

图片由作者提供
感谢 John Gilhuly 对本文的贡献。
代理正在迎来一个高光时刻。随着多个新框架的出现以及该领域的投资,现代AI代理正在克服不稳定的起源,迅速取代RAG成为实施的首要任务。那么,2024年是否会最终成为自主AI系统接管我们写邮件、预订航班、与数据交互或几乎任何其他任务的一年呢?
也许可以,但要达到那个阶段还有很多工作要做。任何开发人员构建代理时不仅需要选择基础——选择使用哪种模型、用例和架构,还需要选择使用哪个框架。你是选择历史悠久的 LangGraph,还是选择新出现的 LlamaIndex Workflows?或者你选择传统的自己编写整个代理?
本文旨在让这一选择变得更容易。在过去几周里,我在主要框架中构建了相同的代理,以从技术层面考察每个框架的一些优缺点。每个代理的代码都可在 此仓库 中找到。
关于用于测试的代理的背景信息用于测试的代理包括函数调用、多个工具或技能、与外部资源的连接以及共享状态或内存。
代理具有以下能力:
- 从知识库中回答问题
- 与数据对话:回答有关LLM应用的遥测数据的问题
- 分析数据:分析检索到的遥测数据中的高层次趋势和模式
为了完成这些任务,代理拥有三种初始技能:使用产品文档进行检索和生成(RAG)、在跟踪数据库上生成SQL查询以及数据分析。代理的用户界面使用了一个简单的Gradio界面,而代理本身则被构建为一个聊天机器人。
基于代码的代理(无框架)当你开发一个代理时,第一个选项是完全跳过框架,自己从头开始构建代理。在开始这个项目时,我就是采取了这种方法。

作者创建的图像
纯代码架构下面的代码代理由一个由 OpenAI 提供支持的路由器组成,该路由器使用函数调用来选择合适的技能。在该技能完成后,它会返回到路由器,以调用另一个技能或响应用户。
代理保持一个持续的消息和响应列表,在每次调用时将其完整传递给路由器以通过周期保留上下文。
def router(messages):
if not any(
isinstance(message, dict) and message.get("role") == "system" for message in messages
):
system_prompt = {"role": "system", "content": SYSTEM_PROMPT}
messages.append(system_prompt)
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=skill_map.get_combined_function_description_for_openai(),
)
messages.append(response.choices[0].message)
tool_calls = response.choices[0].message.tool_calls
if tool_calls:
handle_tool_calls(tool_calls, messages)
return router(messages)
else:
return response.choices[0].message.content技能本身是在它们自己的类中定义的(例如 GenerateSQLQuery),这些类共同存储在一个 SkillMap 中。路由器本身只与 SkillMap 交互,使用它来加载技能名称、描述和可调用函数。这种做法意味着向代理添加新技能只需将该技能定义为自己的类,然后将其添加到 SkillMap 中的技能列表中即可。这里的想法是让添加新技能变得简单,而不会干扰路由器代码。
class SkillMap:
def __init__(self):
skills = [AnalyzeData(), GenerateSQLQuery()]
self.skill_map = {}
for skill in skills:
self.skill_map[skill.get_function_name()] = (
skill.get_function_dict(),
skill.get_function_callable(),
)
def get_function_callable_by_name(self, skill_name) -> Callable:
return self.skill_map[skill_name][1]
def get_combined_function_description_for_openai(self):
combined_dict = []
for _, (function_dict, _) in self.skill_map.items():
combined_dict.append(function_dict)
return combined_dict
def get_function_list(self):
return list(self.skill_map.keys())
def get_list_of_function_callables(self):
return [skill[1] for skill in self.skill_map.values()]
def get_function_description_by_name(self, skill_name):
return str(self.skill_map[skill_name][0]["function"])总体而言,这种方法实现起来相当直接,但也带来了一些挑战。
纯代码代理的挑战第一个困难在于构建路由器系统提示。在上面的例子中,路由器经常坚持自己生成SQL,而不是将这个任务委托给正确的技能。如果你曾经尝试让一个大语言模型(LLM)不做某件事,你就会知道这种经历有多么令人沮丧;找到一个有效的提示需要经过多轮调试。考虑到每个步骤的不同输出格式也很棘手。由于我没有选择使用结构化输出,我必须准备好从我的路由器和技能中的每次LLM调用中接受多种不同的格式。
Pure代码代理的优势基于代码的方法提供了一个很好的基准和起点,为学习代理如何工作提供了一种很好的方式,而无需依赖主流框架中的预设代理教程。尽管说服LLM按预期行为可能具有挑战性,但代码结构本身足够简单,易于使用,并且可能适用于某些用例(更多分析见下文)。
LangGraphLangGraph 是最早期的代理框架之一,首次发布于2024年1月。该框架通过采用 Pregel 图结构来解决现有管道和链路的非循环特性问题。LangGraph 通过引入节点、边和条件边的概念,使得在代理中定义循环变得更加容易。LangGraph 基于 LangChain 构建,并使用该框架的对象和类型。

作者创建的图像
LangGraph 架构LangGraph 代理在纸面上看起来与基于代码的代理相似,但其背后的代码却大不相同。LangGraph 仍然在技术上使用了一个“路由器”,它通过调用 OpenAI 的函数并使用响应来继续到新的步骤。然而,程序在技能之间移动的方式完全由不同的方式控制。
tools = [generate_and_run_sql_query, data_analyzer]
model = ChatOpenAI(model="gpt-4o", temperature=0).bind_tools(tools)
def create_agent_graph():
workflow = StateGraph(MessagesState)
tool_node = ToolNode(tools)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.add_edge(START, "agent")
workflow.add_conditional_edges(
"agent",
should_continue,
)
workflow.add_edge("tools", "agent")
checkpointer = MemorySaver()
app = workflow.compile(checkpointer=checkpointer)
return app在这里定义的图有一个节点用于初始的 OpenAI 调用,称为“agent”,还有一个节点用于工具处理步骤,称为“tools”。LangGraph 内置了一个名为 ToolNode 的对象,它接受一个可调用工具的列表,并根据 ChatMessage 响应触发这些工具,在返回到“agent”节点之前执行此操作。
def should_continue(state: MessagesState):
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return END
def call_model(state: MessagesState):
messages = state["messages"]
response = model.invoke(messages)
return {"messages": [response]}在每次调用“agent”节点(换句话说:代码中的路由器)之后,should_continue 边决定是否将响应返回给用户或传递给 ToolNode 处理工具调用。
在整个每个节点中,“状态”存储了来自 OpenAI 的消息和响应列表,类似于代码基代理的方法。
LangGraph 面临的挑战在示例中,LangGraph 大多数问题源于需要使用 Langchain 对象以使流程顺畅。
挑战 #1:函数调用验证
为了使用 ToolNode 对象,我不得不重构了大部分现有的 Skill 代码。ToolNode 接受一个可调用函数的列表,这原本让我以为可以使用我现有的函数,然而由于我的函数参数问题,导致无法正常工作。
这些技能被定义为带有可调用成员函数的类,这意味着它们的第一个参数是“self”。尽管GPT-4o足够聪明,不会在生成的函数调用中包含“self”参数,但LangGraph却将其视为由于缺少参数而产生的验证错误。
这花了好几个小时才解决,因为错误信息标记的是函数中的第三个参数(在数据分析技能中是“args”参数)为缺失的参数:
pydantic.v1.error_wrappers.ValidationError: 1 个验证错误,data_analysis_toolSchema 中的 args 字段是必需的 (类型=value_error.missing)值得一提的是,错误消息来源于 Pydantic,而不是 LangGraph。
我最终下定决心,使用 Langchain 的 @tool 装饰器重新定义了我的技能为基本方法,并成功让它们运行起来。
@tool
def 生成并运行SQL查询(query: str):
"""根据提示生成并运行一个SQL查询。
参数:
query (str): 包含原始用户提示的字符串。
返回:
str: SQL查询的结果。
"""挑战 #2:调试
如前所述,在框架中进行调试是困难的。这主要归因于令人困惑的错误消息和抽象的概念,这些使得查看变量更加困难。
抽象的概念主要出现在尝试调试代理之间发送的消息时。LangGraph 将这些消息存储在 state[“messages”] 中。图中的某些节点会自动从这些消息中提取信息,这使得当节点访问这些消息时,理解消息的价值变得困难。

代理执行动作的顺序视图(作者提供图片)
LangGraph 优势LangGraph 的一个主要优点是它易于使用。图结构代码清晰且易于访问。特别是如果你有复杂的节点逻辑,有一个单一的图视图可以更容易地理解代理是如何连接在一起的。LangGraph 还使得将现有的 LangChain 构建的应用程序转换过来变得简单直接。
精华如果你使用框架中的所有功能,LangGraph 将运行得非常顺畅;如果你超出框架范围使用,则需要做好调试的准备,可能会遇到一些头疼的问题。
LlamaIndex 工作流Workflows 是最近进入代理框架领域的新成员,今年夏天早些时候首次亮相。与 LangGraph 一样,它旨在使循环代理更容易构建。Workflows 还特别注重异步运行。
一些 Workflows 的元素似乎直接回应了 LangGraph,特别是它使用事件而不是边和条件边。Workflows 使用步骤(类似于 LangGraph 中的节点)来容纳逻辑,并通过发出和接收事件在步骤之间移动。

作者创建的图像
上述结构与 LangGraph 结构类似,唯一的区别是我向工作流中添加了一个设置步骤,以准备代理上下文,详情请见下文。尽管结构相似,但驱动它的代码却大不相同。
工作流架构下面的代码定义了工作流的结构。类似于 LangGraph,这里我准备了状态并将技能附加到了 LLM 对象上。
class AgentFlow(Workflow):
def __init__(self, llm, timeout=300):
super().__init__(timeout=timeout)
self.llm = llm
self.memory = ChatMemoryBuffer(token_limit=1000).from_defaults(llm=llm)
self.tools = []
for func in skill_map.get_function_list():
self.tools.append(
FunctionTool(
skill_map.get_function_callable_by_name(func),
metadata=ToolMetadata(
name=func, description=skill_map.get_function_description_by_name(func)
),
)
)
@step
async def prepare_agent(self, ev: StartEvent) -> RouterInputEvent:
user_input = ev.input
user_msg = ChatMessage(role="user", content=user_input)
self.memory.put(user_msg)
chat_history = self.memory.get()
return RouterInputEvent(input=chat_history)这也是我定义的一个额外步骤,“prepare_agent”。这个步骤从用户输入中创建一个 ChatMessage 并将其添加到工作流内存中。将这个步骤单独拆分出来意味着,在代理循环遍历步骤时,我们不会重复将用户消息添加到内存中。
在 LangGraph 的情况下,我通过在图外部使用 run_agent 方法实现了相同的功能。虽然这种变化主要是风格上的,但我认为将此逻辑与工作流和图一起封装会更干净。
在工作流设置完成后,我定义了路由代码:@步骤
async def 路由器(self, ev: RouterInputEvent) -> ToolCallEvent | StopEvent:
消息 = ev.input
如果 not any(
isinstance(消息, dict) and 消息.get("role") == "system" for 消息 in 消息
):
系统提示 = ChatMessage(role="system", content=SYSTEM_PROMPT)
消息.insert(0, 系统提示)
with 使用提示模板(template=SYSTEM_PROMPT, version="v0.1"):
响应 = await self.llm.achat_with_tools(
model="gpt-4o",
messages=消息,
tools=self.tools,
)
self.内存.put(响应.message)
工具调用 = self.llm.get_tool_calls_from_response(响应, error_on_no_tool_call=False)
如果 工具调用:
返回 ToolCallEvent(tool_calls=工具调用)
否则:
返回 StopEvent(result=响应.message.content)
处理工具调用的代码:@step
async def tool_call_handler(self, ev: ToolCallEvent) -> RouterInputEvent:
tool_calls = ev.tool_calls
for tool_call in tool_calls:
function_name = tool_call.tool_name
arguments = tool_call.tool_kwargs
if "input" in arguments:
arguments["prompt"] = arguments.pop("input")
try:
function_callable = skill_map.get_function_callable_by_name(function_name)
except KeyError:
function_result = "Error: 未知的函数调用"
function_result = function_callable(arguments)
message = ChatMessage(
role="tool",
content=function_result,
additional_kwargs={"tool_call_id": tool_call.tool_id},
)
self.memory.put(message)
return RouterInputEvent(input=self.memory.get())
这两个都更类似于基于代码的代理,而不是 LangGraph 代理。主要是因为 Workflows 将条件路由逻辑保留在步骤中,而不是在条件边中——第 18 到 24 行在 LangGraph 中是一个条件边,而现在它们只是路由步骤的一部分——以及 LangGraph 具有一个 ToolNode 对象,该对象在 tool_call_handler 方法中几乎自动完成了所有工作。
经过路由步骤之后,让我非常高兴的是,我可以使用我的 SkillMap 和代码代理中的现有技能与 Workflows 一起使用。这些技能无需任何更改即可与 Workflows 一起工作,这使我的工作变得更加轻松。
## 工作流面临的挑战
**挑战 #1:同步 vs 异步**
虽然异步执行对于实时代理来说更可取,但调试同步代理要容易得多。Workflows 设计为异步执行,试图强制执行同步执行非常困难。
我最初以为只要去掉“async”方法的标记,并将“achat_with_tools”改为“chat_with_tools”就可以了。然而,由于Workflow类中的底层方法也被标记为异步,因此需要重新定义这些方法以实现同步运行。最终我还是采用了异步方法,但这并没有让调试变得更加困难。
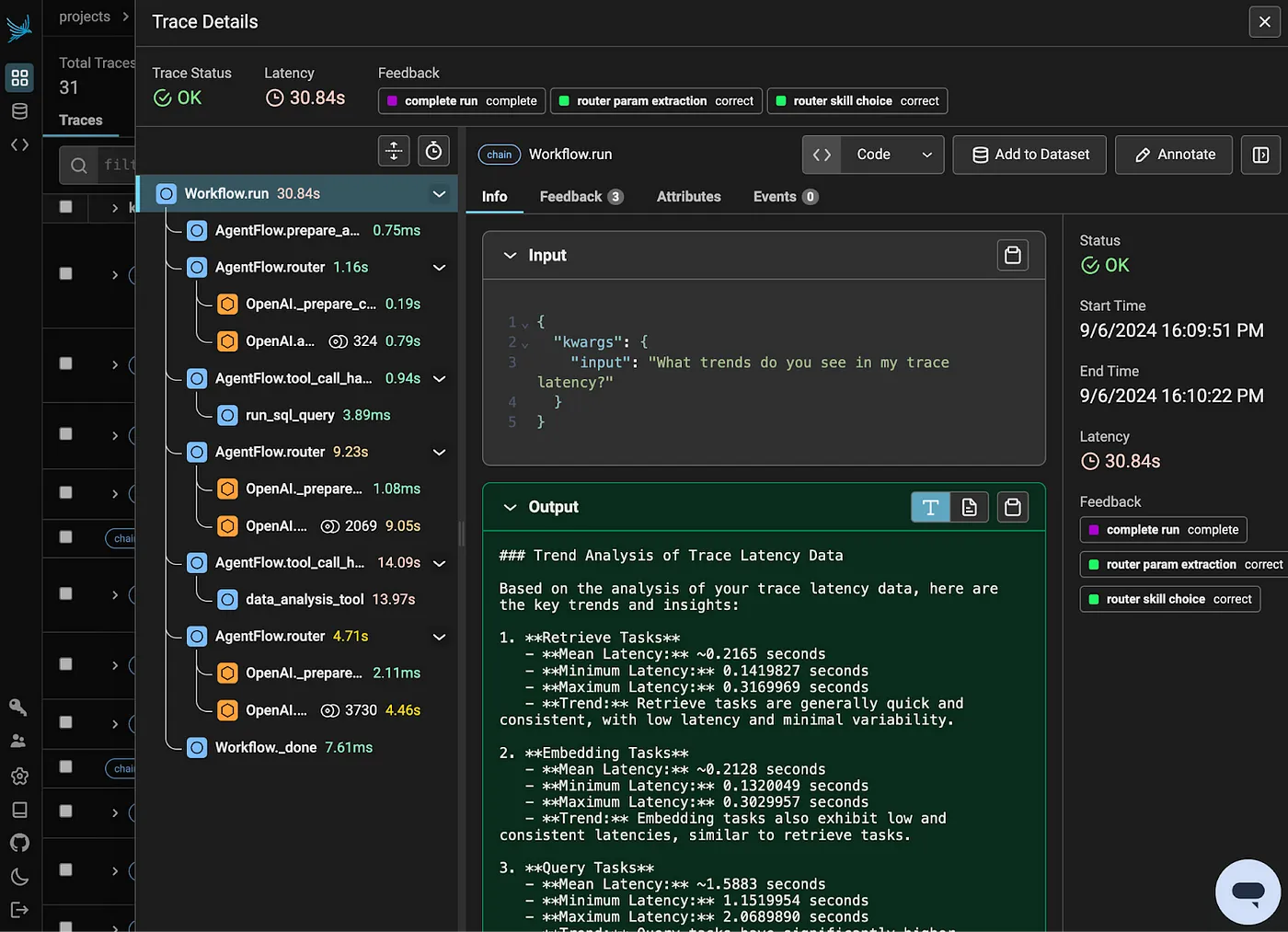
_代理执行动作的顺序视图(作者提供图片)_
**挑战 #2:Pydantic 验证错误**
在 LangGraph 遇到的问题重演中,类似的问题再次出现在技能的 Pydantic 验证错误上。幸运的是,这次这些问题更容易解决,因为 Workflows 能够很好地处理成员函数。最终,我只是需要在为我的技能创建 LlamaIndex FunctionTool 对象时更加明确:for func in skill_map.get_function_list():
self.tools.append(FunctionTool(
skill_map.get_function_callable_by_name(func),
metadata=ToolMetadata(name=func, description=skill_map.get_function_description_by_name(func))))
_摘自 AgentFlow.__init__ 中构建 FunctionTools 的内容_
## Workflows 的优势
我构建Workflows代理比构建LangGraph代理要容易得多,主要是因为Workflows仍然需要我自己编写路由逻辑和工具处理代码,而不是提供内置功能。这也意味着我的Workflow代理看起来与我的基于代码的代理非常相似。
最大的区别在于事件的使用。我使用了两个自定义事件来在代理的不同步骤之间进行切换:class ToolCallEvent(Event):
tool_calls: list[ToolSelection]
class RouterInputEvent(Event):
input: list[ChatMessage]
发射器-接收器、事件驱动的架构取代了我代理中直接调用的一些方法,比如工具调用处理器。
如果你有更复杂的系统,包含多个异步触发的步骤并且可能会发出多个事件,这种架构就变得非常有助于干净地管理这些情况。
Workflows 的其他优点包括它非常轻量级,并且不会强制你使用过多的结构(除了使用某些 LlamaIndex 对象之外),并且其基于事件的架构为直接函数调用提供了一个有帮助的替代方案——特别是对于复杂、异步的应用程序来说尤其如此。
# 比较框架
从这三种方法来看,每一种都有其优势。
无框架的方法是最简单的实现方式。因为所有的抽象都是由开发者定义的(例如上面示例中的 SkillMap 对象),所以保持各种类型和对象的清晰度很容易。然而,代码的可读性和可访问性完全取决于个人开发者,可以很容易地看到,如果没有一些强制性的结构,越来越复杂的代理可能会变得混乱。
LangGraph 提供了相当多的结构,这使得代理非常清晰地定义。如果一个更广泛的团队正在合作开发一个代理,这种结构将提供一种有助于强制执行架构的方法。对于那些不太熟悉结构的人来说,LangGraph 也可能是一个很好的起点。然而,这也存在权衡——由于 LangGraph 为你做了很多事情,如果你不完全接受这个框架,可能会导致一些麻烦;代码可能非常整洁,但你可能会为此付出更多的调试时间。
Workflows 处于中间位置。基于事件的架构对于某些项目可能非常有帮助,而且在使用 LlamaIndex 类型方面要求较少,这为那些没有在整个应用程序中完全使用框架的人提供了更大的灵活性。

作者创建的图像
最终,核心问题可能只是“你已经在使用LlamaIndex或LangChain来协调你的应用程序了吗?”LangGraph和Workflows都与其各自的基础框架紧密相连,因此每个特定框架的额外好处可能不足以让你仅仅因为这些好处而切换。
纯代码的方法很可能始终是一个有吸引力的选择。如果你有严谨性来记录和强制执行所创建的任何抽象,那么确保外部框架中的任何内容都不会拖慢你的速度就很容易了。
# 选择代理框架时的关键问题
当然,“视情况而定”这个答案总是不够令人满意的。这三个问题应该可以帮助你决定在下一个代理项目中使用哪个框架。
**_您已经在项目中使用 LlamaIndex 或 LangChain 来处理重要部分了吗?_**
如果可以,首先探索那个选项。
**_你熟悉常见的代理结构,还是希望有人告诉你应该如何构建你的代理?_**
如果你属于后者,可以尝试使用Workflows。如果你真的属于后者,可以尝试使用LangGraph。
**_您的代理之前构建过了吗?_**
其中一个框架的好处是,有许多使用该框架构建的教程和示例。相比之下,纯粹基于代码的代理构建示例要少得多。
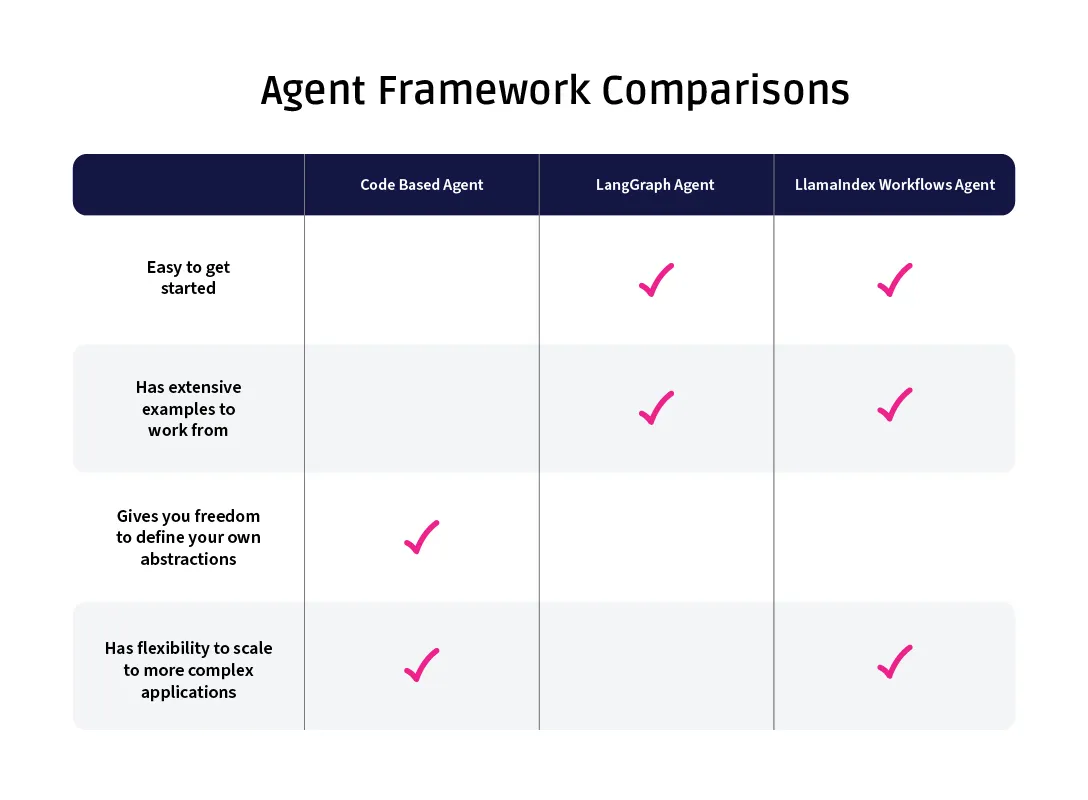
作者创建的图像
# 结论
选择一个代理框架只是影响生成式AI系统在生产环境中表现的众多选择之一。正如以往一样,拥有稳健的防护措施和[LLM跟踪](https://docs.arize.com/phoenix/tracing/llm-traces)非常重要——并且要保持敏捷,以应对新的代理框架、研究和模型所带来的挑战,这些都可能颠覆现有的技术。共同学习,写下你的评论
评论加载中...
作者其他优质文章



