
本篇文章是使用 Python 抓取万家医疗上面的诊所信息,并且对关键信息进行分析,实现数据可视化。由于时间和能力的问题,能抓取的数据类型较少,分析的维度也不足。但是尝试去剖析在国家倡导分级诊疗的大环境下,移动医疗在社区诊所上的发展情况。所以抓取了万家医疗网站里面的诊所数据,并从诊所区域分布、科室类型以及是否支持医保上进行了数据分析和可视化。
<strong>准备工作</strong>
首先是开始抓取前准备工作,导入需要使用的库文件,爬虫主要使用的是requests和BeautifulSoup两个库,数据分析主要使用 Numpy 和 Pandas 两个库,外加 matplotlib 库实现数据可视化。
<pre>import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
</pre>
<strong>抓取诊所列表信息</strong>
在抓取前需要先观察下万家医疗诊所列表页面的的结构,URL为“"https://www.pinganwj.com/clinic/pa1”,其中 ”pg1”为页面数,共有846个页面,预计诊所有8460家左右,可以使用循环遍历所有的页面,获取信息。
<pre>#设置 url 的前面部分
url = "https://www.pinganwj.com/clinic/"
</pre>
确定了 URL 链接之后,还需要设置浏览器头部(headers)信息,否则系统会识别爬虫程序,从而阻止访问页面。
<pre>#设置url的前面部分
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Accept':'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, /; q=0.01',
'Accept-Charset':'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding':'utf-8',
'Connection':'keep-alive',
'Referer':'http://www.baidu.com/link?url=_andhfsjjjKRgEWkj7i9cFmYYGsisrnm2A-TN3XZDQXxvGsM9k9ZZSnikW2Yds4s&wd=&eqid=c3435a7d00006bd600000003582bfd1f'
}
</pre>
使用 for 循环生成 1-847 的数字,转化格式后与前面的 URL 固定部分拼成要抓取的 URL。这里我们设置每两个页面间隔 0.5 秒。抓取到的页面保存在 html 中。
<pre>#循环抓取列表页信息
for i in range(1,847):
if i == 1:
i=str(i)
a=(url+'pg'+i)
r=requests.get(url=a,headers=headers)
html=r.text
else:
i=str(i)
a=(url+'pg'+i)
r=requests.get(url=a,headers=headers)
html2=r.text
html = html + html2
#每次间隔0.5秒
time.sleep(0.5)
#在页面打印爬取进度
print ('正在爬取第'+i+"页")
</pre>

@爬取进度页面|center
<strong>解析页面并提取信息</strong>
页面爬取下来之后,需要使用 BeautifulSoup 对页面进行解析,变成我们在浏览器查看源代码中看到的样子,这样我们才能提取关键信息。
<pre>#使用 BeautifulSoup 解析抓取的页面内容
wj = BeautifulSoup(html,'html.parser')
</pre>
到目前为止,我们已经 800+ 多个页面的信息爬取下来,并且通过 BeautifulSoup 解释为我们常见的源代码方式。下面就是通过分析爬取字段中 <code>Div</code>的 id 或者 class 提取关键信息。
<pre>#将诊所列表中的信息保存在 hospital 中,其中 find_all 获取的是一个 list,就是每个诊所就是list上的一个对应元素。
hospital = wj.find_all('div',attrs = {"class":"cli-list left"})
</pre>
继续在<code>hospital</code>中提取诊所名称、医保信息、科室和地区信息,将各项信息存储到各自的<code>list</code>中。使用到的方法基本一样,需要自行调整一下定位就好。
<pre>#获取诊所名称
hn = []
for a in hospital:
hospital_name = a.h1.get_text()
hn.append(hosptal_name)
获取诊所医保信息
yb = []
for c in hospital:
yibao_info = c.find_all('span', attrs = {'class':'medicare'})
yibao = yibao_info
yb.append(yibao)
获取诊所科室
ks = []
for b in hospital:
keshi = b.p.get_text()
ks.append(keshi)
获取诊所地址
address = []
for d in hospital:
address_info = d.find_all('script')
address.append(address_info)
</pre>
<strong>数据分析和数据可视化</strong>
将拿到的数据使用 Pandas 库生成数据表,方便后面分析。
<pre>#将诊所名称、医保信息、科室和地区等信息生成数据表
hospital_list=pd.DataFrame({'hospital_name':hn,'hospital_keshi':ks,'hospital_yibao':yb,'hospital_address':address})
</pre>
<strong>诊所分布的省份分析:</strong>
通过使用 groupby 对诊所所在省份进行汇总,通过条形图展示每个省份的诊所数量。
<pre>#对每个省份的诊所数量进行汇总
prov = wj.groupby('hospital_address')['hospital_address'].agg('count')
对省份数据进行排序
prov.sort_values(inplace=True)
生成省份名称列表,下面用作坐标值
prov_name=prov.index
定义图表比例
plt.figure(figsize=(16,9))
定义图表类型并且传入参数
plt.barh(range(len(prov)),prov,tick_label=prov_name)
标注X轴的标签
plt.xlabel(u'诊所数量',fontsize ="14")
用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
plt.show()
</pre>
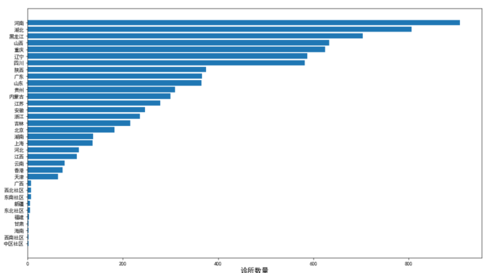
@诊所省份分布图
有上面的图片可以看出,河南、河北、黑龙江三个省份的诊所数量最多。可能的原因是万家医疗在不同省份推广资源的分配导致的。但是跟深层次的去考虑:为什么不是北京上海广东这些大城市呢?其实很好理解,北京、上海、广东可以说是中国医疗资源最密集的地方,但是这些地方都被大型三甲医院占据,民营的、小型的社区诊所要发展就比较困难。
<strong>诊所分布的科室类型分析:</strong>
使用相同的方式,对不同诊所的科室类型进行分析,分析方法和展示形式基本一样。但是需要强调的是,因为有的诊所拥有多个科室,所以对于这类诊所,我将它们定义为综合类型诊所。
<pre>#对各种科室的诊所数量进行汇总
keshi = wj.groupby("hospital_keshi")["hospital_keshi"].agg("count")
对科室类型数据进行排序
keshi.sort_values(inplace=True)
生成科室名称列表,下面用作坐标值
keshi_name=keshi.index
定义图表比例
plt.figure(figsize=(9,6))
定义图表类型并且传入参数
plt.barh(range(len(keshi)),keshi,tick_label=keshi_name)
标注X轴的标签
plt.xlabel(u'诊所数量',fontsize ="14")
用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
展示图表
plt.show()
</pre>
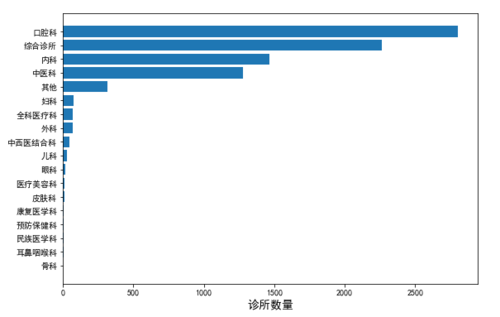
@诊所科室分布
从上面的图表可以看出,占比最大的诊所类型是口腔科类型的诊所,这些诊所大多是民营的,并且倾向私人经营较多。还有中医科主要就是一些私人开办的中医馆。
<strong>诊所是否支持医保:</strong>
对于社区诊所来说,患者还是比较看重是否支持医保支付的,所以医保信息也是相当关键。获取得到的医保数据中,支持医保的显示“是”,不支持医保的为空。统计医保支付的占比,并且制作称饼图。
<pre>#统计汇总医保数量
yibaoinfo = wj.groupby("hospital_yibao")["hospital_yibao"].agg("count")
计算支持医保和非医保数量
yibaoinfo = np.array([yibaoinfo.values,8460-yibaoinfo.values])
定义图表大小
plt.figure(figsize=(9,6))
定义标签值
labels = ['有医保', '无医保']
定义数据值的大小,获取上面的列表信息
size = [yibaoinfo[0],yibaoinfo[1]]
定义图表类型为饼图
plt.pie(size, labels=labels)
plt.axis('equal')
plt.show()
</pre>
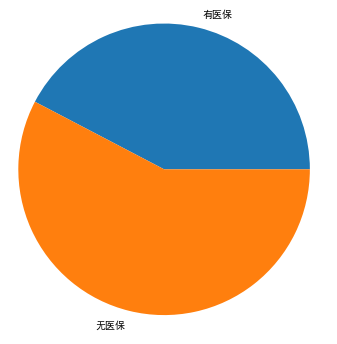
@是否支持医保分布|center
从上图可以看到,不到一半的诊所支持医保,也可能是网站信息更新不全,看来医保的路还要继续走呢。
以上就是万家医疗诊所信息爬取和分析的总过程,因为能力的原因,所以爬取数据的维度较少,代码质量和图表也是没有经过美化,显得稍微简陋了一些。如果后面有时间,还会分享更多关于移动医疗+爬虫+数据科学+数据可视化的文章,感谢大家多多关注。
本文为原创文章,如需转载请注明原文出处:<a href = "http://wp.me/p86ISR-gO">http://wp.me/p86ISR-gO</a>
共同学习,写下你的评论
评论加载中...
作者其他优质文章


