
Negative Sampling 模型的CBOW和Skip-gram的原理。它相对于Hierarchical softmax 模型来说,不再采用huffman树,这样可以大幅提高性能。
一、Negative Sampling
在负采样中,对于给定的词w,如何生成它的负采样集合NEG(w)呢?已知一个词w,它的上下文是context(w),那么词w就是一个正例,其他词就是一个负例。但是负例样本太多了,我们怎么去选取呢?在语料库C中,各个词出现的频率是不一样的,我们采样的时候要求高频词选中的概率较大,而低频词选中的概率较小。这就是一个带权采样的问题。设词典D中的每一个词w对应线段的一个长度:
任何采样算法都应该保证频次越高的样本越容易被采样出来。基本的思路是对于长度为1的线段,根据词语的词频将其公平地分配给每个词语: 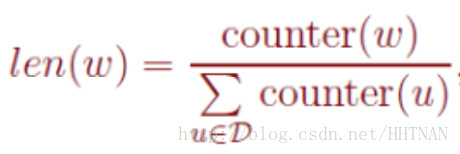
counter就是w的词频。
于是我们将该线段公平地分配了: 
接下来我们只要生成一个0-1之间的随机数,看看落到哪个区间,就能采样到该区间对应的单词了,很公平。
但怎么根据小数找区间呢?速度慢可不行。
word2vec用的是一种查表的方式,将上述线段标上M个“刻度”,刻度之间的间隔是相等的,即1/M: 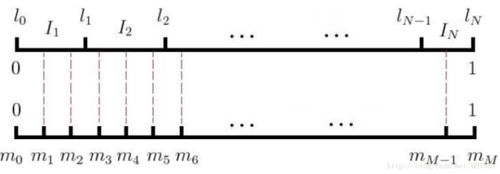
接着我们就不生成0-1之间的随机数了,我们生成0-M之间的整数,去这个刻度尺上一查就能抽中一个单词了。
在word2vec中,该“刻度尺”对应着table数组。具体实现时,对词频取了0.75次幂:
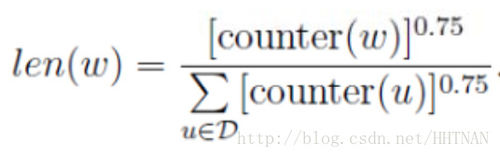
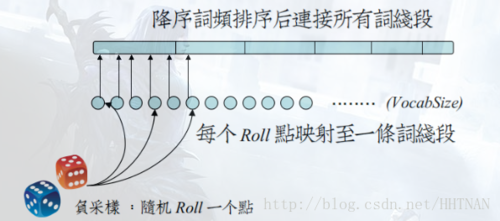
这个幂实际上是一种“平滑”策略,能够让低频词多一些出场机会,高频词贡献一些出场机会,劫富济贫。
二、CBOW



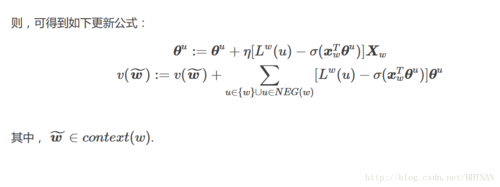
三、损失函数
NCE损失函数表示如下:
Jθ=−∑w∈V(logP(y=1|x)+∑i=1klogP(y=0|x(w(i))))Jθ=−∑w∈V(logP(y=1|x)+∑i=1klogP(y=0|x(w(i))))
该损失函数计算上下文与目标单词之间的点积,采集每一个正样本的同时采集k个负样本。公式的第一项最小化正样本的损失,第二项最大化负样本的损失。现在如果将负样本作为第一项的变量输入,则损失函数结果应该很大。
参考文献:
http://www.cnblogs.com/neopenx/p/4571996.html
共同学习,写下你的评论
评论加载中...
作者其他优质文章



