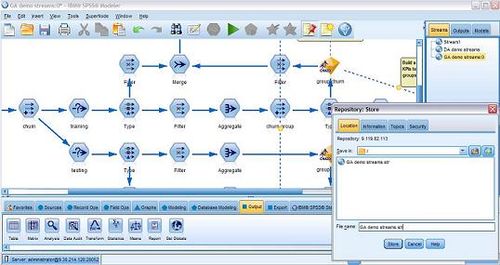
配置 score 到 CaDS 的存储库
用户通过配置 score,从而实际的模型部署在商业应用之中。
图 7. 在 CaDS 的客户端 PEM 上配置 score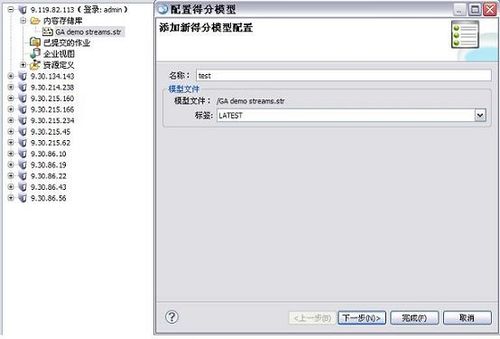
通过浏览器登录 CaDS 根据实际预测数据进行决策
可以实时的对某一对象目标进行评分分析,从而帮助用户解决一些商业应用,比如银行信用卡信用额度评定,个人贷款资格和额度评定等。
应用 CaDS 来定制作业帮助客户收集数据和自动建模及模型比较,优化决策
根据选择的分枝把流文件部署在已配置的 CaDS application。用户可以选择不同的部署方式以及特定的模型。比如,
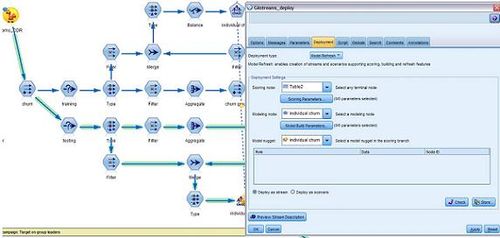
定制作业配置作业类型
结合 CaDS5.0 提供的模型管理功能,用户的流文件可以以不同运行方式被执行,同时丰富的评测功能进一步帮助完善模型。
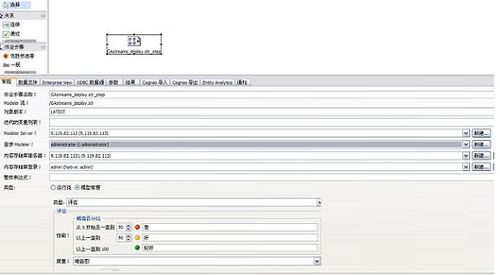
执行作业及模型优化
存储的流文件可以通过模型比较,帮助用户实现模型优化。

数据关联
企业内部的应用是非常复杂的,数据也是多样的。如何结合已有的数据并把它应用于实践,CaDS 提供了非常丰富的功能,用户可以直接配置访问已有的数据,并把它和其他数据关联整合。
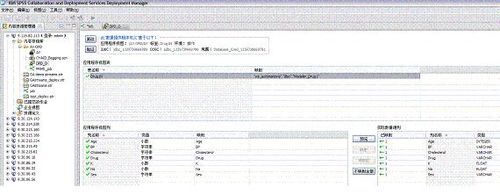
模型训练
Modeler 客户端提供了另一种节点 --EV(enterprise view node),它完美的结合了其他不同的企业数据源,从而帮助用户实现数据整合这一需求。SNA 节点同样适用于此特性,例如。
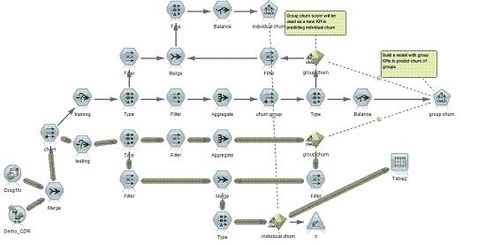
之后,此类流文件的部署、模型应用以及优化方法,与上面所讲的方法类似。此处就不再赘叙。
社会网络分析 (Social Network Analysis,简称 SNA) 使得我们能够理解一个既定人群的网络如何创造和共享知识。本文主要介绍了 SNA 在 modeler 和 CaDS 中的日常应用。希望对初学 SNA 的读者朋友们能有所帮助。 谢谢大家的阅读!
参考数据挖掘概念与技术 ( 原书第 2 版 ) Jiawei Han、Micheline Kamber、范明、 孟小峰机械工业出版社 (2007-03 出版 )。
IBM SPSS Modeler Social Network Analysis 用户手册。
参考深入浅出数据分析 米尔顿 (Michael Milton)、 李芳 电子工业出版社 (2010-09 出版 )。
IBM SPSS Collaboration and Deployment Services 用户手册
共同学习,写下你的评论
评论加载中...
作者其他优质文章



