
在数据抓取的过程中,我们往往都需要对数据进行处理
本篇文章我们主要来介绍python的HTML和XML的分析库BeautifulSoup
BeautifulSoup 的官方文档网站如下
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
BeautifulSoup官网
BeautifulSoup可以在HTML和XML的结构化文档中抽取出数据,而且还提供了各类方法,可以很方便的对文档进行搜索、抽取和修改,能极大的提高我们数据挖掘的效率
下面我们来安装BeautifulSoup
BeautifulSoup模块安装
(上面我已经安装过了,所以没有显示进度条)
非常简单,无非就是pip install 加安装的包名
pip3 install bs4
下面我们开始正式来学习这个模块
首先还是提供一个目标网址
我的个人网站
特克斯博客
下面我们通过requests的get方法保存这个网址内容的源代码
import requests
urls = "http://www.susmote.com"resp = requests.get(urls)
resp.encoding = "utf8"content = resp.textwith open("Bs4_test.html", 'w', encoding="utf8") as f:
f.write(content)运行起来,我们马上就能得到这个网页的源代码了
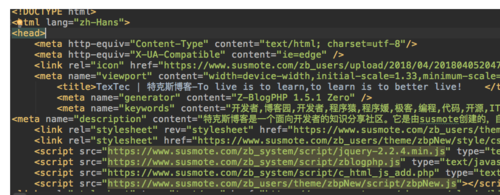
网站源代码
下面我们写的程序就是专门针对这个源代码利用BeautifulSoup来分析
首先我们来获取里面所有的a标签的href链接和对应的文本
代码如下
from bs4 import BeautifulSoupwith open("Bs4_test.html", 'r', encoding='utf8') as f:
bs = BeautifulSoup(f.read())
a_list = bs.find_all('a') for a in a_list: if a.text != "":
print(a.text.strip(), a["href"])首先我们从BS4里面导入BeautifulSoup
然后以只读模式打开文件打开文件,我们把f.read()作为BeautifulSoup的参数,也就是将字符串初始化,把返回的对象记为bs
然后我们就可以调用BeautifulSoup的方法了,BeautifulSoup的最常用的方法就是find和find_all,可以在文档中找到符合条件的元素,区别就是找到一个,和找到所有
在这里我们使用find_all方法,他的常用形式是
元素列表 = bs.find_all(元素名称, attires = {属性名:属性值})然后就是依次输出找到的元素,这里就不多说 了
我们在命令行运行这段代码
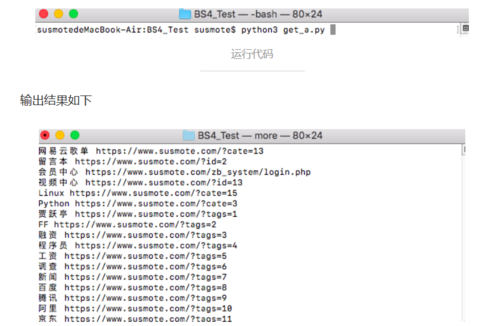
找寻的结果太多,不一一呈现
可以看到爬取的链接其中有很多规律
例如标签链接
我们可以对代码进行稍微的更改,以获取网站所有的标签链接,也就是做一个过滤
代码如下
from bs4 import BeautifulSoupwith open("Bs4_test.html", 'r', encoding='utf8') as f:
bs = BeautifulSoup(f.read(), "lxml")
a_list = bs.find_all('a') for a in a_list: if a.text != "" and 'tag' in a["href"]:
print(a.text.strip(), a["href"])大致内容没有改变,只是在输出前加了一个判定条件,以实现过滤
我们在命令行运行这个程序
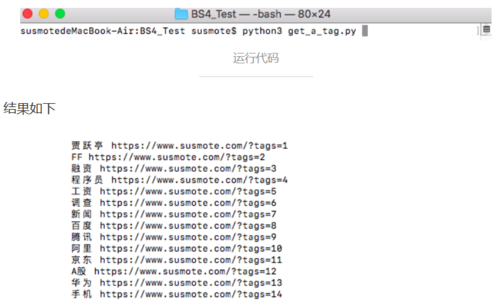
除了这样,你还可以使用很多方法达到相同的目标
使用attrs = [ 属性名 : 属性值 ] 参数
属性名我相信学过html的人一定都知道,例如"class","id"、"style"都是属性,下面我们逐步深入,利用这个来深入挖掘数据
获取我的博客网站中每篇文章的标题
经过浏览器调试,我们很容易获取到我的博客网页中标题部分的属性样式
如下图
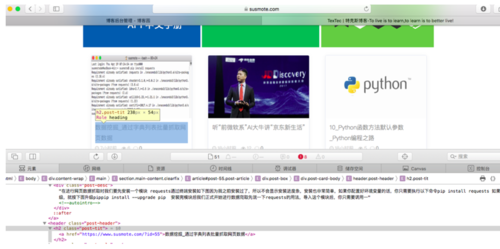
浏览器调试
标题样式是一个<header class="post-header">
非常简单的一个属性
下面我们通过代码来实现批量获取文章标题
# coding=utf-8__Author__ = "susmote"from bs4 import BeautifulSoup
n = 0with open("Bs4_test.html", 'r', encoding='utf8') as f:
bs = BeautifulSoup(f.read(), "lxml")
header_list = bs.find_all('header', attrs={'class': 'post-header'}) for header in header_list:
n = int(n)
n += 1
if header.text != "":
print(str(n) + ": " + header.text.strip() + "\n")大体上跟之前的代码没什么差别,只是在find_all方法中多加了一个参数,attrs以实现属性过滤,然后为了使结果更清晰,我加了一个n
在命令行下运行,结果如下
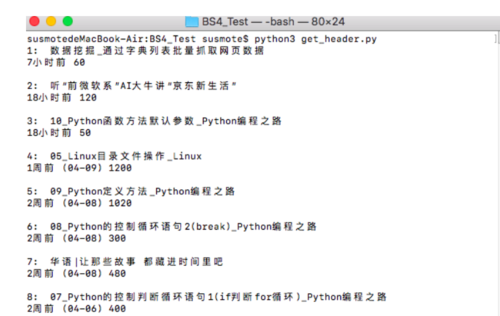
运行结果
利用正则表达式来表达属性值的特征
无非就是在属性值后面加一个正则匹配的方法,我在这就不过多解释了,如果想要了解,可以自行上网百度
作者:susmote
链接:https://www.jianshu.com/p/5a9b2f7be5be
共同学习,写下你的评论
评论加载中...
作者其他优质文章



