 作者创建的图片。
作者创建的图片。
这最初发布于 https://vutr.substack.com .
目录
- 上下文与挑战
- 旧架构
- 新架构
- 评估
简介
几周前,我们了解了Uber如何处理他们的实时基础设施以每天处理数百万个事件。本周,我们将看到另一家大型科技公司如何处理实时数据处理需求:Twitter。
本文参考了Twitter的这篇博客;该博客发布于2021年,因此可能无法反映当前Twitter(X)的实时解决方案。
上下文和挑战
Twitter 每天实时处理 4000 亿个事件,并生成 1PB 的数据。这些事件来自多个来源,包括不同的平台和系统:Hadoop, Kafka, Google BigQuery, Google Cloud Storage, Google PubSub 等。为了应对大规模数据的处理,Twitter 建立了专为每个需求设计的内部工具:Scalding 用于批处理,Heron 用于流处理,TimeSeries AggregatoR 框架用于两者,以及 Data Access Layer 用于数据消费。
尽管该技术非常强大,数据的增长仍然给基础设施带来了压力;最突出的例子是交互和参与管道,该管道处理大规模的批处理和实时数据。此管道从各种实时流和服务器及客户端日志中收集和处理数据,以提取推文和用户交互数据,并进行多级聚合和指标维度的处理。此管道的聚合数据是Twitter广告收入和许多数据产品服务的唯一来源。因此,该管道必须确保低延迟和高准确性。让我们看看Twitter是如何处理这一任务的。
下面的部分描述了Twitter最初的互动和参与管道解决方案。
旧的架构
概览
作者创建的图片。 参考
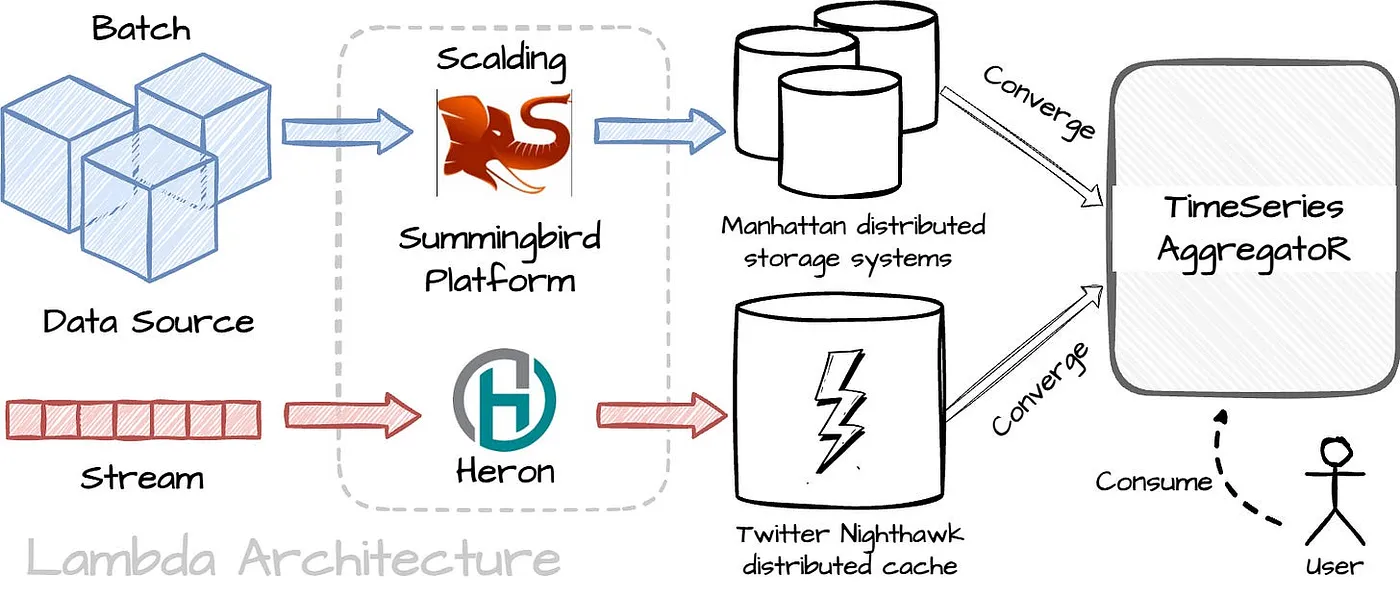
Twitter 使用 lambda 架构作为原始解决方案。有两个独立的管道:批处理管道,提供批数据的准确视图;实时流处理管道,提供在线数据的视图。这两个视图的输出将在每天结束时合并。Twitter 使用以下组件构建了该架构:
- Summingbird 平台:据我理解,这个平台包括多个分布式引擎,如 Scalding 和 Heron,以及一个允许用户定义 MapReduce 逻辑并在这些引擎上执行的专用库。
- TimeSeries AggregatoR:一个健壮且可扩展的实时事件时间序列聚合框架。
- 批处理:批处理管道的数据源可以来自日志、客户端事件或 HDFS 中的推文事件。有许多 Scalding 管道用于预处理原始数据,然后将其导入 Summingbird 平台。管道的结果将存储在 Manhattan 分布式存储系统中。为了节省成本,Twitter 将批处理管道部署在一个数据中心,并在其他两个数据中心中复制数据。
- 实时:实时管道的数据源来自 Kafka 主题。数据将“流”到 Summingbird 平台中的 Heron,然后 Heron 的结果将存储在 Twitter 的 Nighthawk 分布式缓存中。与批处理管道不同,实时管道部署在三个不同的数据中心。
- 在批处理和实时存储之上有一个查询服务。
挑战
由于实时数据的高规模和高吞吐量,可能会存在数据丢失和不准确的风险。如果处理速度跟不上事件流,反压将在Heron拓扑(有向无环图表示Heron的数据处理流程)中出现。当系统长时间处于反压状态时,Heron bolts(可以理解为工作者)会累积延迟,从而导致整个系统的延迟增加。
此外,许多Heron流管理器可能会由于背压而失败(流管理器管理拓扑组件之间的数据路由)。Twitter的解决方案是重启Heron容器以启动流管理器。然而,重启肯定会导致事件丢失,从而降低整个管道的准确性。
下面的部分描述了Twitter在意识到原有解决方案的局限性后提出的新解决方案。
新的架构
概览
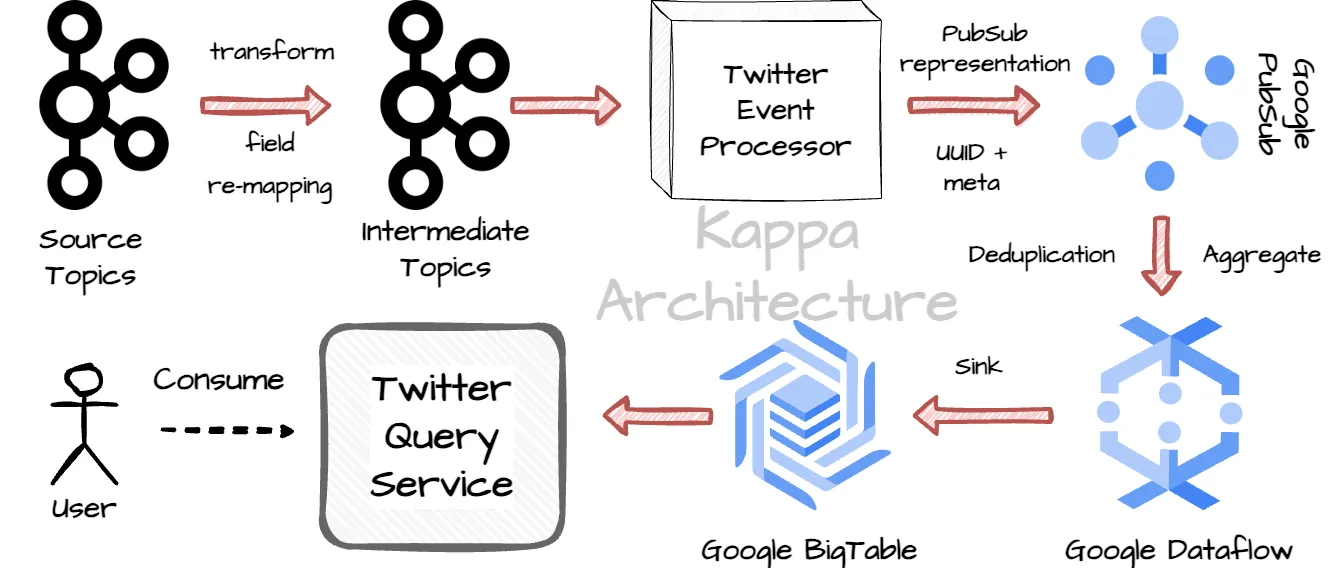
采用新方法后,Twitter 使用了 Kappa 架构来简化解决方案,仅使用一个实时管道。该架构将利用 Twitter 内部和 Google Cloud Platform 的解决方案:
新架构的流程可以这样描述:
- 步骤 1 : 它们从源 Kafka 主题中消费数据,进行转换和字段重映射,最后将结果发送到中间 Kafka 主题。
- 步骤 2 : 事件处理器将中间 Kafka 主题中的数据转换为 Pubsub 表示形式,并用 UUID(用于 Dataflow 中的去重)和一些与处理上下文相关的元信息装饰事件。
- 步骤 3: 事件处理器将事件发送到 Google Pubsub 主题。Twitter 几乎无限次重试以确保消息以至少一次的方式从数据中心发送到 Google Cloud。
- 步骤 4: Google Dataflow 作业将处理来自 PubSub 的数据。Dataflow 工作节点实时处理去重和聚合。
- 步骤 5: Dataflow 工作节点将聚合结果写入 BigTable。
评判标准
Twitter 对新架构的观察
新方法的成就
- 比起旧架构的10秒至10分钟的延迟,延迟保持稳定在~10秒。
- 实时管道可以实现高达1GB/s的吞吐量,而旧架构的最大吞吐量为100 MB/s。
- 感谢至少一次的数据发布到Google Pubsub以及Dataflow的去重工作,确保了几乎一次处理的准确性。
- 节省了构建批处理管道的成本。
- 实现了更高的聚合精度。
- 处理延迟事件的能力。
- 重启时无事件丢失。
他们是如何监控重复率的?
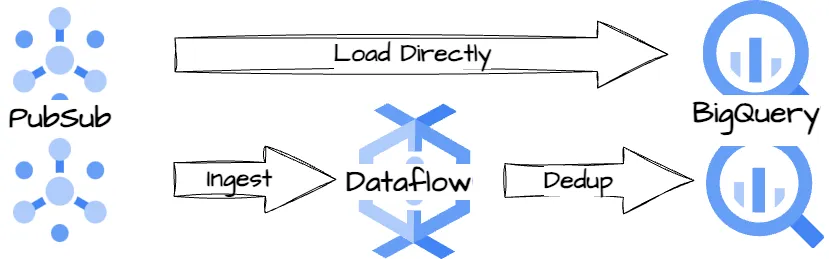
作者创建的图像。
Twitter 创建了两个独立的Dataflow管道:一个管道将原始数据直接从Pubsub路由到BigQuery,另一个管道将去重后的事件计数导出到BigQuery。这样,Twitter 可以监控重复事件的百分比以及去重后的百分比变化。
他们如何比较旧批处理管道与新Dataflow管道中的去重计数?
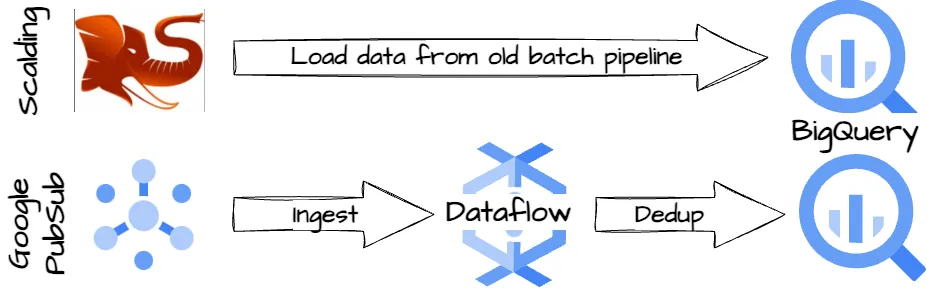
Image created by the author.
- 除了写入到BigTable之外,新的工作流还将去重和聚合后的数据导出到BigQuery。
- Twitter还将旧的批处理数据管道的结果加载到BigQuery。
- 他们运行计划查询来比较重复计数。
- 结果是,新的管道结果中有超过95%与旧的批处理管道结果完全匹配。5%的差异主要是因为原来的批处理管道会丢弃延迟事件,而新的管道可以高效地捕获这些事件。
结尾词
通过迁移到新的Kappa架构,Twitter在延迟和正确性方面相比旧架构有了显著的提升。新架构不仅性能更优,还简化了数据管道,使其仅保留了流处理部分。
下见下次博客。
注:此处的翻译更注重语感和习惯表达,“See you on the next blog.” 更自然的翻译应该是 “下次博客见。” 或 “敬请期待下一次的博客。” 但根据要求直接翻译,所以给出 “下见下次博客。” 作为答案。根据上下文调整为更自然的表达会更好。
参考资料
[1] 鲁章和楚克武迪托·马利费,实时处理数十亿事件的Twitter方法 (2021)
共同学习,写下你的评论
评论加载中...
作者其他优质文章