
作者:寒斜
DeepSeek R1 推理模型凭借其卓越性能,能够高效解决很多深度问题,然而,官方的服务的限流问题却在我们使用过程带来了诸多不便,导致我们的“使用焦虑”。那么,如何实现真正的 “满血、高速、不限流、超长上下文” 的运行效果呢?为此,我们特别推出本期教程,教您如何部署专属的 DS 服务,彻底摆脱限流困扰,不仅支持知识库的使用,还可以随时将知识库分享出去,为客服等业务场景提供强大助力。依托阿里云的强大算力,助力您轻松实现“DS 自由”。
本期教程将基于阿里云百炼和云应用开发平台(CAP),详细为您讲解专属满血 R1 模型的部署与调用方法,助力您开启高效 AI 推理之旅。
用途及价值
该方案的优势在于操作简便,即使是普通用户,也能通过应用模板一键完成部署,无需了解复杂的服务器操作流程。部署完成后,用户可结合自身需求,灵活接入个性化数据库,实现多样化应用场景。
例如,用户可以收集健康领域的专业书籍,将其录入知识库,进而搭建家庭医生智能助理,为家庭成员提供便捷的健康咨询与建议;又如,用户可以收集最新的行业动态信息,录入知识库后,结合微信机器人搭建行业资讯平台,实时掌握行业前沿动态;此外,用户还可借助该方案搭建专属的AI绘图工具,让AI根据需求绘制所需图像,助力创意表达与设计工作。
通过这一方案,用户能够快速构建个性化、智能化的应用场景,满足个人不同领域的多样化需求,实现高效、便捷的智能服务体验。
部署方案
部署架构
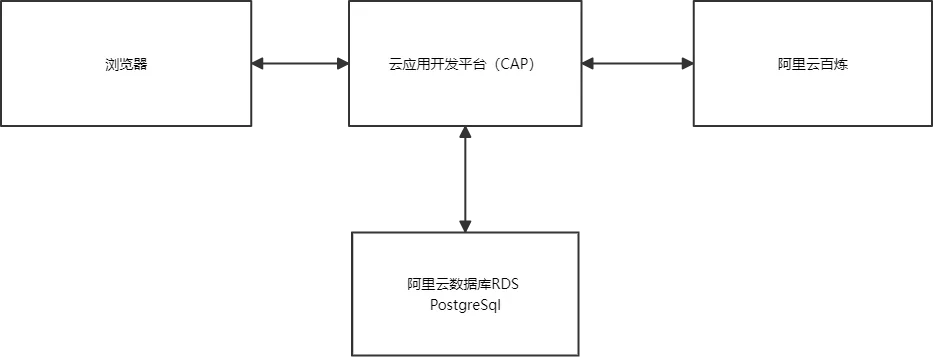
本次部署架构如下图,整个服务的关联上下游如图所示。使用的服务软件为 AgentCraft,AgentCraft 是一个 Serverless 架构的智能体平台,相比于 Dify,Coze 其优势在于高度 Serverless 化,真正的按需服务,完美兼容 Serverless Devs 的社区生态,可以复用 Serverless Devs 社区生态的应用及 AI 工具。更多介绍参考 AgentCraft 文档。
部署步骤
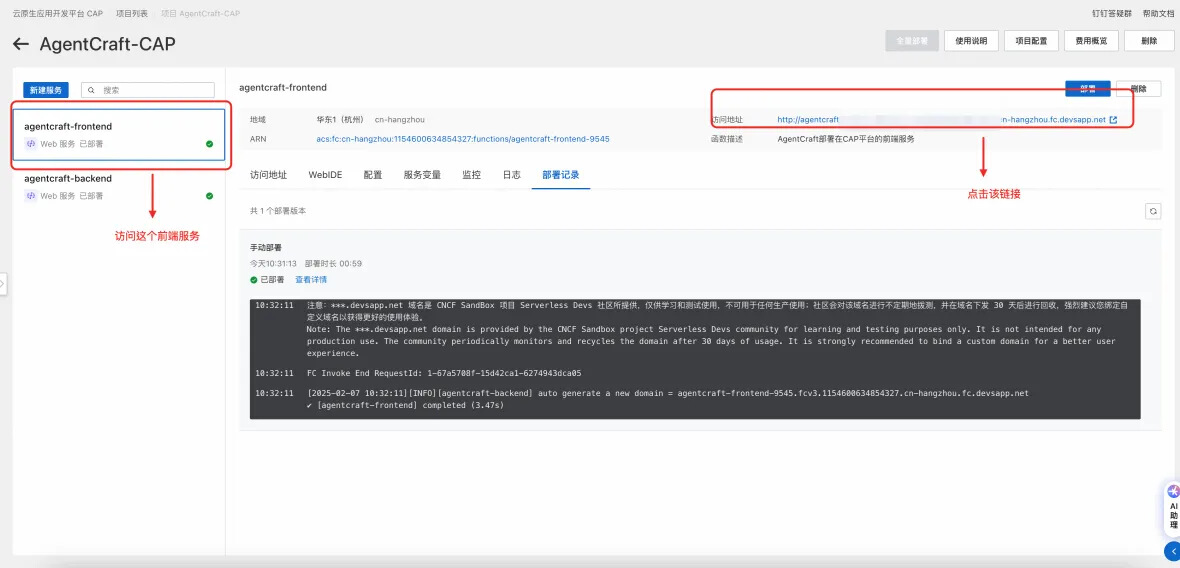
- 登录阿里云云应用开发平台 CAP,访问《智能体世界》应用:https://cap.console.aliyun.com/template-detail?template=AgentCraft-CAP
- 根据指引一键部署
- 打开服务

配置
AgentCraft 部署后需要进行简单配置,包含数据库(必填),向量模型(可跳过)。
配置步骤
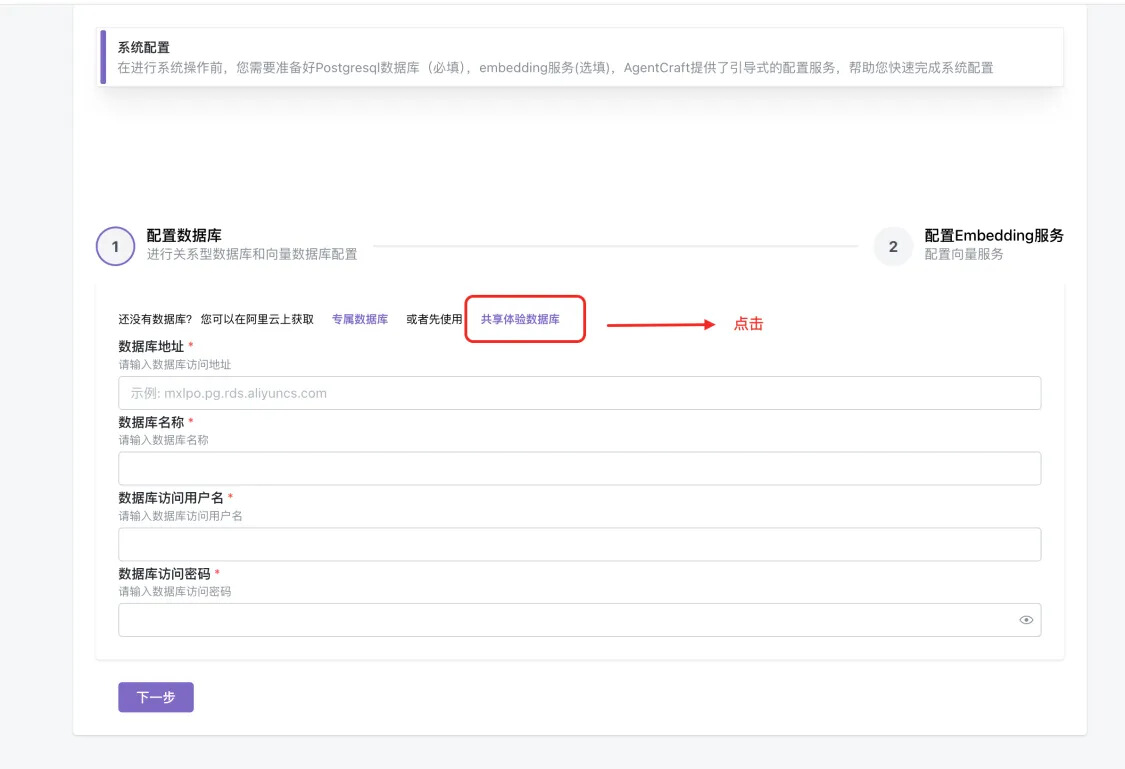
1.快速体验可以选择共享数据库,社区提供了一个独立数据库用于简单测试(测试完可以随时删除个人数据),强烈建议您使用自己的专属数据库,这样所有的数据都会由您专属管理,点击“专属数据库”可以查看指引。
2.部署向量模型,AgentCraft 采用的是 large-bge 向量模型,您可以在这里一键部署,如果不需要使用知识库检索能力,可以直接跳过。部署过程可以点击查看。
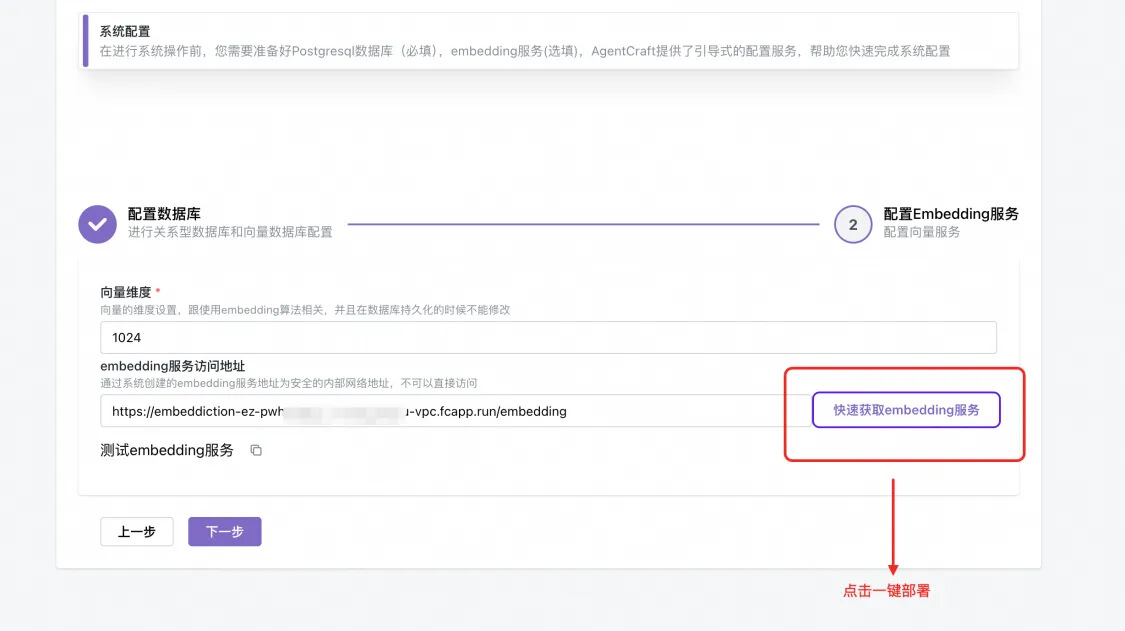
部署过程可以点击查看
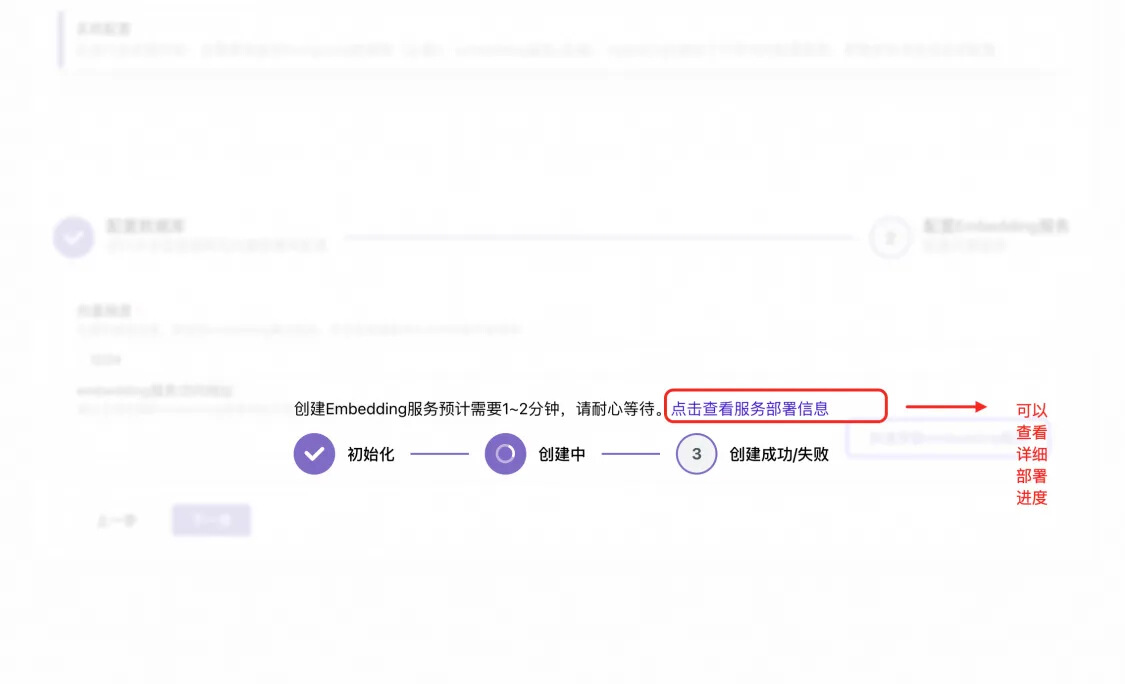
注: 使用子账号部署该模型服务的时候,可能会因为权限问题导致失败,此时可以先跳过该步骤,参考《更多补充说明》-向量模型单独部署配置
3.部署完成后,点击完成。
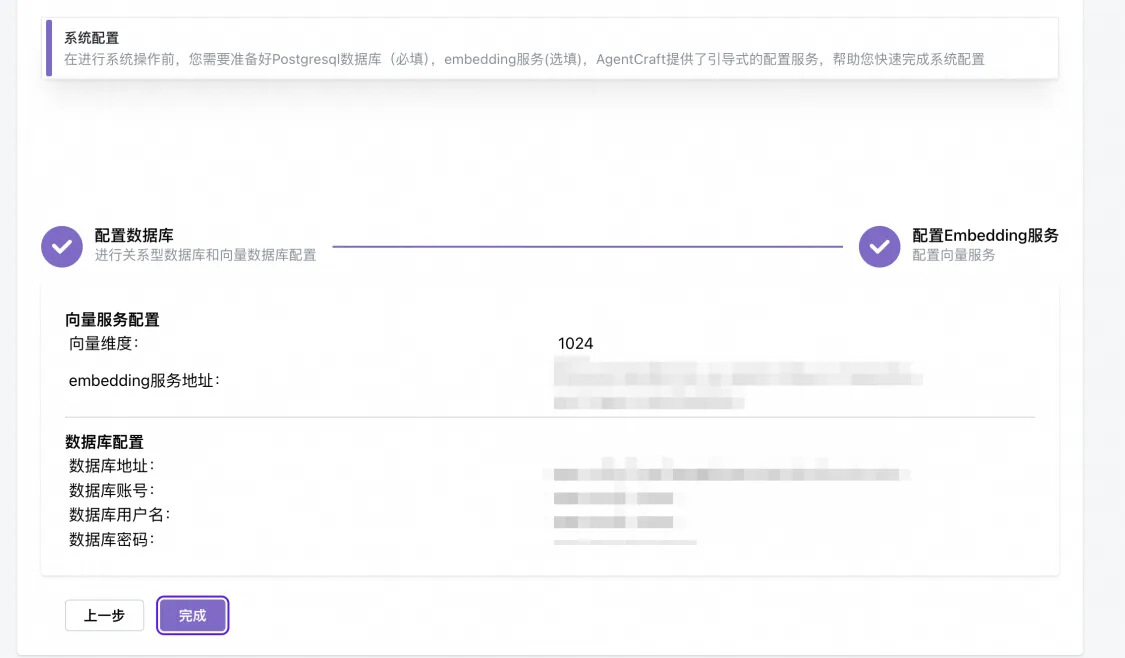
使用体验
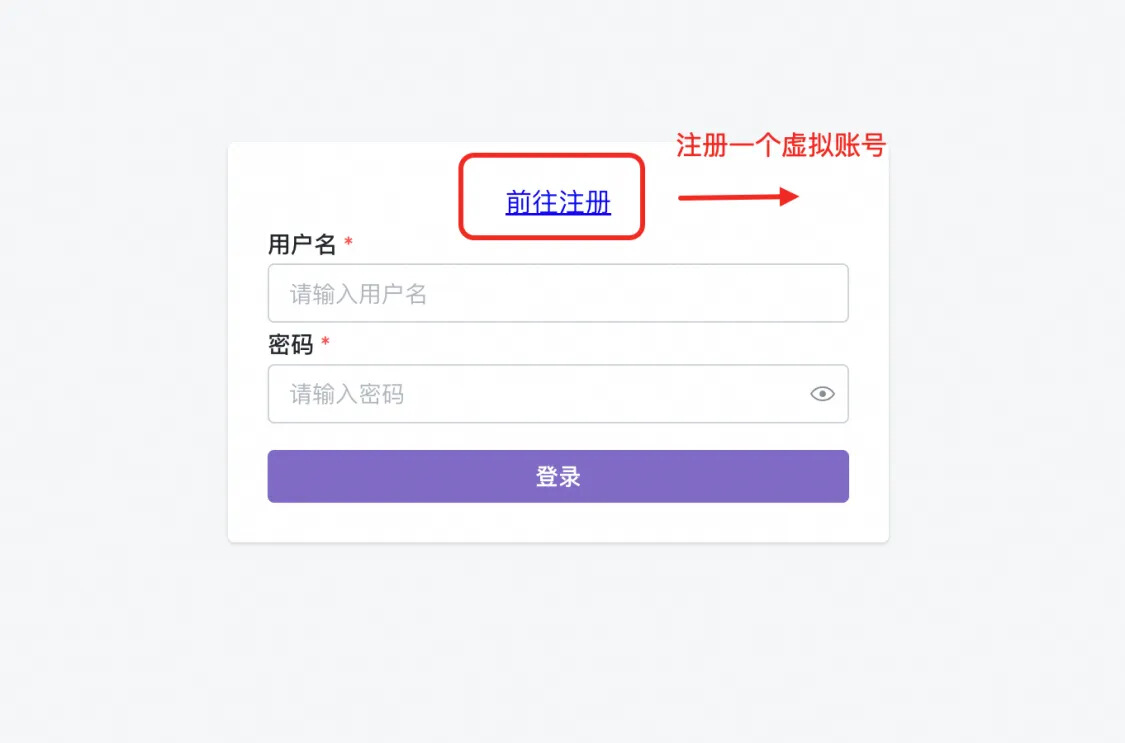
注册登录
- 注册一个虚拟账号(可以随时删除配置的资源),然后登录。
- 两步配置 DeepSeek 满血的模型服务以及创建体验智能体。
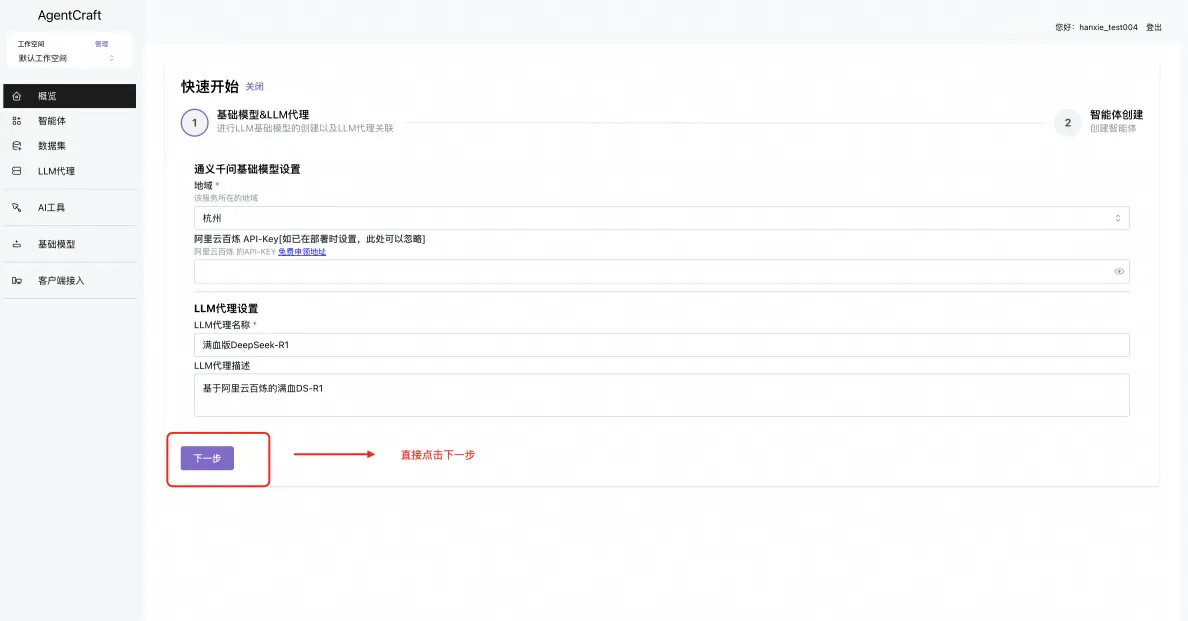
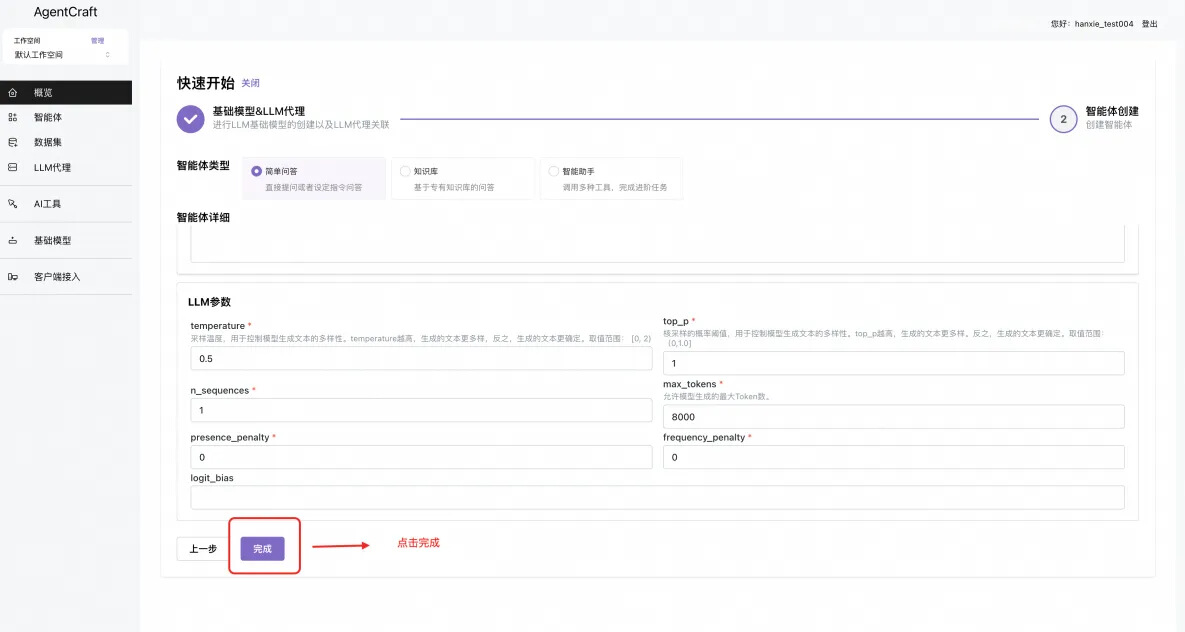
模型应用体验
对话及逻辑推理能力测试
对话设置
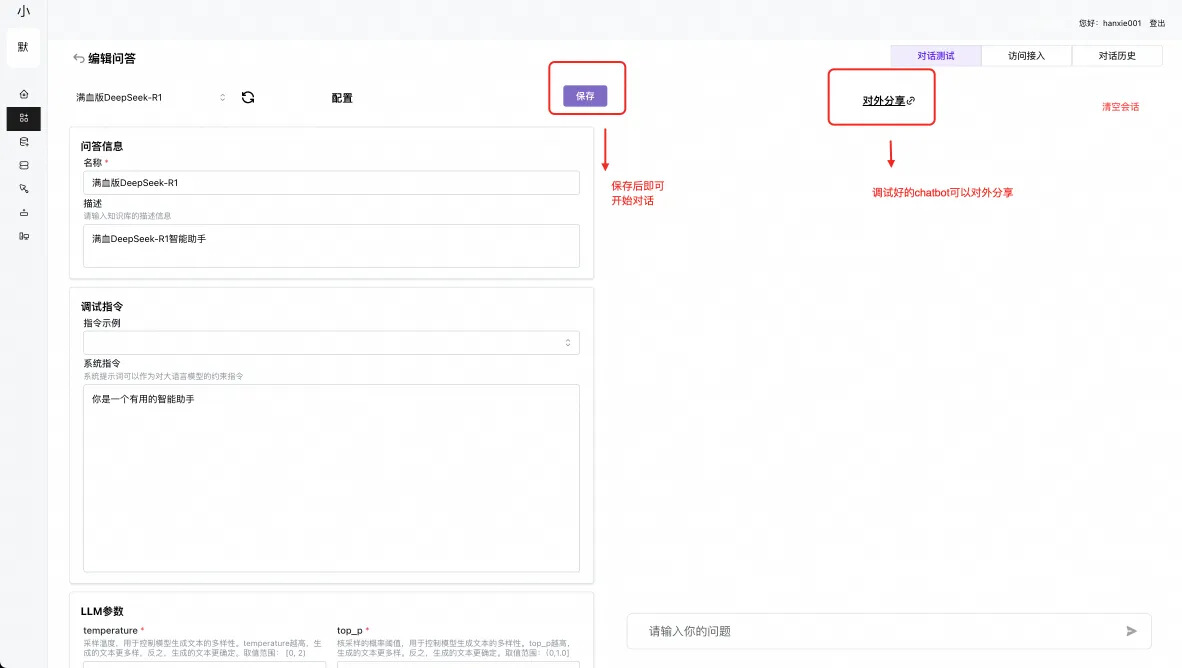
对话测试
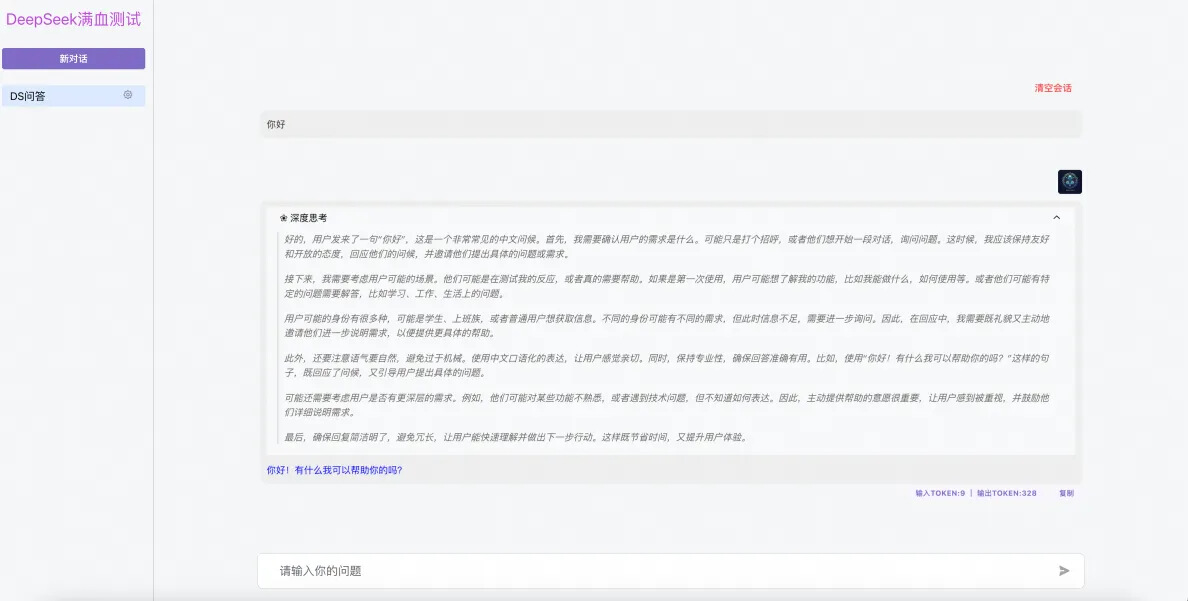
知识库能力测试
新建一个数据集(给模型的上下文参考)
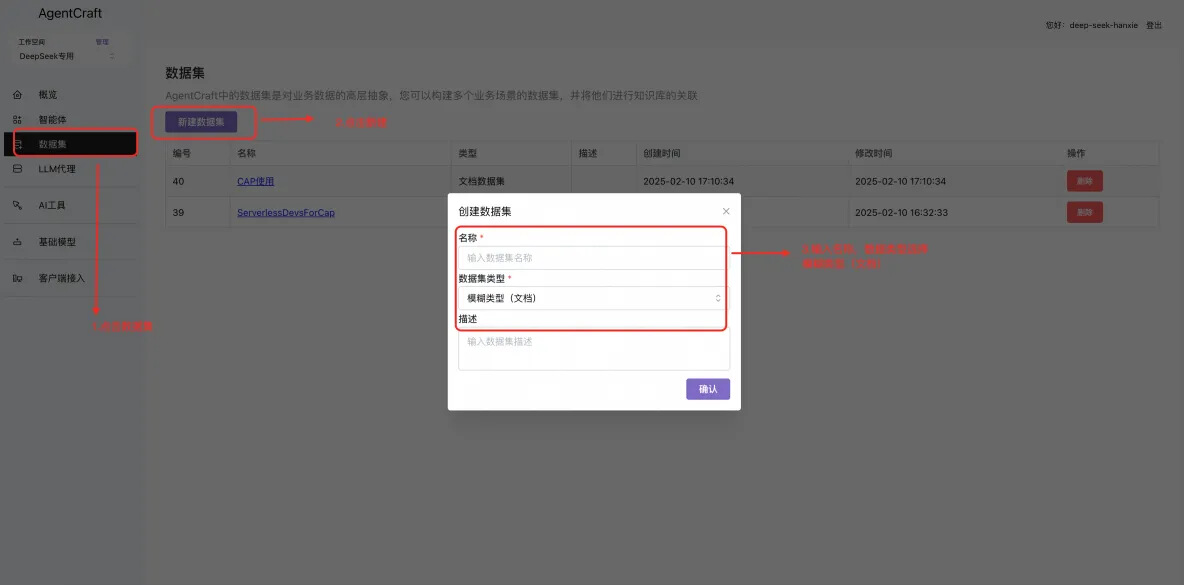
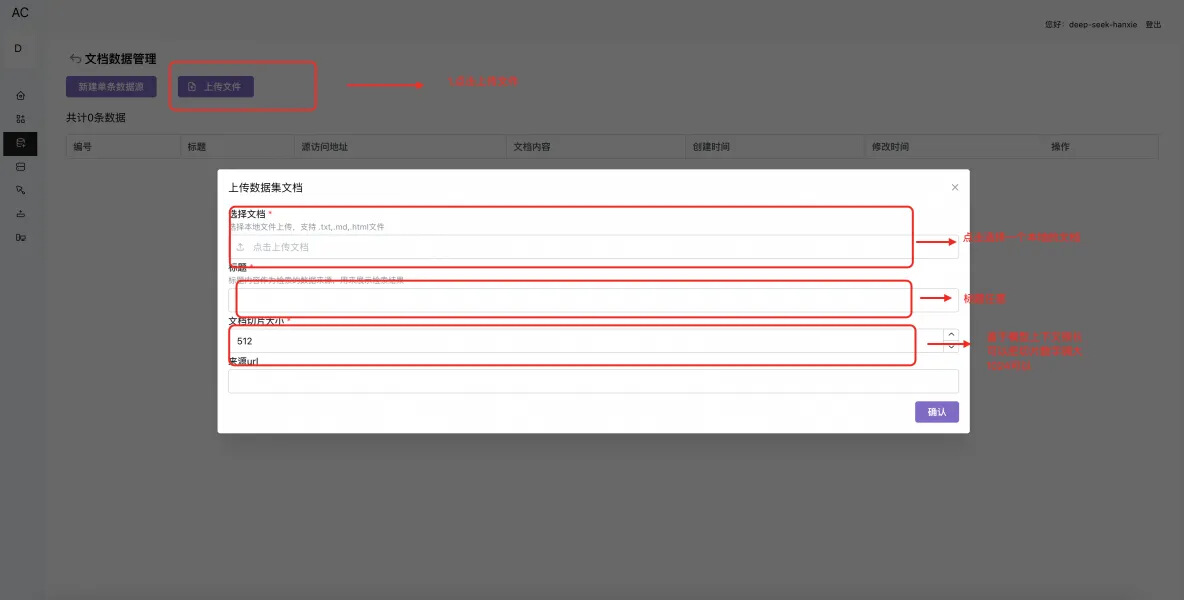
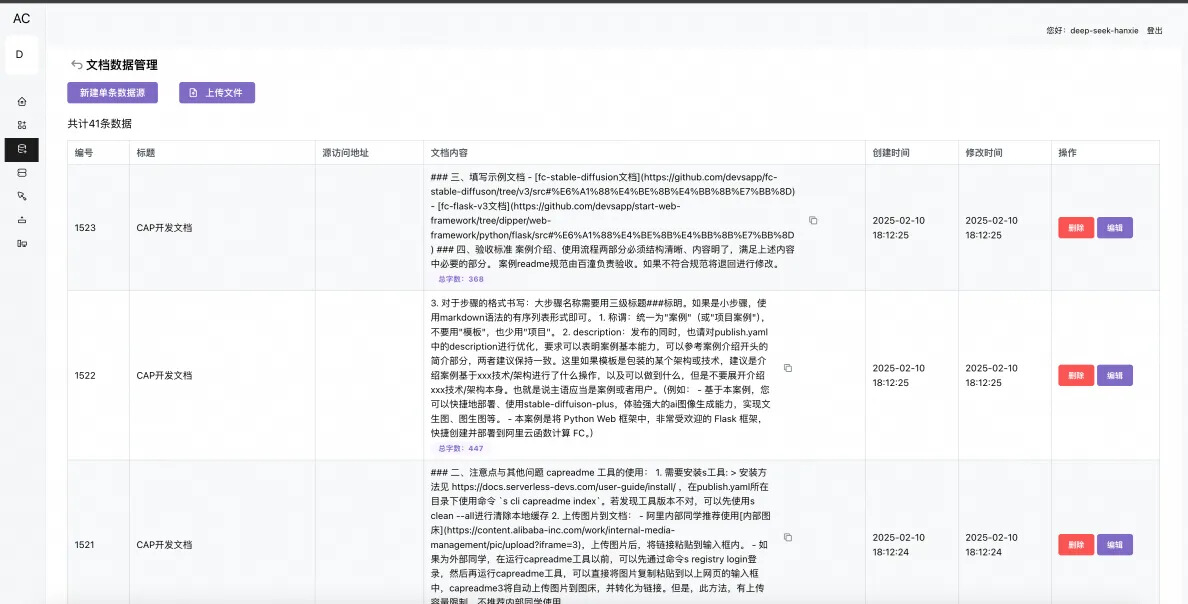
新建及配置知识库智能体
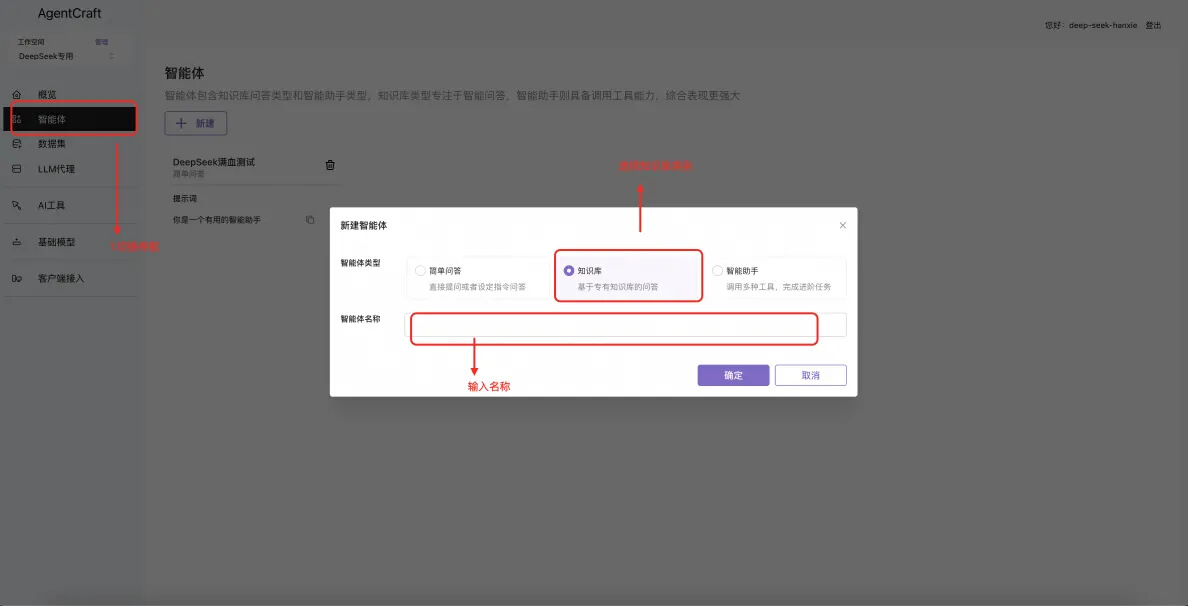
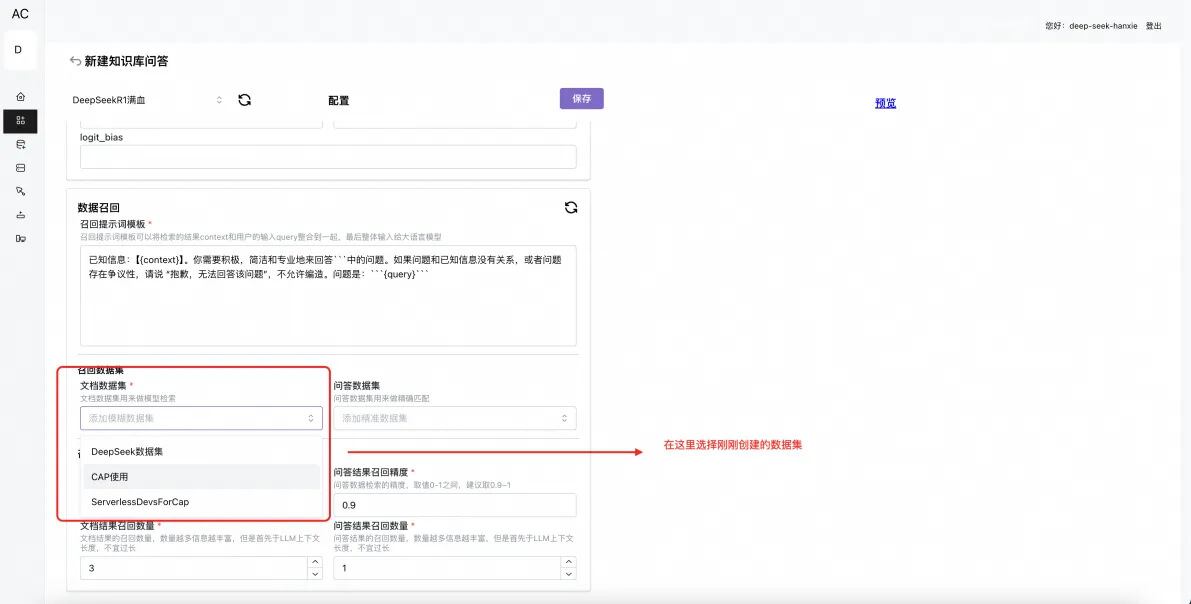
保存后点击右侧“预览”对话测试。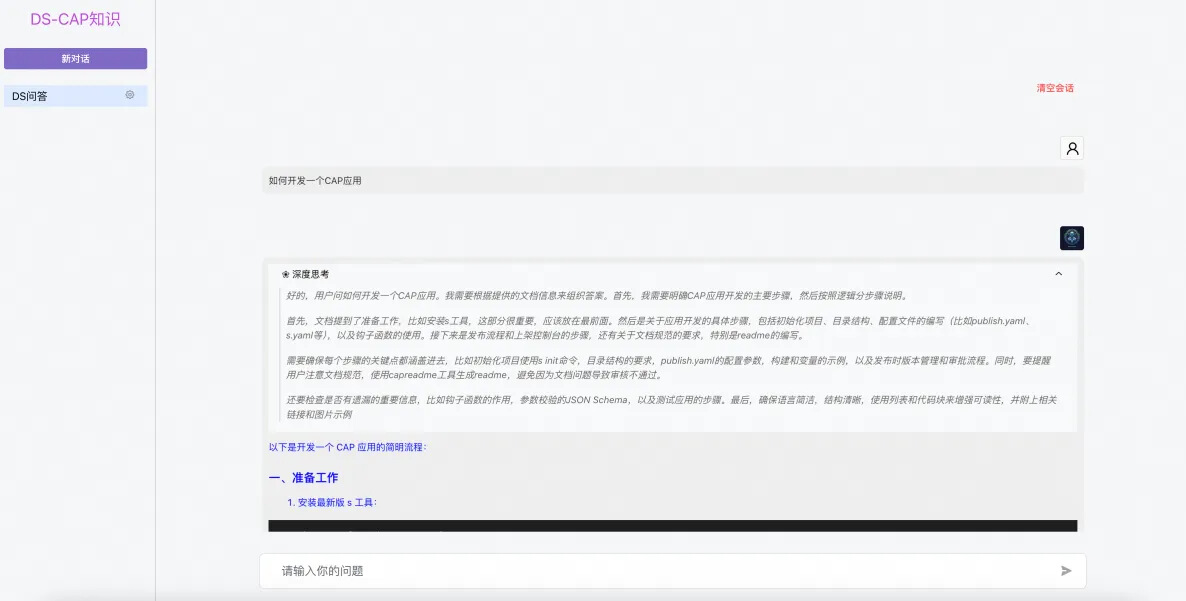
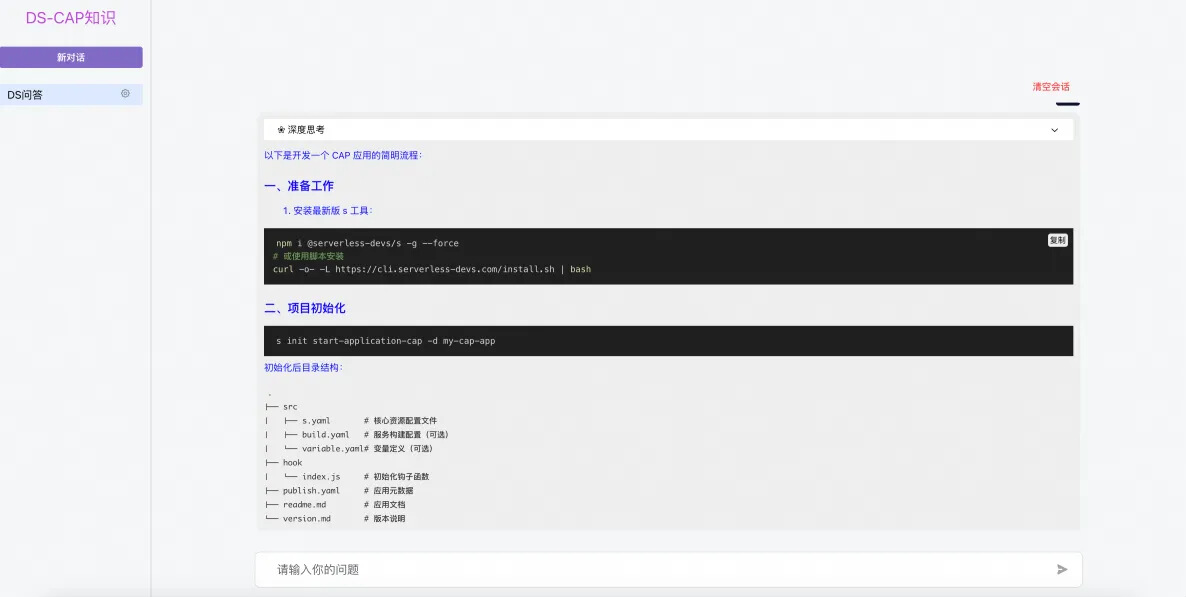
可以看到 DS 给了非常详细的信息。
定制 UI
相信很多同学或企业都希望能够把智能的平台按照自己的方式进行定制,比如我自己定制了自己的“小王同学”后台以及对应的 DS ChatBot。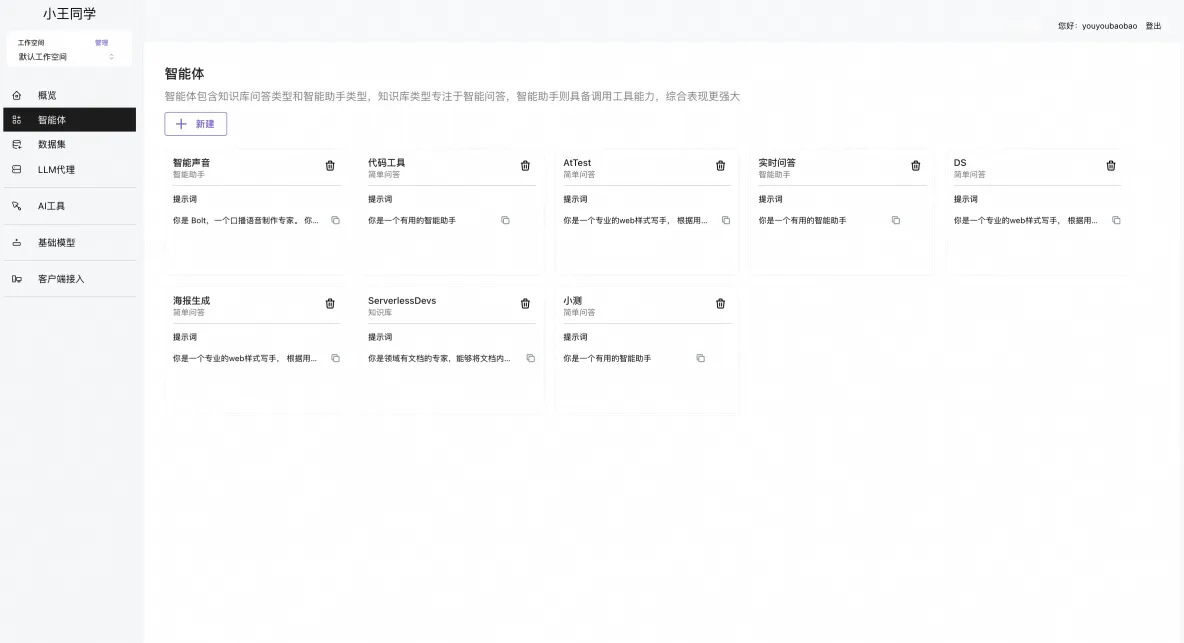
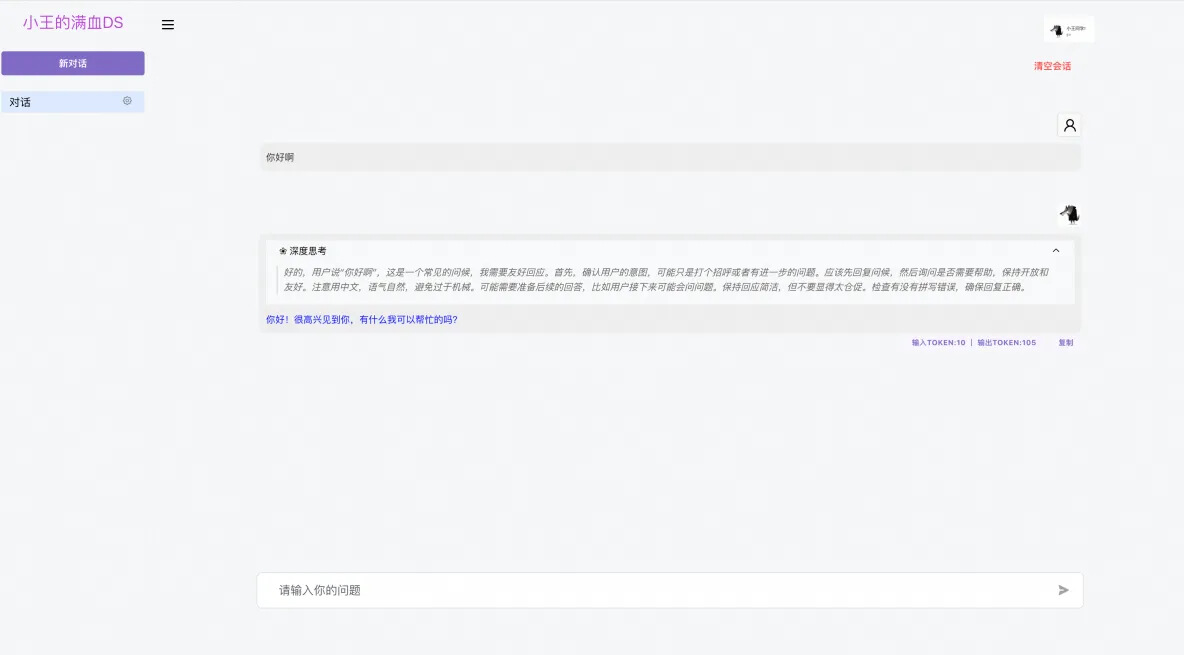
本项目提供完全的视觉定制能力,基于源码的定制以及通过配置进行简单定制,本次主要介绍简单定制。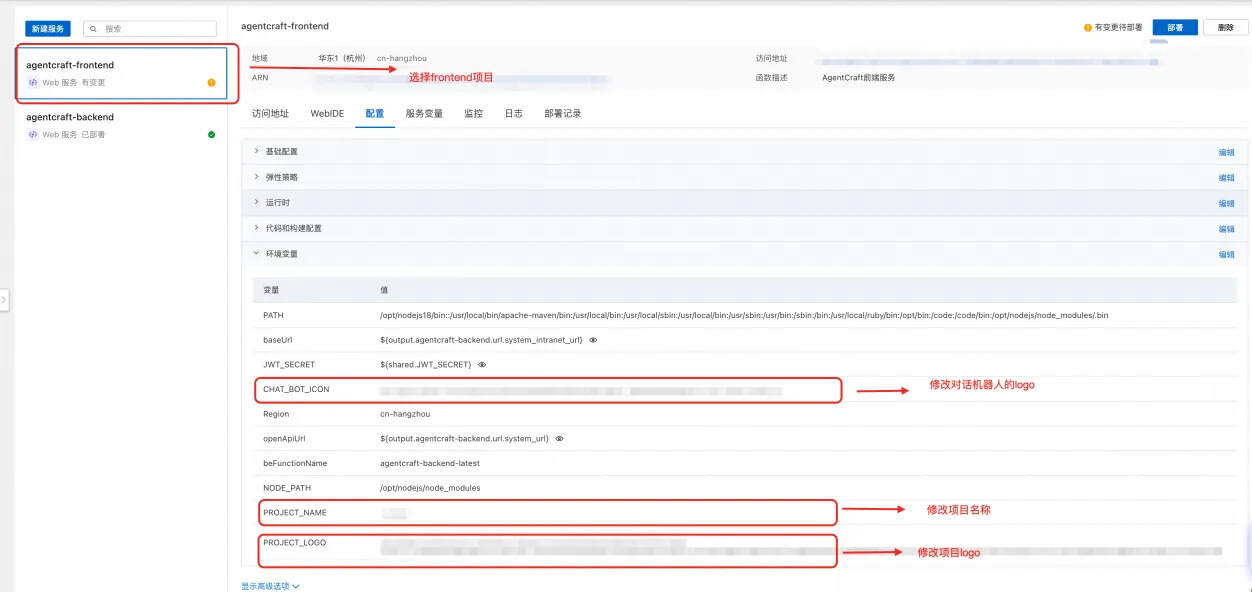

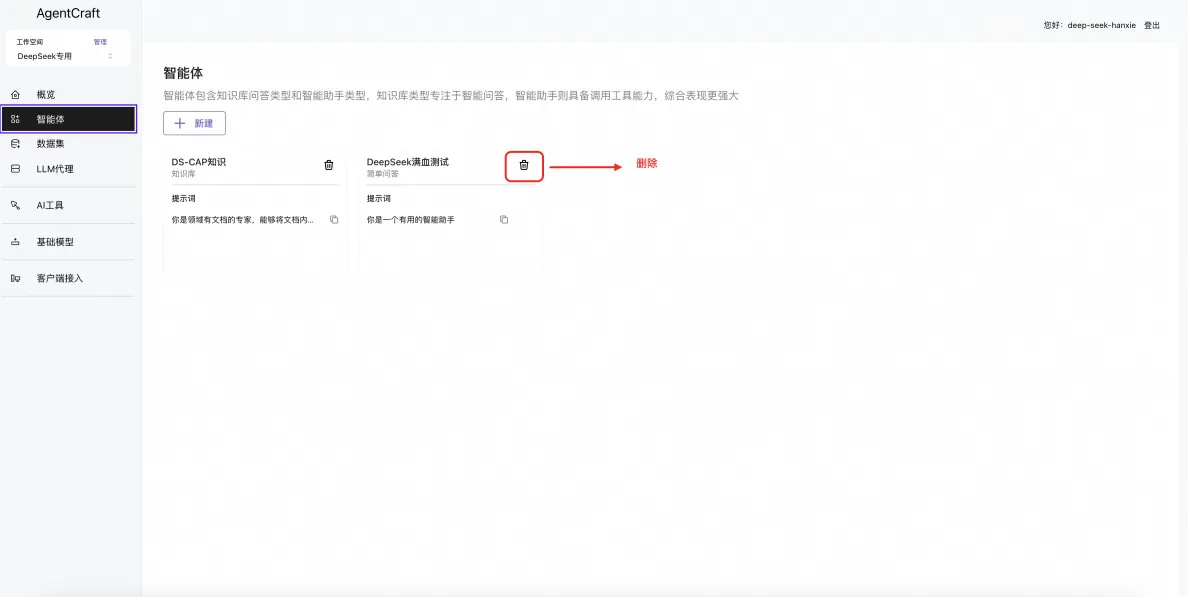
清理项目 - 划重点!
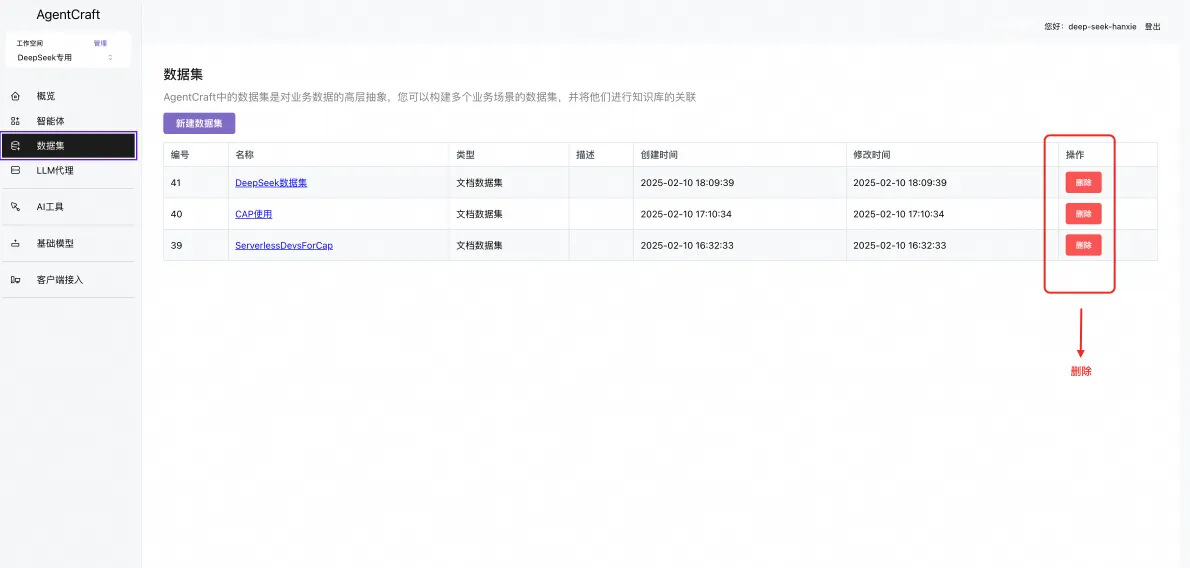
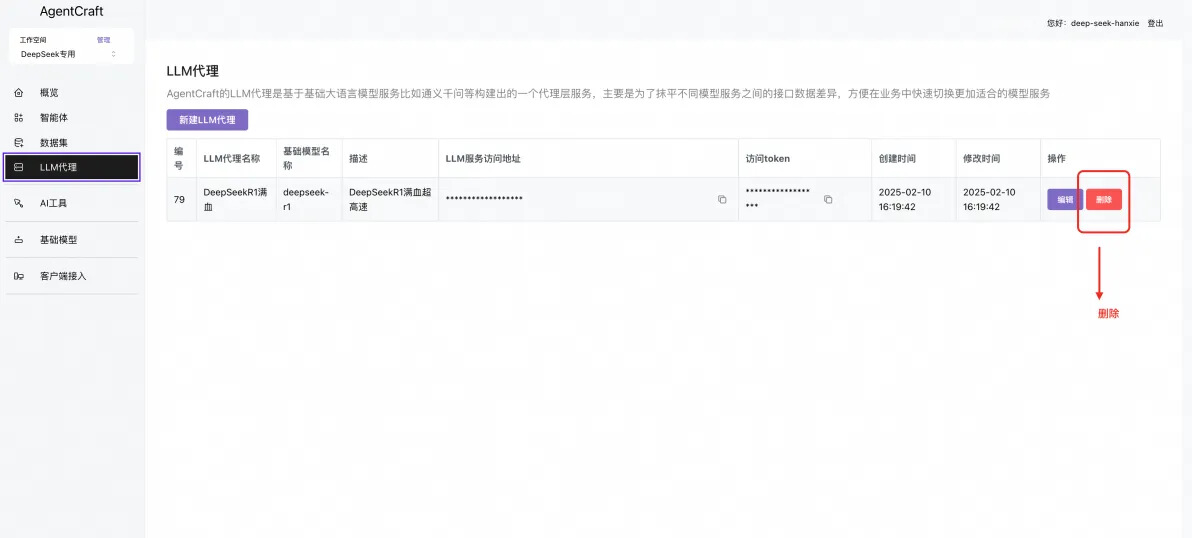
如果您使用的是 共享数据库,您一定要及时清理数据,需要删除相关的数据集,LLM 代理,以及智能体,因为这些数据会存在于共享数据库并不安全。
删除数据集
删除 LLM 代理
删除智能体
更多补充说明
如何获取数据库
如果您需要长期使用该服务,确保所有数据专属化,您需要关注这个部分。
AgentCraft 使用的是 PostgreSql 数据库,您可以考虑在您的虚拟主机上,通过镜像方式拉取,这里是镜像地址:registry.cn-hangzhou.aliyuncs.com/agentcraft/agentcraft-pg:v1 ,虚拟机上装好之后还需要配置网络等等
如果觉得麻烦,不妨考虑直接购买阿里云的数据库服务,相关教程如下:
创建数据库实例(postgresql)
阿里云 postgresql 实例购买链接:https://www.aliyun.com/product/rds?spm=5176.28536895.nav-v2-dropdown-menu-1.139.3e18586cAVXbW6&from=agentcraftagentcraft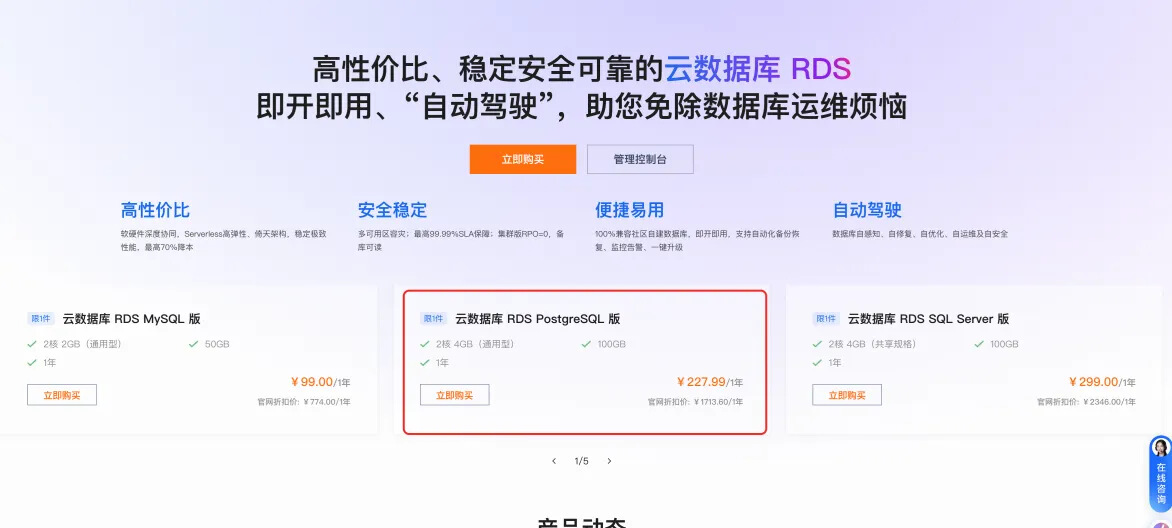
新用户只需 227 一年,拥有 100G 的存储。
创建管理账号
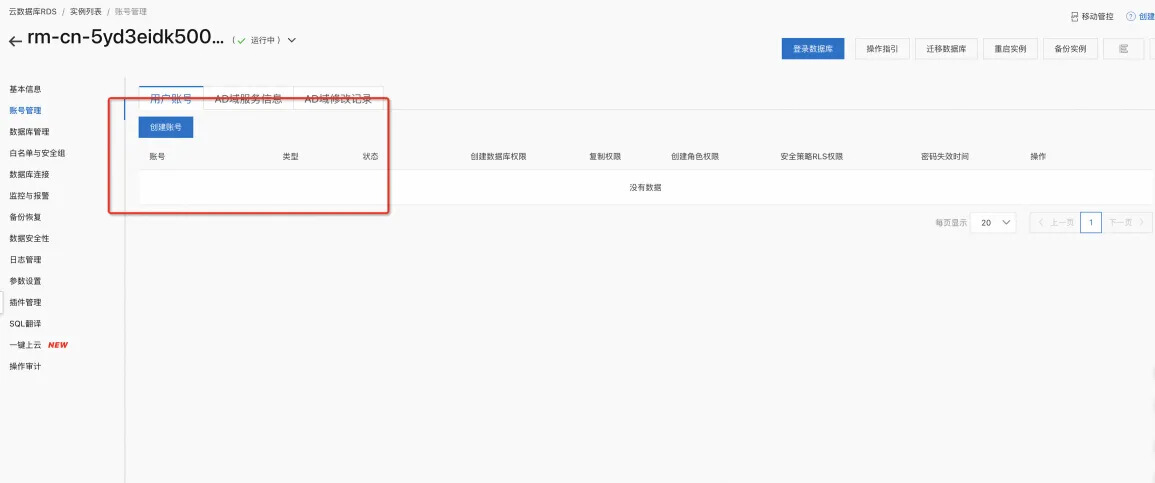
注意选择 高权限 账号(账号及密码后续会持续使用,请妥善管理。)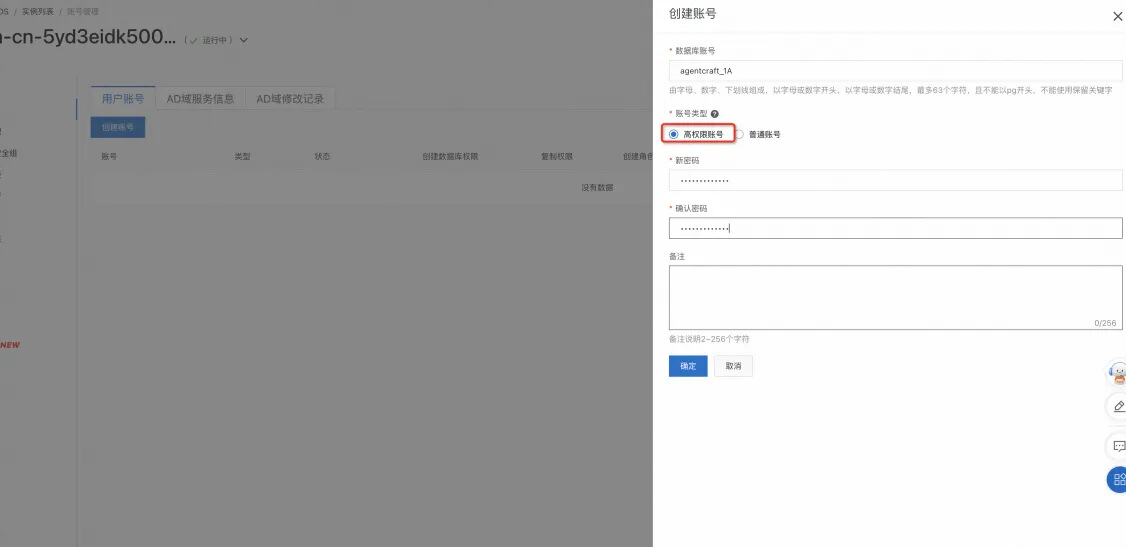
创建数据库
实例创建好之后进行数据库创建。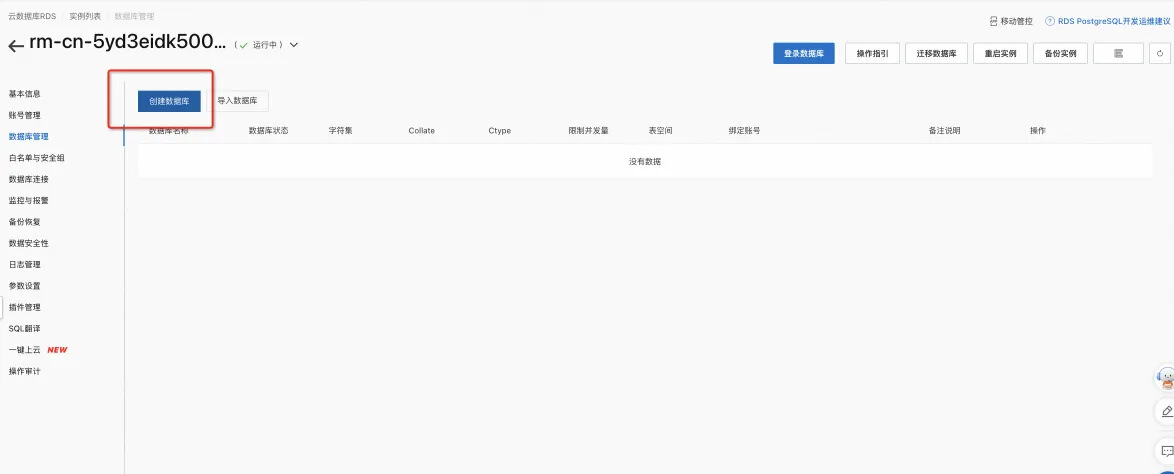
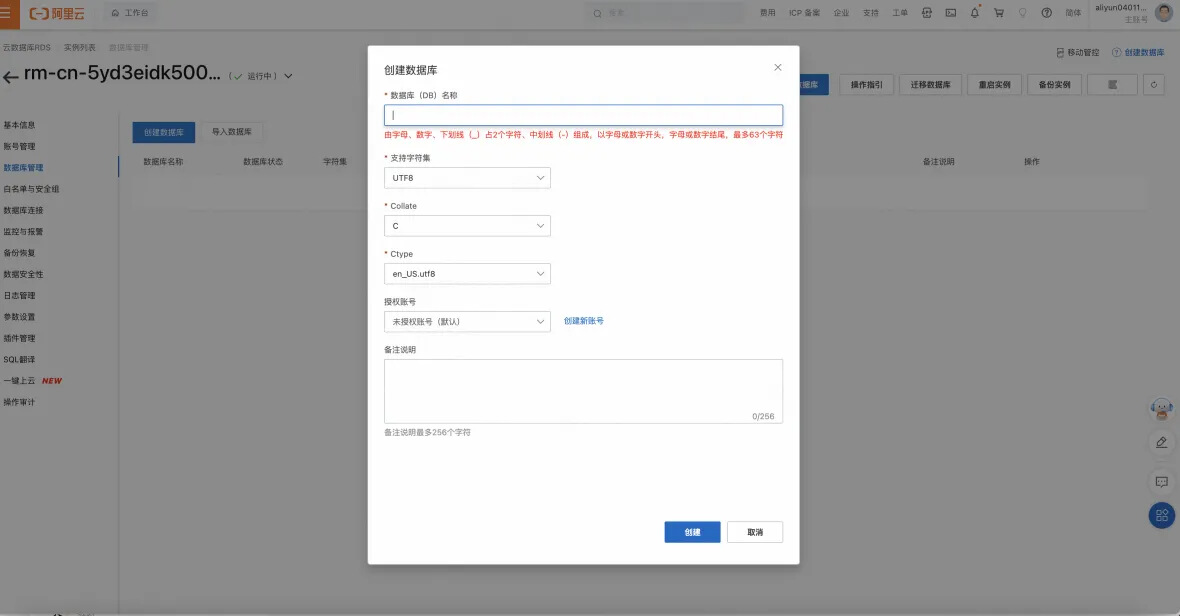
注意这里授权账号选择上述创建的账号。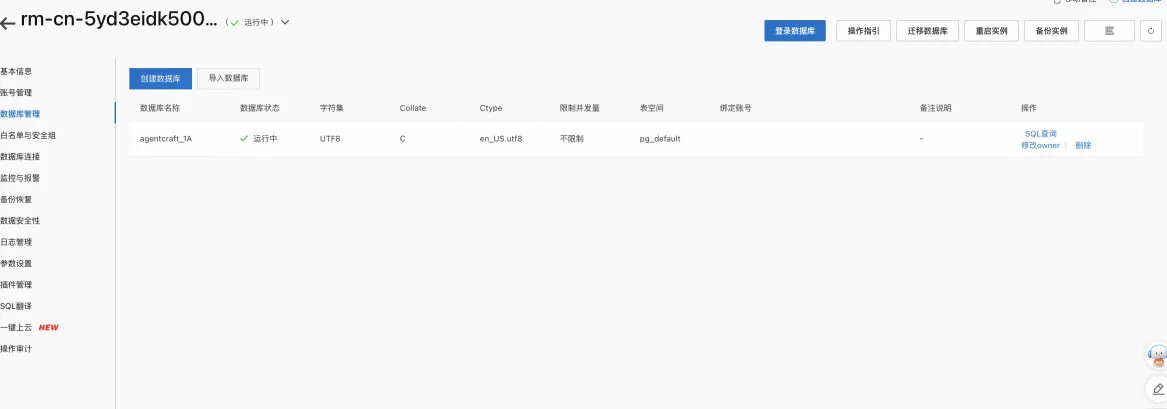
数据库连接测试
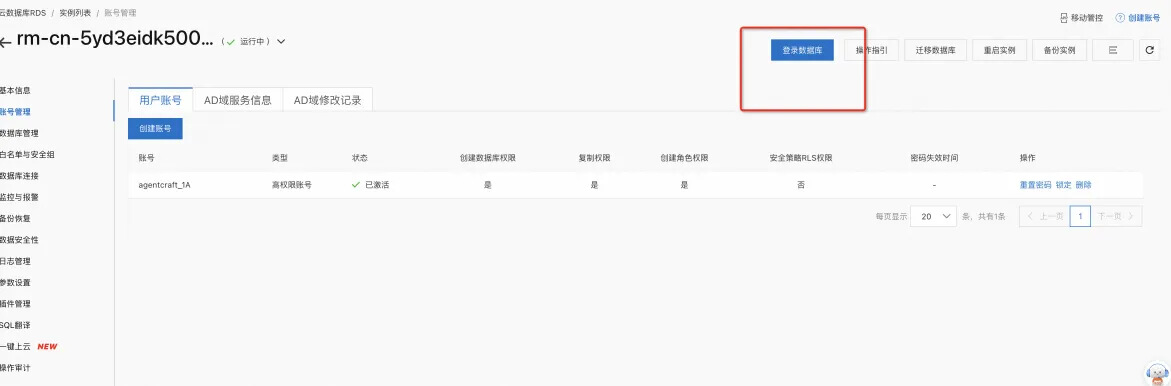
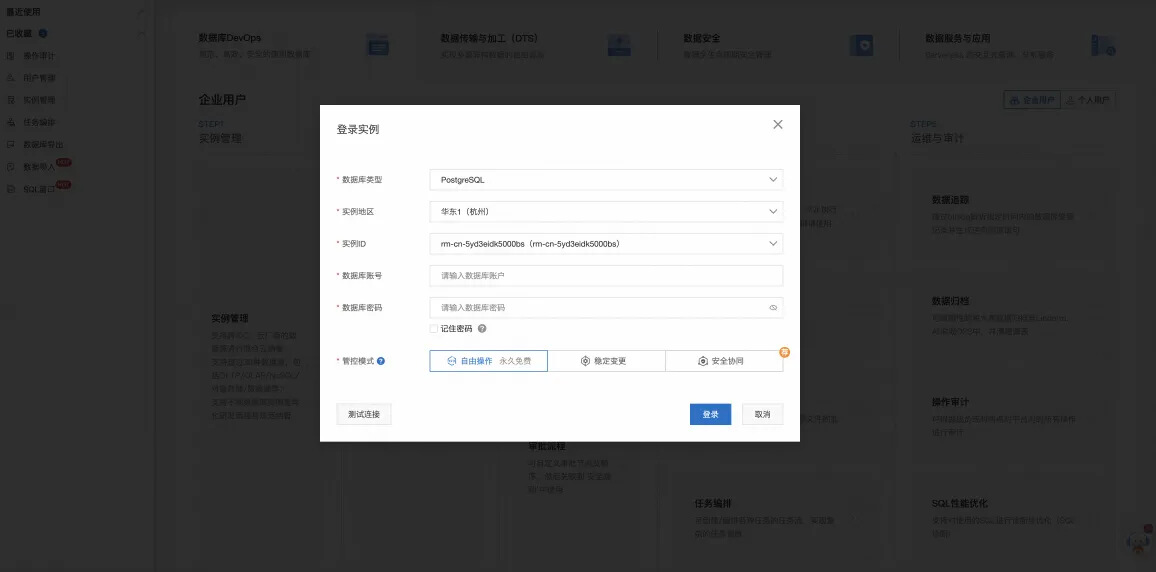
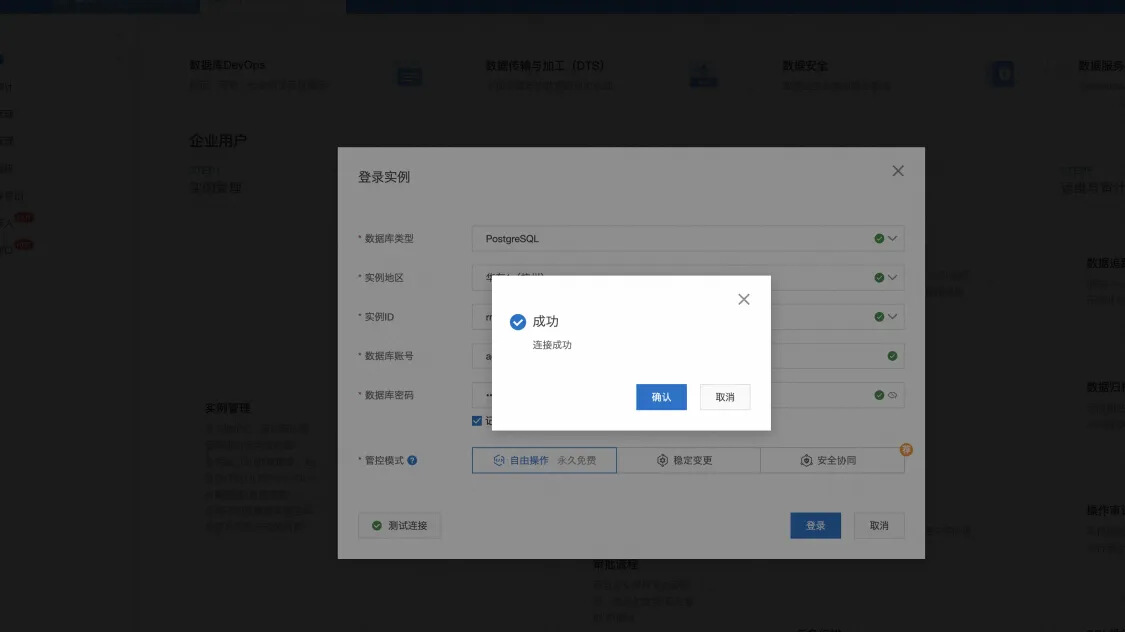
最终配置
数据库连接地址: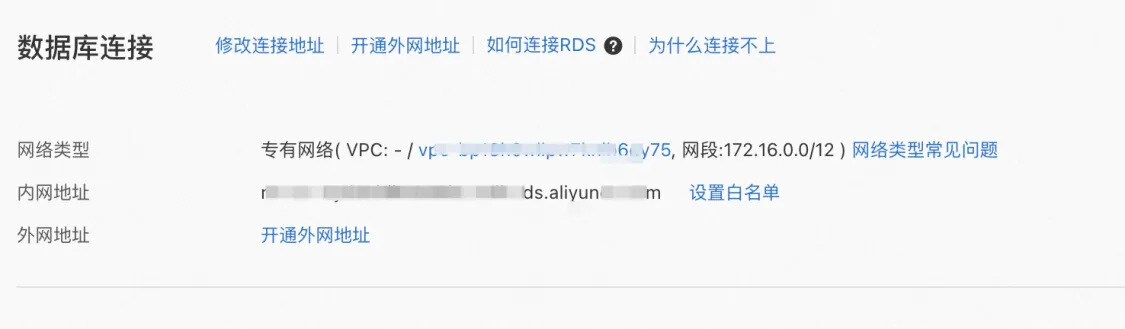
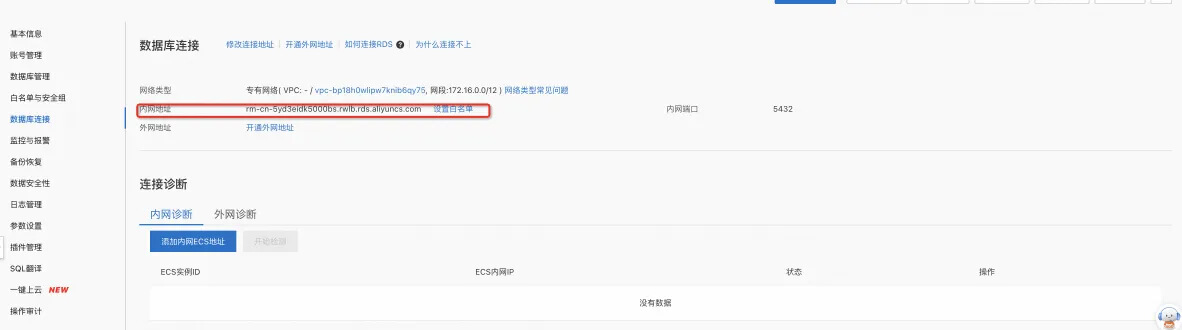
数据库名:
数据库账号:
步骤 2 中所设置的高权限账号。
数据库密码:
步骤 2 中所设置的高权限账号密码。
如何配置更多模型
如果您需要体验更多模型可以按照如下步骤: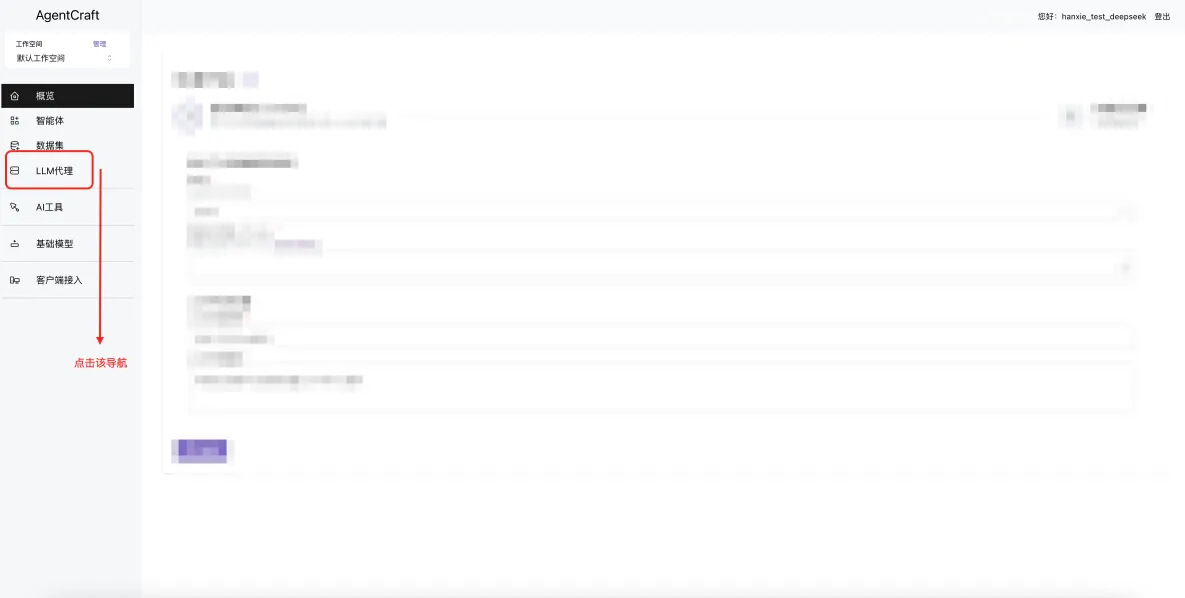
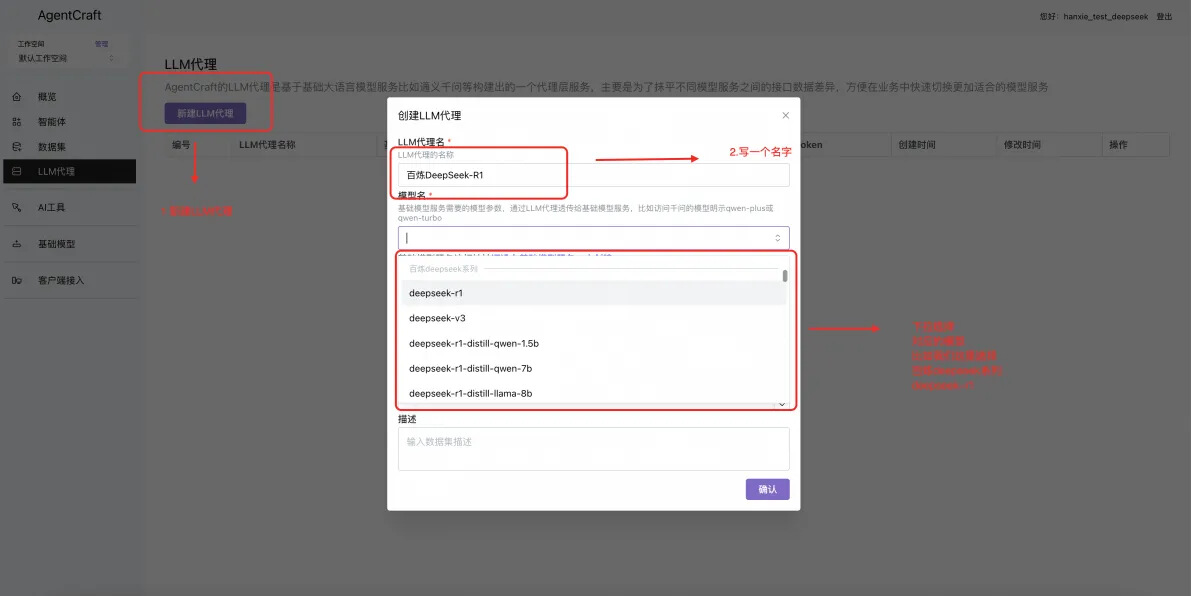
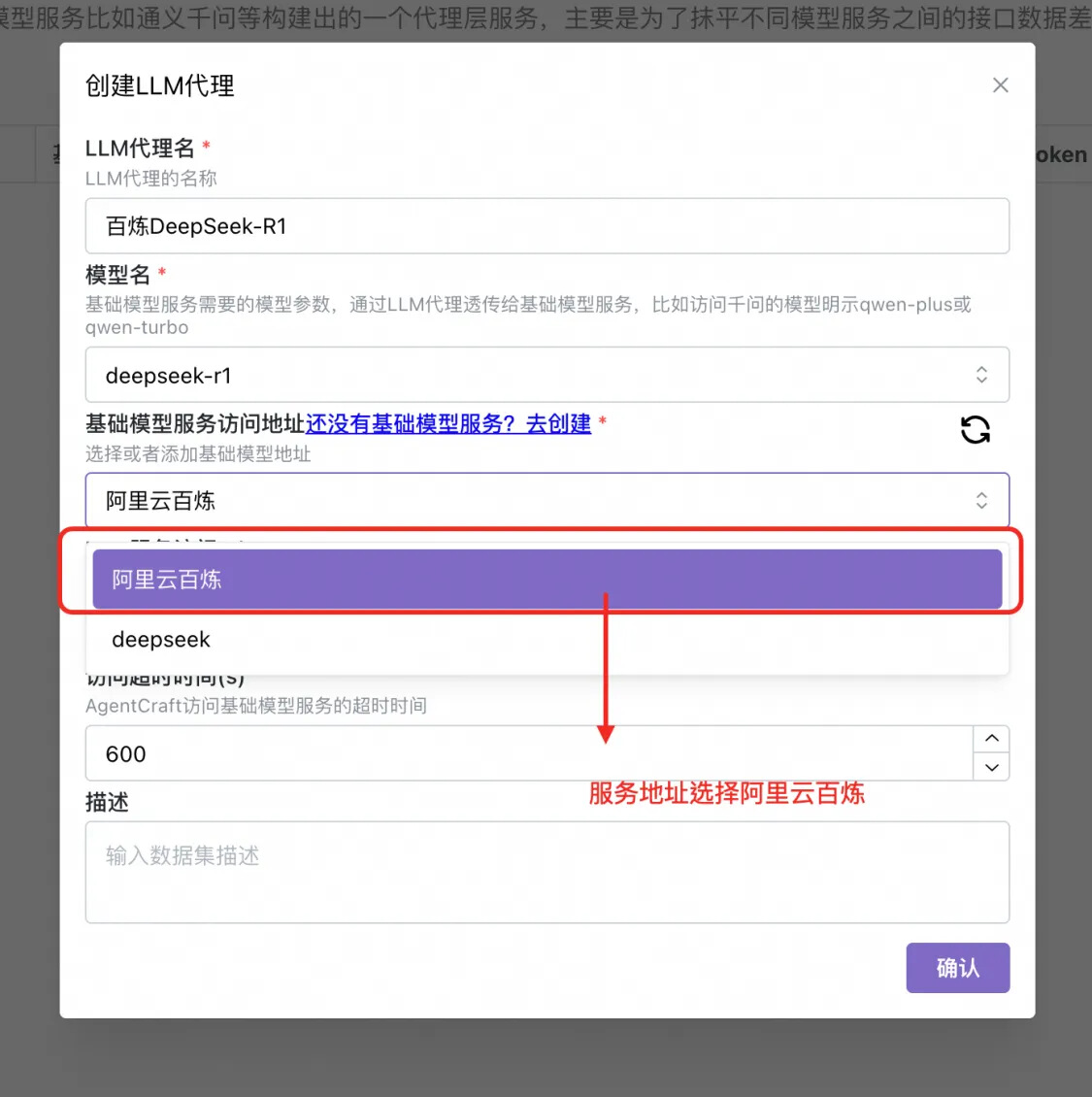
接下来百炼 deepseek-v3, qwen-max-latest 以及 deepseek 官方的 v3,r1 模型按照同样步骤配置(注意需要到 deepseek 的开放平台获取 apikey)。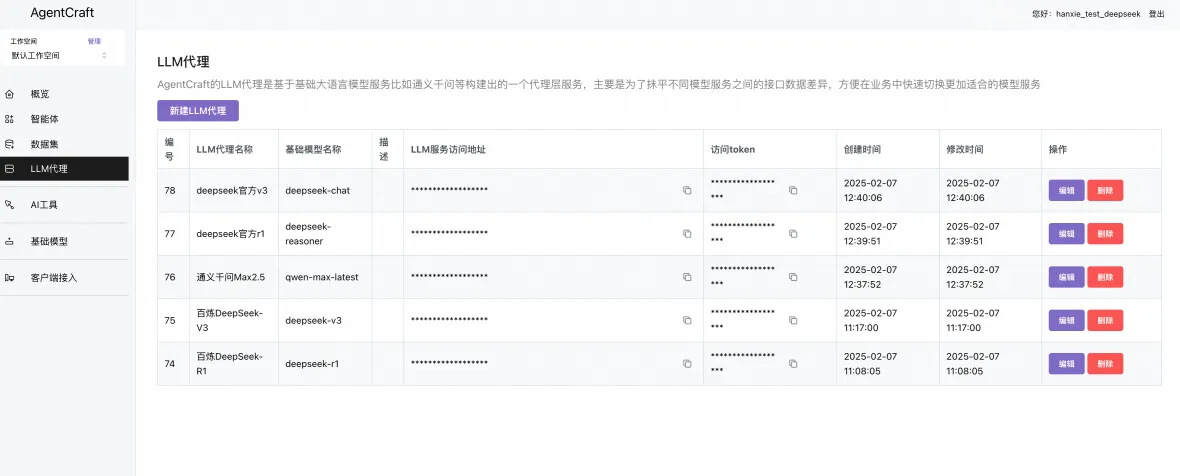
根据以上步骤完成配置,即可开始准备测试。
向量模型单独部署配置
前置步骤中如果您的向量模型服务部署失败,则可以重新部署配置。
注意选取对应的 region,根据指示配置权限。
创建好之后: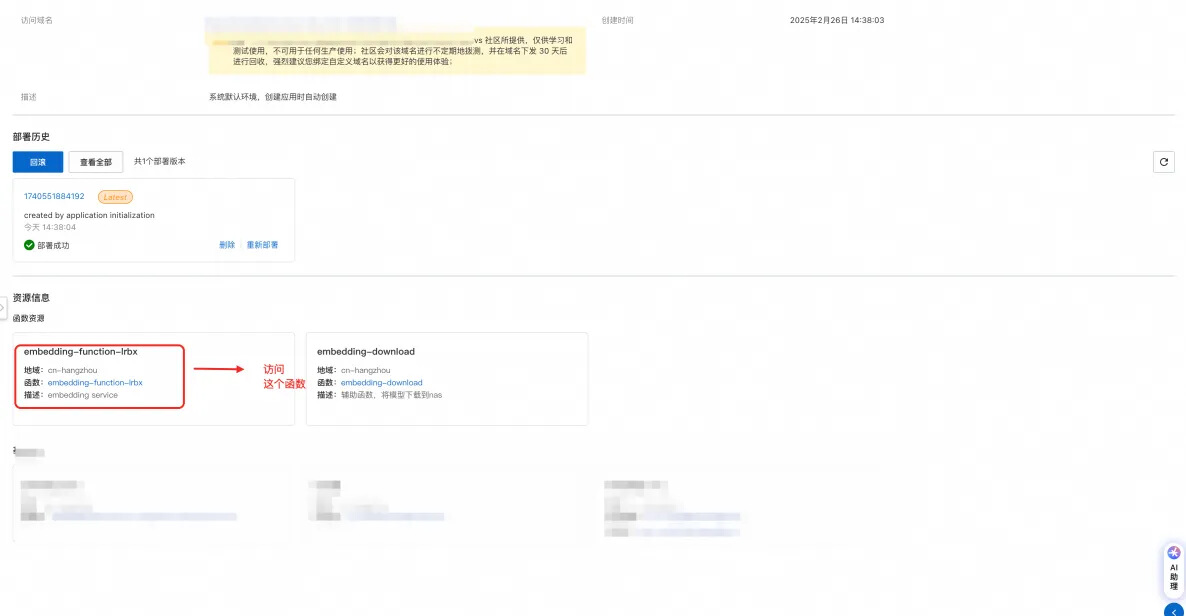
配置 -> 触发器
获取触发器的公网地址(http/https)皆可以。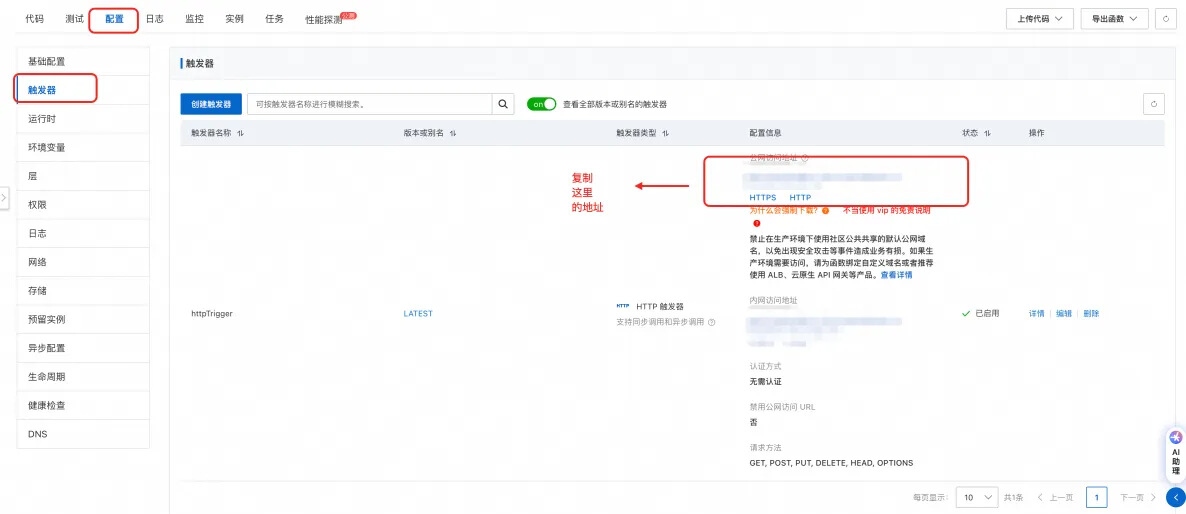
然后进入刚部署的服务,选择 backend,环境变量,添加 EMBEDDING_URL=<复制的地址>/embedding。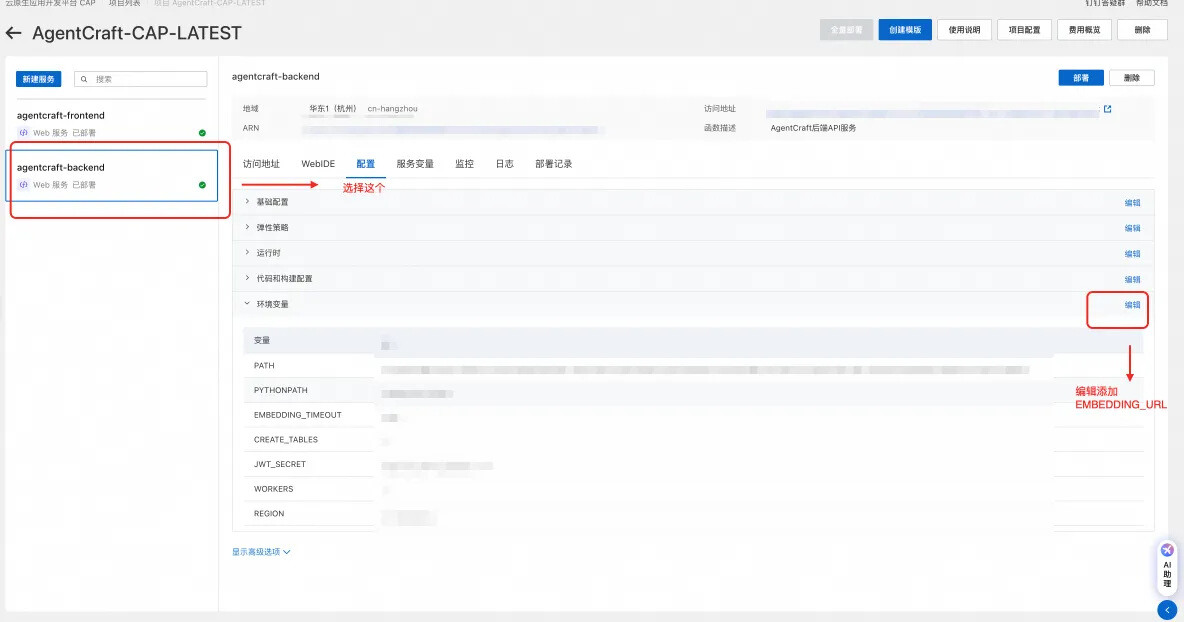
Q&A
Q:访问服务有问题,数据库连不上。
A:
数据库如果使用内网链接,需要保证 vpn 一致,同时确认您的配置使用高权限账号,并且高权限账号授权给您的数据库。
如果已配置 VPC 数据库还是连接不上,建议可以先开放数据库公网连接进行测试。等调通后再去解决网络连接问题。
Q:如何调整模型上下文?
A:
在构建智能体的时候,有 max_token 选项,可以根据需要调整。
Q: 可以长期使用共享数据库么?
A:
建议不要,共享数据库虽然不会存储敏感信息(您自身的数据集包含敏感信息切勿上传),但是因为公网暴露,不安全,所以建议不要作为长期服务使用。
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



