
MaskRCNN(TensorFlow版)的项目地址:
https://github.com/matterport/Mask_RCNN
如果要用这个算法来训练自己的数据集,方法十分简单,只需修改代码的几个关键部分就好了。
准备数据集
首先将你的数据集分为两类,一类为训练集(train),一类为验证集(val)。
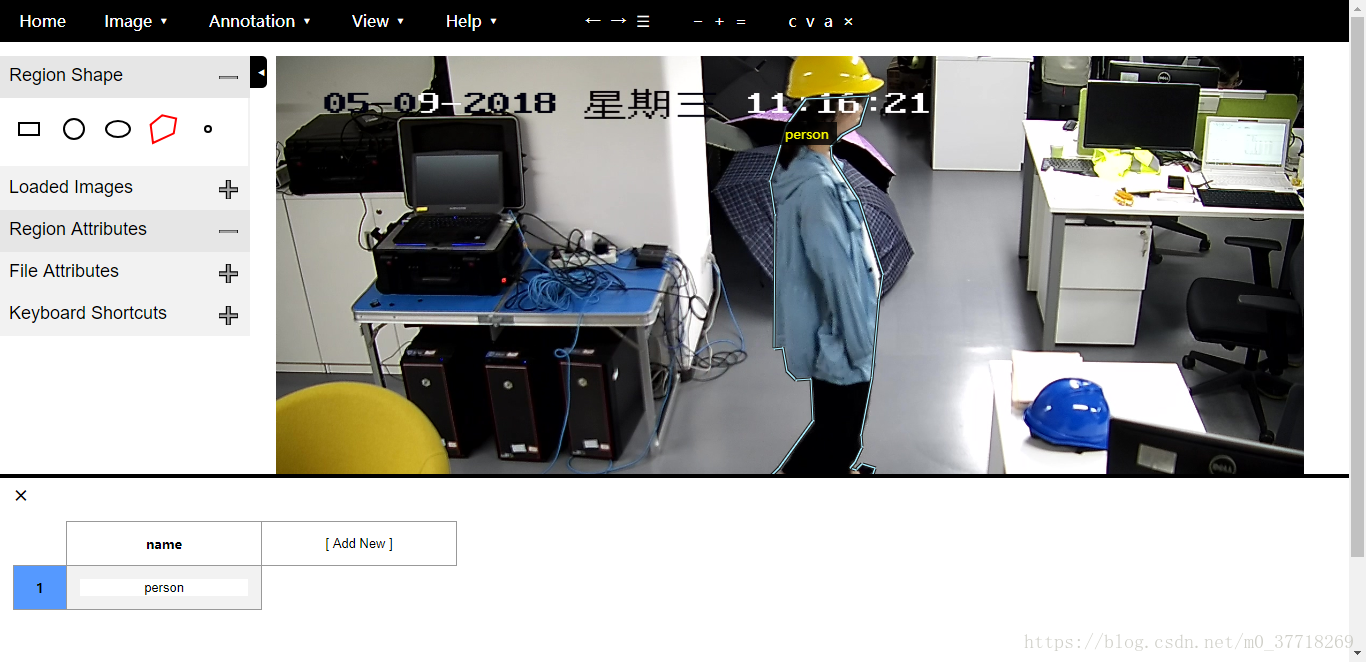
然后是标注数据,这里我用到的工具是VIA(VGG数据集的标注工具),操作起来十分方便。在网页上即可进行数据标注,VIA的链接为:
http://www.robots.ox.ac.uk/~vgg/software/via/
如下图:
修改源代码
数据集准备好之后,我们可以在源代码(balloon.py)的基础上进行修改,使之适应我们的数据集。
1、复制一份balloon.py的代码进行编辑,在class balloon_config下面修改分类个数,我这里是分成3类,所以是1+3,注意默认背景是一类:
class BalloonConfig(Config): """Configuration for training on the toy dataset. Derives from the base Config class and overrides some values. """ # Give the configuration a recognizable name NAME = "balloon" # We use a GPU with 12GB memory, which can fit two images. # Adjust down if you use a smaller GPU. IMAGES_PER_GPU = 2 # Number of classes (including background) NUM_CLASSES = 1 + 3 # Background + 分类类别 # Number of training steps per epoch STEPS_PER_EPOCH = 50 # Skip detections with < 90% confidence DETECTION_MIN_CONFIDENCE = 0.9
2、解析VIA的标注信息
因为源码是用coco数据集,它的标注信息格式与VIA不同,所以我们要修改代码中解析标注信息(annotations)的部分。
在balloon.py中修改load_balloon函数:
def load_balloon(self, dataset_dir, subset): """Load a subset of the Balloon dataset. dataset_dir: Root directory of the dataset. subset: Subset to load: train or val """ # Add classes. # self.add_class("大类名称",序号,"小类") self.add_class("balloon", 1, "helmet") self.add_class("balloon", 2, "person") self.add_class("balloon", 3, "reflector") # self.add_class("helmet",4,"cloth") # Train or validation dataset? assert subset in ["train", "val"]
dataset_dir = os.path.join(dataset_dir, subset) # We mostly care about the x and y coordinates of each region annotations = json.load(open(os.path.join(dataset_dir, "via_region_data.json")))
annotations = list(annotations.values()) # don't need the dict keys # The VIA tool saves images in the JSON even if they don't have any # annotations. Skip unannotated images. annotations = [a for a in annotations if a['regions']] # Add images for a in annotations: # Get the x, y coordinaets of points of the polygons that make up # the outline of each object instance. There are stores in the # shape_attributes (see json format above) polygons = [r['shape_attributes'] for r in a['regions'].values()]
name = [r['region_attributes']['name'] for r in a['regions'].values()] # 序列字典 name_dict = {"helmet":1,"person":2,"reflector":3}
name_id = [name_dict[a] for a in name] # load_mask() needs the image size to convert polygons to masks. # Unfortunately, VIA doesn't include it in JSON, so we must read # the image. This is only managable since the dataset is tiny. image_path = os.path.join(dataset_dir, a['filename'])
image = skimage.io.imread(image_path)
height, width = image.shape[:2] # for i,j in enumerate(polygons): self.add_image( "balloon", image_id=a['filename'], # image_id='{}_{}'.format(a['filename'],i), # use file name as a unique image id path=image_path, class_id=name_id, width=width, height=height, polygons=polygons)注意 self.add_class的第一个参数要一致,表示的是这一个数据集的整体名字,第二个给你的类别标号,第三个参数是类别的具体名称。
3、修改load_mask函数:
def load_mask(self, image_id): """Generate instance masks for an image. Returns: masks: A bool array of shape [height, width, instance count] with one mask per instance. class_ids: a 1D array of class IDs of the instance masks. """ # If not a balloon dataset image, delegate to parent class. image_info = self.image_info[image_id] if image_info["source"] != "balloon" : return super(self.__class__, self).load_mask(image_id) name_id = image_info["class_id"] print(name_id) # Convert polygons to a bitmap mask of shape # [height, width, instance_count] info = self.image_info[image_id] mask = np.zeros([info["height"], info["width"], len(info["polygons"])], dtype=np.uint8) class_ids = np.array(name_id, dtype=np.int32) for i, p in enumerate(info["polygons"]): # Get indexes of pixels inside the polygon and set them to 1 rr, cc = skimage.draw.polygon(p['all_points_y'], p['all_points_x']) mask[rr, cc, i] = 1 # print( mask.astype(np.bool), name_id) # Return mask, and array of class IDs of each instance. Since we have # one class ID only, we return an array of 1s return (mask.astype(np.bool), class_ids)
这样就修改好啦,模型就能正常地跑起来在你的数据集上训练啦,训练完的结果会保存在你所选择的目录里。
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦