
Doc2Vec 原理:
Doc2Vec 或者叫做 paragraph2vec, sentence embeddings,是一种非监督式算法,可以获得sentences/paragraphs/documents 的向量表达,是 word2vec 的拓展。学出来的向量可以通过计算距离来找 sentences/paragraphs/documents 之间的相似性, 或者进一步可以给文档打标签。
例如首先是找到一个向量可以代表文档的意思,
然后可以将向量投入到监督式机器学习算法中得到文档的标签, 例如在**情感分析 **sentiment analysis 任务中,标签可以是 “negative”, “neutral”,”positive”
两种实现方法
2013 年 Mikolov 提出了 word2vec 来学习单词的向量表示,
主要有两种方法,cbow ( continuous bag of words) 和 skip-gram , 一个是用语境来预测目标单词,另一个是用中心单词来预测语境。
既然可以将 word 表示成向量形式,那么句子/段落/文档是否也可以只用一个向量表示?
一种方式是可以先得到 word 的向量表示,然后用一个简单的平均来代表文档。 另外就是 Mikolov 在 2014 提出的 Doc2Vec。
Doc2Vec 也有两种方法来实现。
dbow (distributed bag of words)
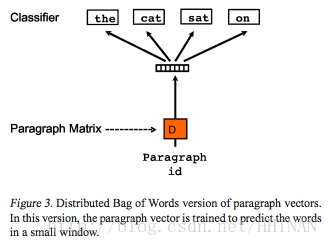
python gensim 实现:
model = gensim.models.Doc2Vec(documents,dm = 0, alpha=0.1, size= 20, min_alpha=0.025)
dm (distributed memory) 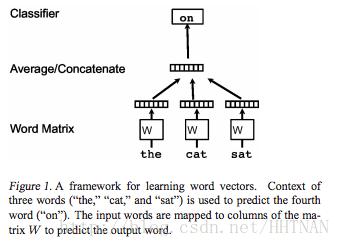
gensim 实现:
model = gensim.models.Doc2Vec(documents,dm = 1, alpha=0.1, size= 20, min_alpha=0.025)
二者在 gensim 实现时的区别是 dm = 0 还是 1.
Doc2Vec 的目的是获得文档的一个固定长度的向量表达。
数据:多个文档,以及它们的标签,可以用标题作为标签。
影响模型准确率的因素:语料的大小,文档的数量,越多越高;文档的相似性,越相似越好。
这里要用到 Gensim 的 Doc2Vec:
import gensim
LabeledSentence = gensim.models.doc2vec.LabeledSentence
先把所有文档的路径存进一个 array 中,docLabels:from os import listdirfrom os.path import isfile, join
docLabels = []
docLabels = [f for f in listdir("myDirPath") if f.endswith('.txt')]把所有文档的内容存入到 data 中:
data = []for doc in docLabels: data.append(open(“myDirPath/” + doc, ‘r’)
接下来准备数据,
如果是用句子集合来训练模型,则可以用:
class LabeledLineSentence(object): def __init__(self, filename): self.filename = filename def __iter__(self): for uid, line in enumerate(open(filename)): yield LabeledSentence(words=line.split(), labels=[‘SENT_%s’ % uid])
如果是用文档集合来训练模型,则用:
class LabeledLineSentence(object): def __init__(self, doc_list, labels_list): self.labels_list = labels_list self.doc_list = doc_list def __iter__(self): for idx, doc in enumerate(self.doc_list): yield LabeledSentence(words=doc.split(),labels=[self.labels_list[idx]])
在 gensim 中模型是以单词为单位训练的,所以不管是句子还是文档都分解成单词。
训练模型:
将 data, docLabels 传入到 LabeledLineSentence 中,
训练 Doc2Vec,并保存模型:
it = LabeledLineSentence(data, docLabels) model = gensim.models.Doc2Vec(size=300, window=10, min_count=5, workers=11,alpha=0.025, min_alpha=0.025) model.build_vocab(it) for epoch in range(10): model.train(it) model.alpha -= 0.002 # decrease the learning rate model.min_alpha = model.alpha # fix the learning rate, no deca model.train(it) model.save(“doc2vec.model”)
测试模型:
Gensim 中有内置的 most_similar:
print model.most_similar(“documentFileNameInYourDataFolder”)
输出向量:
model[“documentFileNameInYourDataFolder”]
得到向量后,可以计算相似性,输入给机器学习算法做情感分类等任务了。
附相关名词解释:
训练集:学习样本数据集,通过匹配一些参数来建立一个分类器。建立一种分类的方式,主要是用来训练模型的。
验证集:对学习出来的模型,微调分类器的参数,如在神经网络中选择隐藏单元数。验证集还用来确定网络结构或者控制模型复杂程度的参数。
测试集:主要用于测试训练好的模型的分类能力(识别率等)
显然,training set是用来训练模型或确定模型参数的,如ANN中权值等; validation set是用来做模型选择(model selection),即做模型的最终优化及确定的,如ANN的结构;而 test set则纯粹是为了测试已经训练好的模型的推广能力。
但实际应用中,一般只将数据集分成两类,即training set 和test set,大多数文章并不涉及validation set。
参考文献:https://radimrehurek.com/gensim/models/word2vec.html
增量训练:https://blog.csdn.net/sinat_26917383/article/details/69803018
参考文献:https://radimrehurek.com/gensim/models/keyedvectors.html
CBOW与Skip-Gram用于神经网络语言模型
在word2vec出现之前,已经有用神经网络DNN来用训练词向量进而处理词与词之间的关系了。采用的方法一般是一个三层的神经网络结构(当然也可以多层),分为输入层,隐藏层和输出层(softmax层)。
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。
CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。比如下面这段话,我们的上下文大小取值为4,特定的这个词是”Learning”,也就是我们需要的输出词向量,上下文对应的词有8个,前后各4个,这8个词是我们模型的输入。由于CBOW使用的是词袋模型,因此这8个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。 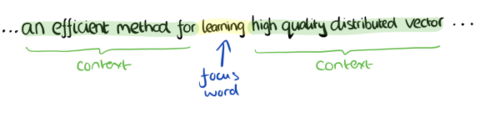
这样我们这个CBOW的例子里,我们的输入是8个词向量,输出是所有词的softmax概率(训练的目标是期望训练样本特定词对应的softmax概率最大),对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可。
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。还是上面的例子,我们的上下文大小取值为4, 特定的这个词”Learning”是我们的输入,而这8个上下文词是我们的输出。
这样我们这个Skip-Gram的例子里,我们的输入是特定词, 输出是softmax概率排前8的8个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某1个词对应的最可能的8个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前8的softmax概率对应的神经元所对应的词即可。
以上就是神经网络语言模型中如何用CBOW与Skip-Gram来训练模型与得到词向量的大概过程。但是这和word2vec中用CBOW与Skip-Gram来训练模型与得到词向量的过程有很多的不同。
word2vec为什么 不用现成的DNN模型,要继续优化出新方法呢?最主要的问题是DNN模型的这个处理过程非常耗时。我们的词汇表一般在百万级别以上,这意味着我们DNN的输出层需要进行softmax计算各个词的输出概率的的计算量很大。有没有简化一点点的方法呢?
word2vec基础之霍夫曼树
可以直接参考:(https://blog.csdn.net/hhtnan/article/details/80732057)
word2vec也使用了CBOW与Skip-Gram来训练模型与得到词向量,但是并没有使用传统的DNN模型。最先优化使用的数据结构是用霍夫曼树来代替隐藏层和输出层的神经元,霍夫曼树的叶子节点起到输出层神经元的作用,叶子节点的个数即为词汇表的小大。 而内部节点则起到隐藏层神经元的作用。
具体如何用霍夫曼树来进行CBOW和Skip-Gram的训练我们在下一节讲,这里我们先复习下霍夫曼树。
霍夫曼树的建立其实并不难,过程如下:
输入:权值为(w1,w2,…wn)(w1,w2,…wn)的nn个节点
输出:对应的霍夫曼树
1)将(w1,w2,…wn)(w1,w2,…wn)看做是有nn棵树的森林,每个树仅有一个节点。
2)在森林中选择根节点权值最小的两棵树进行合并,得到一个新的树,这两颗树分布作为新树的左右子树。新树的根节点权重为左右子树的根节点权重之和。
3) 将之前的根节点权值最小的两棵树从森林删除,并把新树加入森林。
4)重复步骤2)和3)直到森林里只有一棵树为止。
下面我们用一个具体的例子来说明霍夫曼树建立的过程,我们有(a,b,c,d,e,f)共6个节点,节点的权值分布是(16,4,8,6,20,3)。
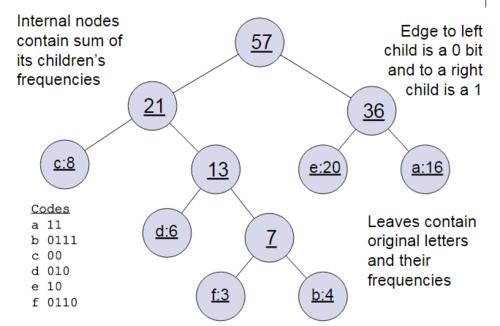
那么霍夫曼树有什么好处呢?一般得到霍夫曼树后我们会对叶子节点进行霍夫曼编码,由于权重高的叶子节点越靠近根节点,而权重低的叶子节点会远离根节点,这样我们的高权重节点编码值较短,而低权重值编码值较长。这保证的树的带权路径最短,也符合我们的信息论,即我们希望越常用的词拥有更短的编码。如何编码呢?一般对于一个霍夫曼树的节点(根节点除外),可以约定左子树编码为0,右子树编码为1.如上图,则可以得到c的编码是00。
在word2vec中,约定编码方式和上面的例子相反,即约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。
word2vec参数
Hierarchical Softmax与Negative Sampling
共同学习,写下你的评论
评论加载中...
作者其他优质文章



