
一.安装
目前用了tensorflow、deeplearning4j两个深度学习框架,
tensorflow 之前一直支持到python 3.5,目前以更新到3.6,故安装最新版体验使用。
慢慢长征路:安装过程如下
WIN10:
anaconda3.5:
PYTHON3.6:
tensorflow1.4: 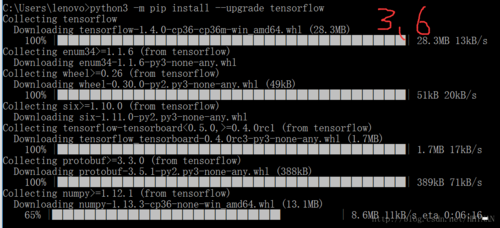
二.TensorFlow 基本概念与原理理解
1.TensorFlow 的工作原理
TensorFlow是用数据流图(data flow graphs)技术来进行数值计算的。数据流图是描述有向图中的数值计算过程。
有向图中,节点通常代表数学运算,边表示节点之间的某种联系,它负责传输多维数据(Tensors)。
节点可以被分配到多个计算设备上,可以异步和并行地执行操作。因为是有向图,所以只有等到之前的入度节点们的计算状态完成后,当前节点才能执行操作。 
2.TensorFlow 基本用法
接下来按照官方文档中的具体代码,来看一下基本用法。你需要理解在TensorFlow中,是如何:
5步:
一.将计算流程表示成图;
二.通过Sessions来执行图计算;
三将数据表示为tensors;
四 使用Variables来保持状态信息;
五 分别使用feeds和fetches来填充数据和抓取任意的操作结果
使用TensorFlow,你必须明白TensorFlow: 使用图(graph)来表示任务 被称之为会话(Session)的上下文(context)中执行图 使用tensor表示数据 通过变量(Variable)维护状态 使用feed和fetch可以为任意操作(arbitrary operation)赋值或者从其中获取数据 例1,生成三维数据,然后用一个平面拟合它:
以下是官网的操作案例
import tensorflow as tf import numpy as np # 用 NumPy 随机生成 100 个数据 x_data = np.float32(np.random.rand(2, 100)) y_data = np.dot([0.100, 0.200], x_data) + 0.300# 构造一个线性模型 b = tf.Variable(tf.zeros([1])) W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0)) y = tf.matmul(W, x_data) + b # 最小化方差 loss = tf.reduce_mean(tf.square(y - y_data)) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(loss) # 初始化变量 init = tf.global_variables_initializer() #官网是tf.initialize_all_variables() 该函数将不再使用,在 2017年#3月2号以后;用 tf.global_variables_initializer() 替代 #tf.initialize_all_variables() # 启动图 (graph) sess = tf.Session() sess.run(init) # 拟合平面for step in xrange(0, 201): sess.run(train) if step % 20 == 0: print step, sess.run(W), sess.run(b) # 输出结果为:0 [[-0.14751725 0.75113136]] [ 0.2857058]20 [[ 0.06342752 0.32736415]] [ 0.24482927]40 [[ 0.10146417 0.23744738]] [ 0.27712563]60 [[ 0.10354312 0.21220125]] [ 0.290878]80 [[ 0.10193551 0.20427427]] [ 0.2964265]100 [[ 0.10085492 0.201565 ]] [ 0.298612]120 [[ 0.10035028 0.20058727]] [ 0.29946309]140 [[ 0.10013894 0.20022322]] [ 0.29979277]160 [[ 0.1000543 0.20008542]] [ 0.29992008]180 [[ 0.10002106 0.20003279]] [ 0.29996923]200 [[ 0.10000814 0.20001261]] [ 0.29998815]
注意以下几条代码,即前面说的主要流程5步:
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0))y = tf.matmul(W, x_data) + b init = tf.initialize_all_variables() sess = tf.Session() sess.run(init) sess.run(train) print step, sess.run(W), sess.run(b)
接下来看具体概念:
TensorFlow 用图来表示计算任务,图中的节点被称之为operation,缩写成op。
一个节点获得 0 个或者多个张量 tensor,执行计算,产生0个或多个张量。
图必须在会话(Session)里被启动,会话(Session)将图的op分发到CPU或GPU之类的设备上,同时提供执行op的方法,这些方法执行后,将产生的张量(tensor)返回。
构建图
例2,计算矩阵相乘:
import tensorflow as tf # 创建一个 常量 op, 返回值 'matrix1' 代表这个 1x2 矩阵. matrix1 = tf.constant([[3., 3.]]) # 创建另外一个 常量 op, 返回值 'matrix2' 代表这个 2x1 矩阵. matrix2 = tf.constant([[2.],[2.]]) # 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入. # 返回值 'product' 代表矩阵乘法的结果. product = tf.matmul(matrix1, matrix2)
默认图有三个节点, 两个 constant() op, 和一个 matmul() op. 为了真正进行矩阵相乘运算, 并得到矩阵乘法的结果, 你必须在会话里启动这个图.
张量 Tensor
从向量空间到实数域的多重线性映射(multilinear maps)(v是向量空间,v*是对偶空间)
你可以把Tensorflow的tensor看做是一个n维的数组或列表。一个tensor包含一个静态类型rank和一个shape。
阶
在Tensorflow系统中,张量的维数被描述为阶。但是张量的阶和矩阵的阶并不是同一个概念。张量的阶是张量维数的一个数量描述,下面的张量(使用python中list定义的)就是2阶:
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
你可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量。对于一个二阶张量,你可以使用语句t[i, j]来访问其中的任何元素。而对于三阶张量你可以通过t[i, j, k]来访问任何元素: 
形状
Tensorflow文档中使用了三种记号来方便地描述张量的维度:阶,形状以及维数。以下展示了它们之间的关系: 
数据类型
除了维度,tensor有一个数据类型属性。你可以为一个张量指定下列数据类型中的任意一个类型: 
在一个会话中启动图
创建一个 Session 对象, 如果无任何创建参数, 会话构造器将启动默认图。
会话负责传递 op 所需的全部输入,op 通常是并发执行的。
# 启动默认图. sess = tf.Session() # 调用 sess 的 'run()' 方法, 传入 'product' 作为该方法的参数, # 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op), # 向方法表明, 我们希望取回矩阵乘法 op 的输出. result = sess.run(product) # 返回值 'result' 是一个 numpy `ndarray` 对象.print result # ==> [[ 12.]]# 任务完成, 需要关闭会话以释放资源。 sess.close() 交互式使用 在 Python API 中,使用一个会话 Session 来 启动图, 并调用 Session.run() 方法执行操作. 为了便于在 IPython 等交互环境使用 TensorFlow,需要用 InteractiveSession 代替 Session 类, 使用 Tensor.eval() 和 Operation.run() 方法代替 Session.run()。
例3,计算 ‘x’ 减去 ‘a’:
# 进入一个交互式 TensorFlow 会话.import tensorflow as tf sess = tf.InteractiveSession()x = tf.Variable([1.0, 2.0]) a = tf.constant([3.0, 3.0])# 使用初始化器 initializer op 的 run() 方法初始化 'x' x.initializer.run()# 增加一个减法 sub op, 从 'x' 减去 'a'. 运行减法 op, 输出结果 sub = tf.sub(x, a) print sub.eval()# ==> [-2. -1.]变量 Variable 上面用到的张量是常值张量(constant)。
变量 Variable,是维护图执行过程中的状态信息的. 需要它来保持和更新参数值,是需要动态调整的。
下面代码中有 tf.initialize_all_variables,是预先对变量初始化,
Tensorflow 的变量必须先初始化,然后才有值!而常值张量是不需要的。
下面的 assign() 操作和 add() 操作,在调用 run() 之前, 它并不会真正执行赋值和加和操作。
例4,使用变量实现一个简单的计数器:
# -创建一个变量, 初始化为标量 0. 初始化定义初值state = tf.Variable(0, name="counter")# 创建一个 op, 其作用是使 state 增加 1one = tf.constant(1) new_value = tf.add(state, one) update = tf.assign(state, new_value)# 启动图后, 变量必须先经过`初始化` (init) op 初始化,# 才真正通过Tensorflow的initialize_all_variables对这些变量赋初值init_op = tf.initialize_all_variables()# 启动默认图, 运行 opwith tf.Session() as sess: # 运行 'init' op sess.run(init_op) # 打印 'state' 的初始值 # 取回操作的输出内容, 可以在使用 Session 对象的 run() 调用 执行图时, # 传入一些 tensor, 这些 tensor 会帮助你取回结果. # 此处只取回了单个节点 state, # 也可以在运行一次 op 时一起取回多个 tensor: # result = sess.run([mul, intermed]) print sess.run(state) # 运行 op, 更新 'state', 并打印 'state' for _ in range(3): sess.run(update) print sess.run(state)# 输出:# 0# 1# 2# 3
上面的代码定义了一个如下的计算图:
Ok,总结一下,来一个清晰的代码:
过程就是:建图->启动图->运行取值
计算矩阵相乘:
import tensorflow as tf # 建图 matrix1 = tf.constant([[3., 3.]]) matrix2 = tf.constant([[2.],[2.]]) product = tf.matmul(matrix1, matrix2) # 启动图 sess = tf.Session() # 取值 result = sess.run(product)print result sess.close()
上面的几个代码介绍了基本用法,通过观察,有没有觉得 tf 和 numpy 有点像呢。
TensorFlow和普通的Numpy的对比,来看一下二者之间的区别: 
eval()
在 Python 中定义完 a 后,直接打印就可以看到 a。
In [37]: a = np.zeros((2,2)) In [39]: print(a)[[ 0. 0.] [ 0. 0.]]
但是在 Tensorflow 中需要显式地输出(evaluation,也就是说借助eval()函数)!
In [38]: ta = tf.zeros((2,2))
In [40]: print(ta)
Tensor("zeros_1:0", shape=(2, 2), dtype=float32)
In [41]: print(ta.eval())[[ 0. 0.]
[ 0. 0.]]共同学习,写下你的评论
评论加载中...
作者其他优质文章



