
<p>本文讲述如何利用Python模拟淘宝的搜索过程并对搜索结果进行初步的数据可视化分析。</p>
搜索过程的模拟:淘宝的搜索页面有两种形式,一种形式是手机大类产品页面,一种形式是其余产品页面。当然其余搜索占了总搜索类别的99%以上,本文会以其余为主进行淘宝搜索的模拟;
初步数据可视化分析:对搜索回来的数据,通过店铺城市生成坐标数据,并将销量、售价在地图上标示出来。坐标数据的获得要通过高德地图的API插口,数据可视化为利用Plotly生成Buble Map。
利用Python模拟搜索过程
<p>首先需要先对淘宝的模式进行标识,通过几个关键词搜索之后,可以发现其地址的变化规律,如下图所示:</p>
淘宝搜索**脱皮绿豆**试试
<p>忽略掉q=脱皮绿豆后面的部分试试,在网址栏输入(https://s.taobao.com/search?q=脱皮绿豆) ,发现可行。这样就简单了,后续就是解析生成页、生成翻页器、以及存储生成数据即可。</p>
解析生成页
<p>和之前的例子类似,结合requests以及BeautifulSoup来完成页面数据下载:</p>
def mainPaser(url):
Headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36"}
Response = requests.get(url, headers=Headers)
Interial = BeautifulSoup(Response.content, 'lxml')
pageConfig = Interial.find('script', text=re.compile('g_page_config')) return pageConfig.string<p>继续对淘宝的页面进行Inspect,发现每一框的店铺数据储存在g_page_config中的auctions中,并且g_page_config中的数据为json格式。</p>
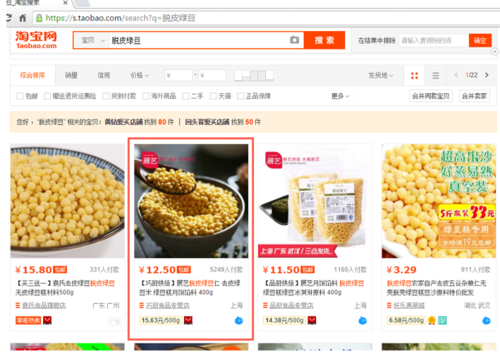
淘宝搜索页面
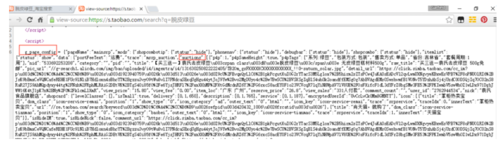
g_page_config以及auctions
获取原始数据
<p>在Python中,json可以通过专门的解析器来完成。通过其中的loads 和dumps 可以轻易的在json以及str之间做转换。将str转换为json格式,在通过pandas 的read_json获取json中的数据信息。</p>
<p>每一框店铺的数据涵括非常丰富的店铺信息以及销售信息,在这里仅收集宝贝分类(category)、评论数(comment_count)、宝贝位置(item_loc)、店铺名称(nick)、宝贝名称(raw_title)、原价格(reserve_price)、显示价格(view_price)、销量(view_sales)进行分析:</p>
neededColumns = ['category', 'comment_count', 'item_loc', 'nick', 'raw_title', 'view_price', 'view_sales'] PageConfig = re.search(r'g_page_config = (.*?);\n', pageConfig.string) pageConfigJson = json.loads(gPageConfig.group(1)) pageItems = pageConfigJson['mods']['itemlist']['data']['auctions'] pageItemsJson = json.dumps(pageItems) pageData = pd.read_json(pageItemsJson) neededData = pageData[Paser.neededColumns]
整理生成数据
<p>接下来就是对得出的数据进行整理,我们先看看neededData的结构是如何,如下表所示:</p>
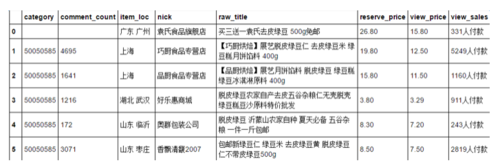
neededData
<p>其中item_loc是网店的地址,可以看到直辖市是比较特殊的存在,将这一列改的省份名称删掉,方法是单独将这一列拿出来通过pandas.Series.str.split来处理,以空格为标识符,将该列的省份以及城市拆分为两列,结果如下图,通过pandas.DataFrame.fillna向左填充对None进行填充:</p>
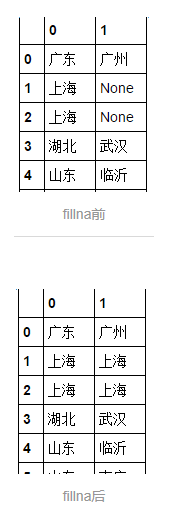
<p>这样就实现对item_loc列的修改,看回neededData那张图,最后一列view_sales中,需要将每个单元格中付款两个字删去。需要采用pandas.Series.str.extract,结合正则表达式来处理。将数字文本拖出来之后,还需要通过astype函数将其转化为int格式,并增加时间列。最后该段数据整理的代码,以及处理后的效果图为:</p>
cityData = neededData['item_loc'].str.split(' ', expand = True)
cityData.fillna(method = 'pad', axis= 1, inplace= True)
neededData.loc[:,('item_loc')] = cityData[1]
neededData.loc[:,('view_sales')] = neededData['view_sales'].str.extract('([\d]*)([\w]*)').get(0)
neededData.loc[:,('view_sales')] = neededData['view_sales'].astype(int)
neededData['time'] = datetime.datetime.now().strftime('%Y%m%d%H')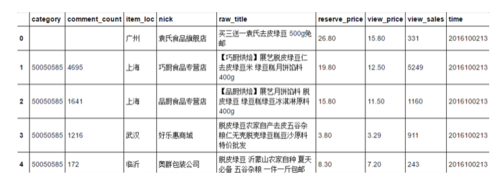
处理结果
生成翻页器
<p>最后就是生成翻页器了,在刚刚的g_page_config中搜索pager试试:</p>

寻找翻页器

寻找翻页器
<p>将其中的\\u003d和=以及\\u0026和&作替换(我是通过字符替换处理。。单应该存在更加方便的,从编码角度入手处理的方法。。求指教),并更换一二三页,发现网址最后的参数s分别为0,44,88。结合上面第二张图,可以猜到这个数字为单页的店铺总量,当页面默认每页的店铺数为44的时候,只需要更改该参数即可达到翻页效果。</p>
数据可视化
<p>为了对将销售数据以及评论数据放在地图上,显示区域集中情况,首先需要将城市信息转化为坐标信息,这个时候需要用到高德地图的API插口。而为了减少反复查询的次数,需要对坐标信息进行存储,即将位置数据存储在sql中,逻辑是这样:</p>
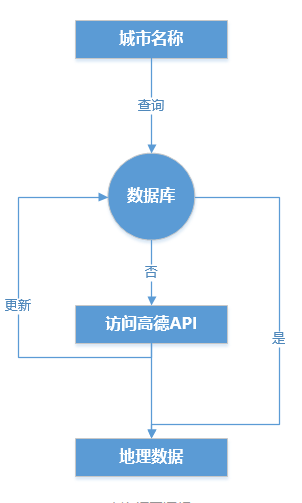
查询框图逻辑
<p>采用sqlite进行地理数据的存储和查询,对于查询存在的数据直接输出,查询不存在的数据需要通过高德地图的行政区域查询功能查询。首先需要注册自己的一个key,并在对应账号的控制版内增加Web服务API功能,使用过程中将key值以及设置信息用dict格式表示,并加载在requests的param中。查询输出的数据格式有两种,一种是json,一种是xml。这里输出json,对json的字符串通过正则表达式将经纬度信息提取出来,提取出后存储在数据文件中,并进行输出。 </p>
def getCenter(city):
conn = sqlite3.connect('citydata.db')
cursor = conn.cursor()
cursor.execute("CREATE TABLE IF NOT EXISTS CITYDATA(citycode text primary key , name text, latitude real, longitude real);")
cursor.execute("SELECT latitude, longitude FROM CITYDATA WHERE name = ?", (city,))
res = cursor.fetchall() if not res:
payload = { ##yourkey = the key applied from amap.com
'key':yourkey,'keywords':'', 'subdistrict': '0','showbiz':False,'output':'json',
}
payload['keywords'] = city
jsonData = requests.get('http://restapi.amap.com/v3/config/district?', params = payload)
jsonText = jsonData.text
center = re.search(r'\"([\d]*\.[\d]*)\,([\d]*\.[\d]*)\"', jsonText)
cityCode = re.search(r'\"citycode\"\:\"(\d*)\"', jsonText)
latitude = float(center.group(1))
longitude = float(center.group(2))
cursor.execute("INSERT INTO CITYDATA VALUES(?, ?, ?, ?);", [cityCode.group(1), city, latitude, longitude])
cursor.close()
conn.commit() return latitude, longitude else:
res = list(res[0]) return res[0], res[1]<p>经纬度数据获得后,需要输出到现有的dataFrame中,由于上述函数有两个输出,不能通过apply函数得出,需要结合zip以及map函数来实现双输出:</p>
neededData['latitude'], neededData['longitude'] = zip(*neededData['item_loc'].map(getCenter))
数据可视化
<p>dataFrame的可视化工具有很多,常用的有matplotlib。但对于生成地理信息图,似乎plotly更具有优势,并且经过优化后,plotly生成的图像质量要更高。尝试下对view_sales列进行可视化操作,首先对该列进行排序:</p>
neededData.sort_values('view_sales', axis = 0, ascending = False, inplace=True)<p>plotly在第一次使用的时候也需要设置自己的账号信息,具体可以参考getting started,本机只要设置过一次账号后,后面就可以不用再设置了。</p>
<p>首先需要对图例进行设置:</p>
import plotly.plotly as py length = len(newData) limits = [(0, int(0.05*length)),(int(0.05*length), int(0.2*length)),(int(0.2*length),int(0.5*length)),(int(0.5*length),length)] colors = ["#0A3854","#3779A3", "#1B85C6", "#C0DAEA"] cities = []
<p>而后就是设置每个点的地理信息、泡泡面积大小、泡泡颜色,并将dataFrame中的数据转换为ployly可识别的格式中:</p>
for i in range(len(limits)):
lim = limits[i]
df_sub = newData[lim[0]:lim[1]]
city = dict( type = 'scattergeo',
locationmode = 'china',
lon = df_sub['longitude'],
lat = df_sub['latitude'],
text = df_sub['nick'],
marker = dict(
size = df_sub['view_sales']/10,
color = colors[i],
line = dict(width = 0.5, color = '#000'),
sizemode = 'area',
opacity = 0.5
),
name = "{0} - {1}".format(lim[0], lim[1])
)
cities.append(city)<p>最后是对图纸信息进行设定,包括标题,是否显示图例。由于ployly中已经包含有地图信息,因此只需设定显示区域(scope),投影方式(projection),以及边界线条颜色和边界信息即可:</p>
layout = dict( title = Keyword + "的淘宝分布", showlegend = True, geo = dict( scope = "asia", projection = dict(type = 'mercator'), showland = True, landcolor = 'rgb(217, 217, 217)', subunitwidth=1, countrywidth=1, subunitcolor="rgb(255, 255, 255)", countrycolor="rgb(255, 255, 255)", lonaxis = dict(range = [newData['longitude'].min()-3, newData['longitude'].max() + 3]), lataxis = dict(range = [newData['latitude'].min()-0.5, newData['latitude'].max() + 0.5]), ), )
<p>完成后,输出保存即可:</p>
fig = dict(data = cities, layout = layout) py.iplot(fig, validate = False)
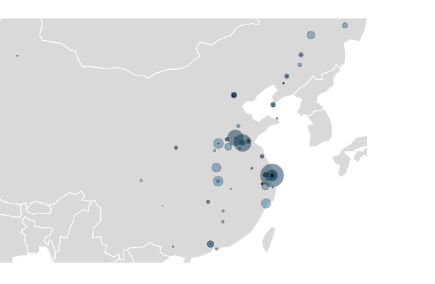
脱皮绿豆的淘宝分布
总结
<p>本文基本实现了最初目的,模拟了淘宝的搜索数据,并初步对数据进行可视化。但该程序还有很多优化的地方:</p>
在搜索过程中,发现对于同一个关键词会出现很多不同种类的东西,例如你搜索苹果,可能会出现iphone也有可能出现能吃的苹果,不方便;
结合ML,实现深度的搜索,对同一个物品进行价格对比,销量对比,客户评价对比,帮助客户进行选择;
可视化的意义没有体现出来;
本文中,还有bug未完善,很多地方需要采用try来规避。
作者:Garfield_Liang
链接:https://www.jianshu.com/p/9a9468d6d3ec
共同学习,写下你的评论
评论加载中...
作者其他优质文章



