

什么是爬虫?
就是抓取网页数据的程序
爬虫怎么抓取网页数据?
网页三大特征:
网页都有自己唯一的URL。
网页都是HTML来描述页面信息。
网页都使用http/https协议来传输HTML数据。
爬虫的设计思路:
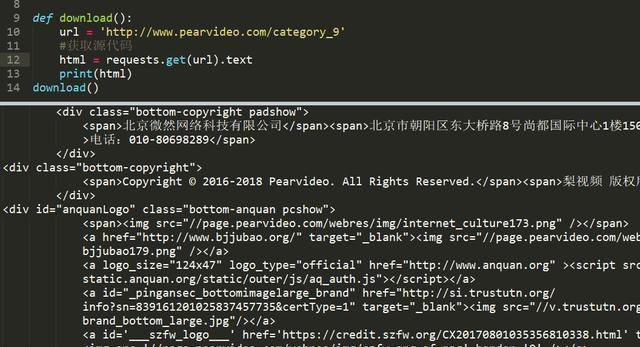
获取视频ID
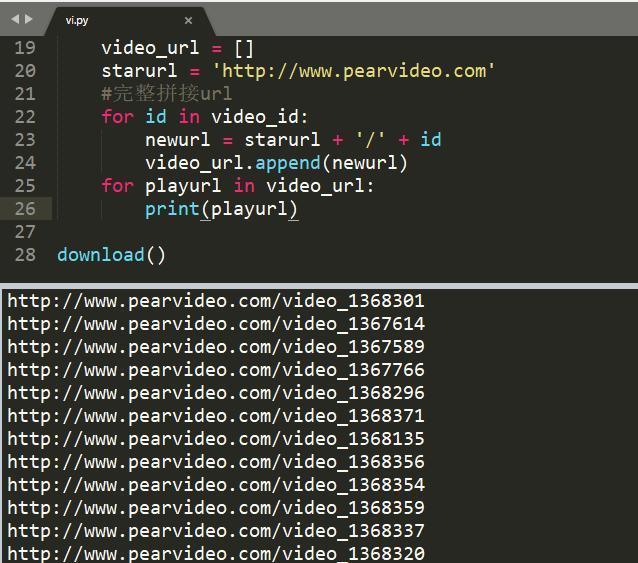
拼接完整url
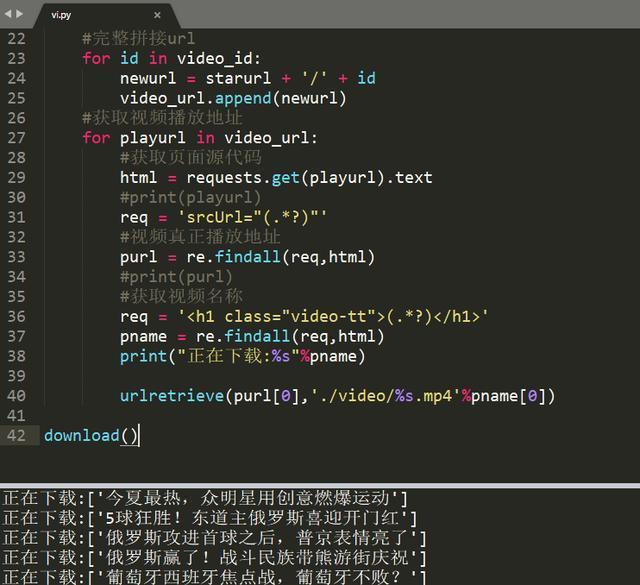
获取视频播放地址
下载视频
模块使用 requests
安装“pip install requests”
Requests库的七个主要方法

找到单个视频播放地址
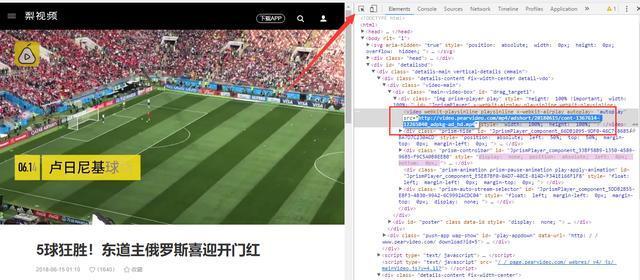
获取网页源代码
获取播放地址
下载视频
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦