
mark一下,感谢作者分享! https://blog.csdn.net/Snail_Ren/article/details/79005069
贝叶斯优化算法(BOA)
背景介绍
当前的场景中,会面临很多设计选择问题。比如说在工程师进行方案设计的时候,需要考虑多种细节选择,才能做出一个稳定可靠的方案。糕点师傅在做蛋糕时,会决定各种配料应该使用多少才能做出好吃的蛋糕……在如此多的需要设计选择的场景中,往往需要从多个维度,多个方面去考虑。有时候需要面对很多种选择。对于资深有经验的人,可以从多种选择中快速选择出能够满足要求的方案,比如专业的糕点师很快能知道,要做出一款美味的蛋糕,需要使用几勺糖,多少毫升牛奶,多少克面粉……而对于我这种小白,我可能需要不断去尝试,首先根据自己的尝试任意进行配比,然后做出蛋糕之后品尝一下,看看是否好吃。如果觉得不好吃,还需要重新再组合一个方案,然后再把蛋糕做出来试吃。经过多次迭代后,在浪费了大量的时间和食材(简直惨绝人寰)之后,终于做出了好吃的蛋糕。
然而在很多其他场景中,进行一次方案可行性测试的成本可能非常高。比如说我们不是做蛋糕,是对机器学习模型的参数进行调试,模型的效果怎么样需要运行实际的任务才能知道。但是运行一个要两周才能运行出结果的任务(这种需要较长时间运行的任务是存在的),那么明显按照我做蛋糕那种方法去运行任务,那在得出较好的参数方案的时候需要无法忍受的时间,因此显然是不可取的。另一方面,刚才我们做蛋糕,可能只需要对面粉量、牛奶量、糖量等几个维度进行选择。但是有的场景下,需要对上百个维度进行选择,同时各个维度可选的候选空间也非常大。此外,各个维度属性可能有内部的相互影响。那么靠人工的方法,几乎很难找到最优的维度组合方案。因此在这种情形下,贝叶斯优化算法(BOA)就可以派上用场了。当前BOA运用很广泛,包括用于组合优化、自动机器学习、增强学习、气象、机器人等等
贝叶斯优化流程
形式化
首先为了便于讨论问题,我们形式化一下。贝叶斯优化算法(BOA)主要面向的问题场景是:
公式(1)中,S是x的候选集。目标是从S中选择一个x,使得 。
算法流程
那么,现在我们的目标就是从 有一个猜想的先验分布模型,然后利用后续新获取到的信息,来不断优化那个猜想模型,使模型越来越接近真实的分布。
Created with Raphaël 2.1.0开始(1)猜想的分布模型M(2)根据模型M选择一个新的X(3)获得X对应的F(X)(4)(X,F(X))是否满足需求?结束(5)利用(X,F(X))修正模型Myesno
上面这个图是个大致的简图。先不用太深入,我们先简单看看流程。
Step(1)
第一步首先是有一个先验的猜想。既然我们是需要求出满足条件的,将这两组数据输入GP模型中,两个真实值加入猜想模型,能够对模型进行修正,使其更接近目标函数真实的分布**。
Step(2)
第一步有了修正后的GP。我们根据某些方法,来从修正后的GP中,选择一个感兴趣的点更优。
Step(3)
选出了一个新的。
Step(4)
反之,假如上一步找出的点还达不到我们的需求,那这个点也不能浪费,将其输入返回到GP模型,再次对其修正,重新开始Step(2)
经过上面的初步分析后,我们大概了解了贝叶斯优化的整个流程。从上面描述的流程可以看出,贝叶斯优化最核心的步骤是Step(1),Step(2)。在Step(1)中我们猜想的分布模型,以及Step(2)中支持我们做出选择新的点的方法,这里我们定义一下一般这个方法叫Acquisition function(后面简称AC函数)。这个收益(损失)函数指导我们选择下一个点。只要把这两个东西确定了,那么整个算法就确定了。从这里也可以看出BOA是一个迭代运行的算法框架,由两个组件组成,一个是先验模型,一个是AC函数。这两者的作用分别如下:
先验模型(prior function)基于概率分布,用于描述目标函数的分布(可以理解为用于拟合目标函数曲线)
AC函数用于从候选集中选择一个新的点。BOA的运行效果,和AC函数的设计有很大关系。由于此类函数可能陷入局部最优解,因此在选点的时候,需要考虑到很多方面因素,不能过早进入局部。因此需要进行多方面权衡,然后综合之后选点。选出的点的质量直接影响算法的收敛速度以及最终解的质量。
这里再给一个更加具体的流程图。这图和开始的简图差不多,我也就不多解释了,应该大致能看懂。
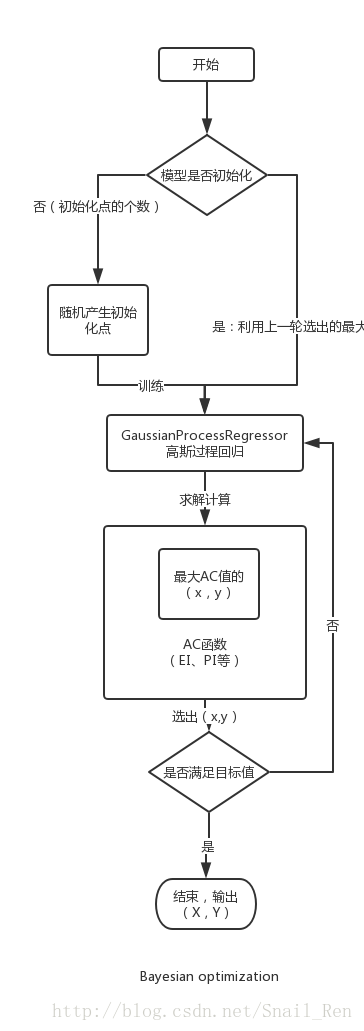
核心算法
上面说了BOA最核心的两个组件Prior Function以及Acquisition Function(AC)。
Prior Function
上面说到,当我们不知道目标函数曲线是什么样的时候,我们就只能猜(概率)。主要的方式有含参、不含参、线性、非线形等。比如有高斯过程(GP),认为目标函数满足多变量高斯分布。当然也有存在其他的函数,在选择PF的时候,需要谨慎选择模型,不同的模型效果是不一样的。
Acquisition Function
在经历过PF的选择后,那么就要对PF模型进行进一步修正。让他修正的方法很简单,就是给他尽量滴提供更多的真实样本点呗。那么应该提供什么样本点呢?假如我们把所有候选集中的样本点都提供给模型,那么目标函数曲线其实就出来了。但是很明显,根据BOA的使用场景,我们无法将所有的样本点都提供出来,因为产生一个真实样本点的成本很高。那么我们就应该选择那种能够提供更多信息给模型的点。就像我们打游戏,假如我们血有限的话,那么就尽量去打得分多的怪。那么AC函数(Acquisition Function)就指导我们如何选点。那么AC函数也分很多种类。
Improvement-based policies
这种方法的基本思想是选择收益最高的点。包括如PI、EI等方式参考文献
Optimistic policies
这种方法主要采用上限置信区间(upper confidence bound)。常用的如GP-UCB等方法Information-based policies
此类方式思想是利用后验信息来进行选点。常用有Thompson sampling 和 entropy search。基于熵的方法感觉发展空间还比较大,有一些相关工作都有用到这个Portfolios of acquisition functions
这类方法就是将多种AC方法进行集成,最近的工作比如有ESP
[1] Taking the Human Out of the Loop: A Review of Bayesian Optimization
算法部分讲的很简单,后面再进行补充。文中有理解不正确的地方,欢迎各位大佬拍砖
共同学习,写下你的评论
评论加载中...
作者其他优质文章



