
安装lib
材料:
spark : http://spark.apache.org/downloads.htmlhadoop : http://hadoop.apache.org/releases.htmljdk: http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html hadoop-commin : https://github.com/srccodes/hadoop-common-2.2.0-bin/archive/master.zip (for windows7)
需要下载对应的版本
步骤:
a. 安装jdk,默认步骤即可 b. 解压spark (D:\spark-2.0.0-bin-hadoop2.7) c. 解压hadoop (D:\hadoop2.7) d. 解压hadoop-commin (for w7) e. copy hadoop-commin/bin to hadoop/bin (for w7)
环境变量设置
SPARK_HOME = D:\spark-2.0.0-bin-hadoop2.7 HADOOP_HOME = D:\hadoop2.7 PATH append = D:\spark-2.0.0-bin-hadoop2.7\bin;D:\hadoop2.7\bin
Python lib设置
a. copy D:\spark-2.0.0-bin-hadoop2.7\python\pyspark to [Your-Python-Home]\Lib\site-packages b. pip install py4j c. pip install psutil (for windows: http://www.lfd.uci.edu/~gohlke/pythonlibs/#psutil)
Testing
cmd -> pyspark 不报错并且有相应的cmd
——————————————————————————————————
2018-5-11更新
目前spark 不兼容 Python3.6 ,因此通过anaconda创建虚拟环境变量python3.5
之后开启安装之路:
1.查看操作系统:
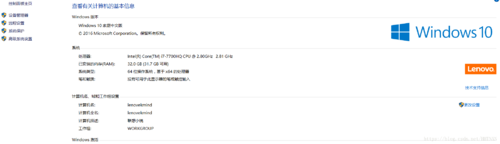
2.下载以下两个文件的压缩文件zip.之后解压如下,并分别配置环境变量

3.配置环境变量:
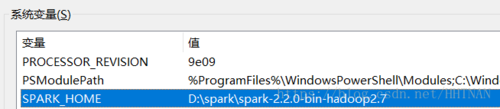

同时在path中添加如下:
%SPARK_HOME%\bin
%SPARK_HOME%\sbin
%HADOOP_HOME%\bin 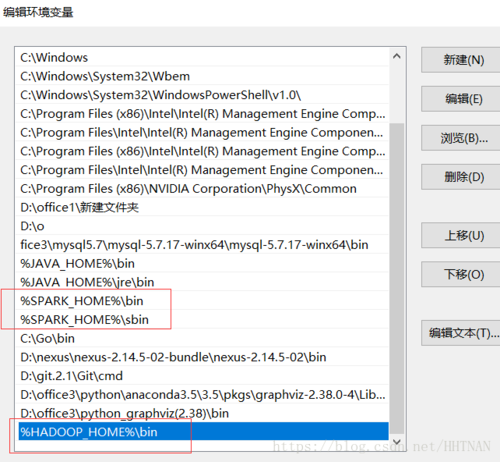
4 配置日志显示级别(可省略)
选择…\spark\conf\目录下log4j.properties.template,复制为log4j.properties
将log4j.properties中,”INFO, console”改为”WARN, console”
5【将pyspark文件放到python文件夹下、使用winutils.exe修改权限】
1,将spark所在目录下(比如我的是D:\Software\spark-2.2.0-bin-hadoop2.7\python)的pyspark文件夹拷贝到python文件夹下(我的是D:\Program Files\python3.5.3\Lib\site-packages)
具体目录要看大家自己安装的时候是放在哪的!
2,安装py4j库
一般的在cmd命令行下 pip install py4j 就可以。若是没有将pip路径添加到path中,就将路径切换到python的Scripts中,然后再 pip install py4j 来安装库。
3,修改权限
将winutils.exe文件放到Hadoop的bin目录下(我的是D:\Software\hadoop-2.7.3\bin),然后以管理员的身份打开cmd,然后通过cd命令进入到Hadoop的bin目录下,然后执行以下命令:
winutils.exe chmod 777 c:\tmp\Hive
注意:1,cmd一定要在管理员模式下!cmd一定要在管理员模式下!cmd一定要在管理员模式下!
2,‘C:\tmp\hive’,一般按照上面步骤进行了之后会自动创建的,一般是在Hadoop的安装目录下出现。但是若没有也不用担心,自己在c盘下创建一个也行。
关闭命令行窗口,重新打开命令行窗口,输入命令:pyspark
配置python 3
在D:\spark\spark-2.2.0-bin-hadoop2.7\bin中找到pyspark文件,采用notepad打开,并在其中增加
export PYSPARK_PYTHON
改为
export PYSPARK_PYTHON3
再次打开bin/pyspark即配置完成pyspark采用python3 
通过以上操作完成.
下面来测试
from pyspark import SparkContextfrom pyspark import SparkContext as scfrom pyspark import SparkConf
conf=SparkConf().setAppName("miniProject").setMaster("local[*]")
sc=SparkContext.getOrCreate(conf)
rdd = sc.parallelize([1,2,3,4,5])
rdd
print(rdd)
print(rdd.getNumPartitions() )输出结果:
ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:4808
共同学习,写下你的评论
评论加载中...
作者其他优质文章



