
1.前言
Android的虚拟机是根据移动设备的特点基于Java虚拟机(JVM)改进而来,虽然没有保留规范,但作为Java语言的使用者,了解一下JVM的规范还是有必要的。
2.JVM内存模型
JVM在执行Java程序时,会把它管理的内存划分为若干个的区域,每个区域都有自己的用途和创建销毁时间。如下图所示,可以分为两大部分,线程私有区和共享区:
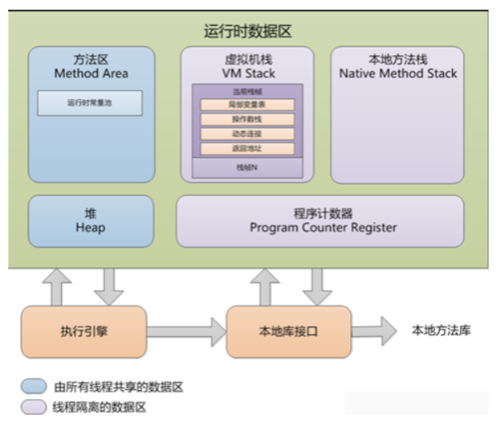
Memory.png
2.1.线程私有区
程序计数器。当同时进行的线程数超过CPU数或其内核数时,就要通过时间片轮询分派CPU的时间资源,不免发生线程切换。这时,每个线程就需要一个属于自己的计数器来记录下一条要运行的指令。如果将是Java方法,则记录执行的字节码地址;是本地方法,则计数器为空。
虚拟机栈,与线程同时创建。每个方法执行时都会创建一个栈帧来存储方法的信息,新调用的方法入栈,返回的出栈,所以栈的大小决定方法调用的可达深度。若需要的栈深度大于可用深度时,则StackOverflowError;若栈进行扩展,但内存不够时,OutOfMemoryError。
本地方法栈,与虚拟机栈作用相似。但它不是为Java方法服务的,而是本地方法(C语言)。由于规范对这块没有强制要求,不同虚拟机实现方法不同。
2.2.线程共享区
此区域是用来存储被各线程共享的数据的。
方法区,用于存放加载类的元数据信息,如常量、静态变量和即时编译器编译后的代码。若要分代,算是永久代,以前类大多“static”的,很少被卸载或收集,现回收废弃常量和无用的类。其中运行时常量池存放编译生成的各种常量。
堆,存放对象实例和数组,是垃圾回收的主要区域,分为新生代和老年代。刚创建的对象在新生代的Eden区中,经过GC后进入新生代的S0区中,再经过GC进入新生代的S1区中,15次GC后仍存在就进入老年代。这是按照一种回收机制进行划分的,不是固定的。若堆的空间不够实例分配,则OutOfMemoryError。
2.3.注意事项
栈是运行时单位,代表着逻辑,内含基本数据类型和堆中对象引用,所在区域连续,没有碎片;堆是存储单位,代表着数据,可被多个栈共享(包括成员中基本数据类型、引用和引用对象),所在区域不连续,会有碎片。
3.垃圾回收
我们都知道调用 System.gc() 方法只是通知系统去回收,是否回收不能确定。
3.1.回收的判断
JVM中,将一个对象真正回收需经历两次标记过程,每次都是先判断对象有没有被持有引用,再判断对象是否必要执行 finalize() 方法。
持有判断。最先使用是引用计数算法,当对象有一个引用,即增加一个计数;删除一个引用,即减少一个计数。计数为零的对象,判断为不可用,但是无法处理循环引用的问题。现主流的都是可达性分析算法,通过将一系列称为GC Roots的对象作为起始点,开始向下搜索,走过的路径则是引用链。若所有GC Roots都与某对象无引用链相连,即不可达时,判断为不可用。
注意:GC Roots对象包括:虚拟机栈(栈帧中的本地变量表)中引用对象;方法区中类静态属性引用的对象;方法区中常量池引用的对象;本地方法栈(一般的本地方法,即JNI)中引用的对象。必要判断。当对象没有重写 finalize() 方法或者 finalize() 方法已被虚拟机调用过,都将视为“没有必要执行”。否则此对象将放置在F-Queue的队列中,由一个虚拟机自动建立的、低优先级的Finalizer线程去触发该方法,但不承诺等待它运行结束,以防执行缓慢或为死循环,导致队列其它对象永久等待,乃至内存回收系统崩溃。
对F-Queue中对象进行二次标记。只要有对象重新与GC Roots对象关联,就会被移出队列,否则GC回收。
3.2.垃圾收集算法
当确定哪些垃圾可以被回收后,需要做的就是高效地进行垃圾回收。由于JVM没有给出明确的规定,各厂商实现方式不同,这里只讨论常见垃圾收集算法的核心思想。
标记-清除算法,最基础的算法,分为两个阶段。标记阶段:标出所有需要被回收的对象;清除阶段:回收被标记对象所占用的空间。但容易产生大量内存碎片,导致无足够空间分配给大对象,从而提前触发垃圾收集动作。
复制算法,为了解决标记-清除算法的缺陷。将可用内存按容量分为大小相等的两块,每次只使用其中的一块。当一块用完时,复制可用对象至另一块并清除自己的内存空间,从而避免出现内存碎片。但可用内存为实际的一半,利用率低;且当存活对象很多时,效率也会降低。
标记-整理算法,吸取以上两种算法优点。标记阶段与标记-清除算法同阶段一致,整理阶段则将存活对象移向一端,再清理边界以外空间。
分代收集算法,目前主流。根据对象存活的生命周期,将内存划分为两大区域。老年代:每次垃圾收集只有少量对象需回收,一般采用标记-整理算法;新生代:每次垃圾收集都有大量对象需回收,大部分采用复制算法。但空间上不是等大的两块,而是一块大的Eden区域,两块小的Survivor区域,每次只使用一大一小两区域。垃圾回收时,它们将内部存活对象都移至空闲的小区域并清理自己。
3.3.垃圾收集器
垃圾收集算法是理论,而垃圾收集器是实现。下面根据海子的文章列出HotSpot(JDK 7)提供的几种垃圾收集器。
Serial/Serial Old 收集器是最基本最古老的收集器,它是一个单线程收集器,并且在它进行垃圾收集时,必须暂停所有用户线程。Serial收集器是针对新生代的收集器,采用的是Copying算法;Serial Old收集器是针对老年代的收集器,采用的是Mark-Compact算法。它的优点是实现简单高效,但是缺点是会给用户带来停顿。
ParNew 收集器是Serial收集器的多线程版本,使用多个线程进行垃圾收集。
Parallel Scavenge/Parallel Old 收集器是多线程(并行)收集器。Parallel Scavenge收集器是针对新生代的收集器,它在回收期间不需要暂停其他用户线程,其采用的是Copying算法,该收集器与前两个收集器有所不同,它主要是为了达到一个可控的吞吐量;Parallel Old收集器是针对老年代的收集器,使用多线程和Mark-Compact算法。
CMS(Current Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它是一种并发收集器,采用的是Mark-Sweep算法。
G1收集器是当今收集器技术发展最前沿的成果,它是一款面向服务端应用的收集器,它能充分利用多CPU、多核环境。因此它是一款并行与并发收集器,并且它能建立可预测的停顿时间模型。
4.内存分配
内存分配主要是在堆上分配,由于涉及到分配时某区域空间不足等问题,需结合垃圾收集器和JVM相关参数,所以规则不是固定的。
5.总结
到这里,基本上可以在写代码时大致知道对象的内存情况,所以一定要注意避免内存泄露及其导致的内存溢出问题。
作者:lanceJin
链接:https://www.jianshu.com/p/6ff6bdb22439
共同学习,写下你的评论
评论加载中...
作者其他优质文章


